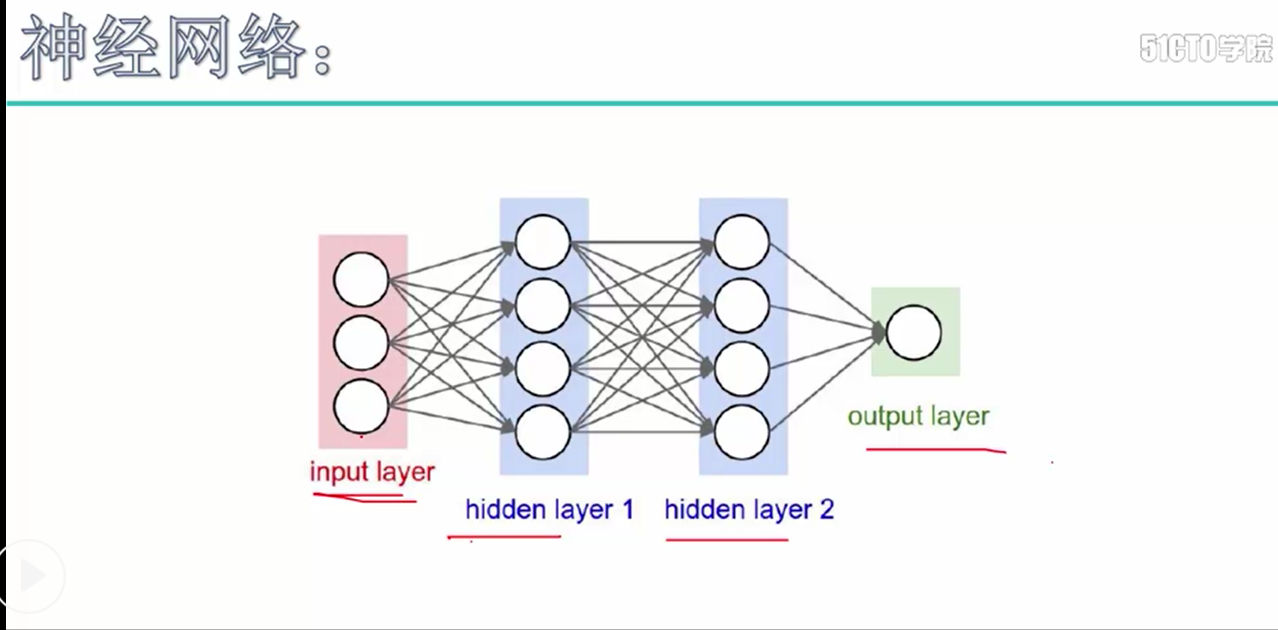
神经网络构架:主要时表示神经网络的组成,即中间隐藏层的结构
对图片进行说明:我们可以看出图中的层数分布:
input layer表示输入层,维度(N_num, input_dim) N_num表示输入层的样本个数, input_dim表示输入层的维度, 即变量的个数
hidden layer1 表示第一个隐藏层,维度(input_dim, hidden_dim1input_dim表示输入层的维度,hidden_dim1示隐藏层的维度
hidden layer2 表示第二个隐藏层,维度(hidden_dim1, num_classes) hidden_dim1表示隐藏层的维度, num_classes表示输出的样本的类别数
output layer 表示输出结果层, 维度(N_num, num_classes) N_num 表示输入层的样本个数, num_classes表示类别数,即每个样本对于的类别得分值
代码:对于隐藏层的参数w和b的初始化
self.params['W1'] = weight_scale * np.random.randn(input_dim, hidden_dim) self.params['b1'] = np.zeros((1, hidden_dim)) self.params['W2'] = weight_scale * np.random.randn(hidden_dim, num_classes) self.params['b2'] = np.zeros((1, num_classes))
2.激活函数讨论, 加入激活函数的目的是为了在分类过程中,使得分类的判别式是非线性的方程即: f = σ(w*x+b) , σ表示非线性激活函数
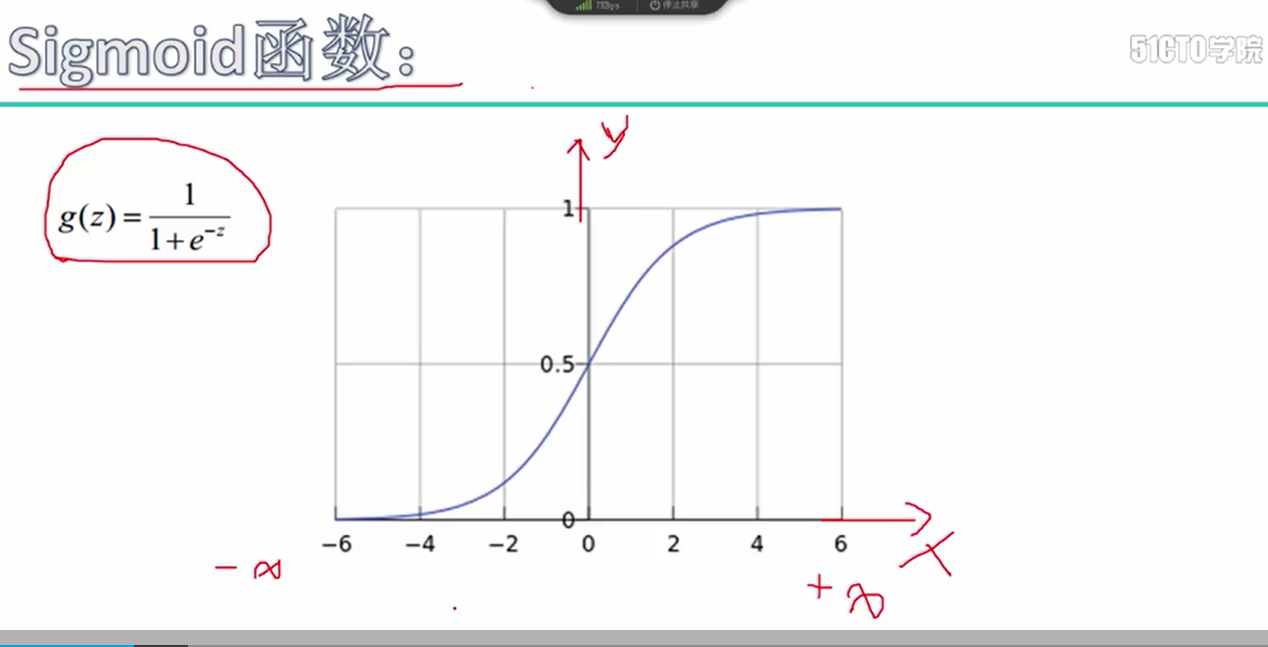
但是对于sigmoid激活函数存在一个问题,即在进行梯度回传时,存在一个问题,即容易发生梯度消失的问题, (1-σ(x)) * σ(x) σ(x) 表示经过sigmoid变化后的输入结果
当x值较大时, dσ / dx 的梯度值较小,即根据链式法则,每次都乘以较小的梯度值,因此到最后就容易出现梯度消失的情况
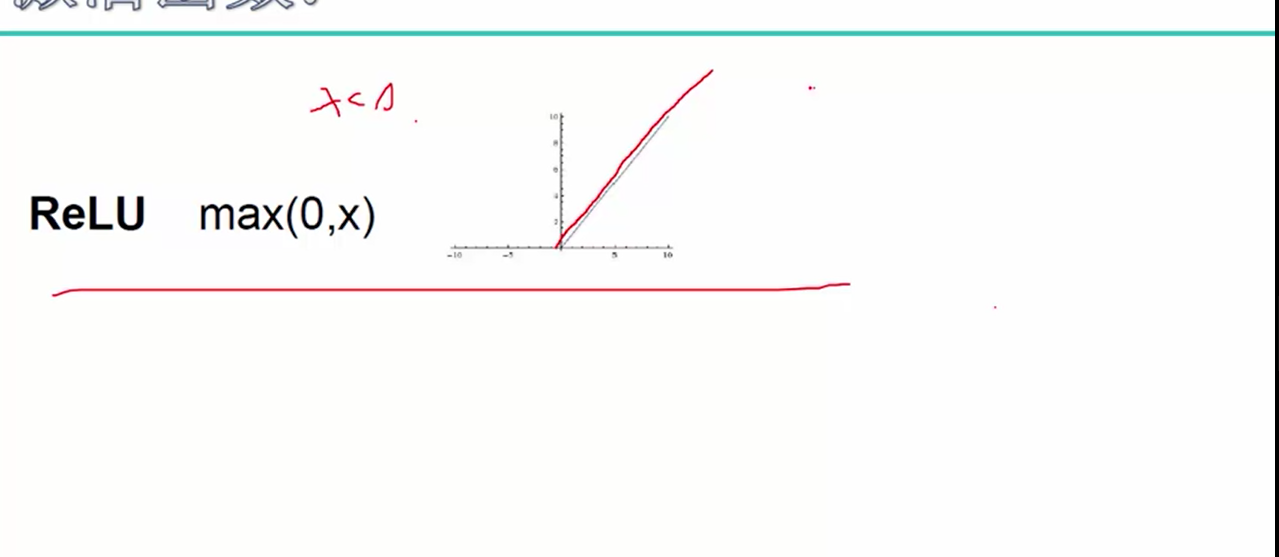
对于ReLU激活函数的梯度回传,进行求导时,当输入值X小于0时,回传值为0, 当输入值大于等于0时,回传值即是本身,因此激活函数本身不会造成梯度消失问题
代码:
x = cache
dout[x < 0] = 0
3. 数据预处理, 即对输入的图片,对每张图片减去均值,在除以标准差的操作
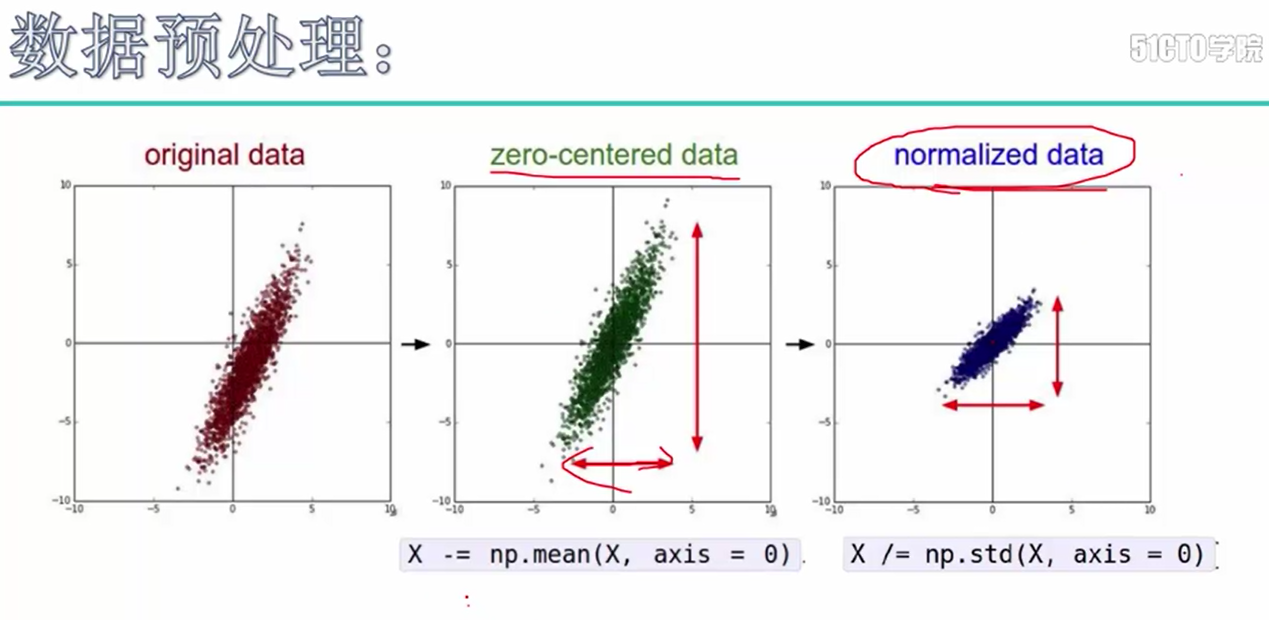
代码:
# 对图片做平均操作 mean_img = np.mean(X_train, axis=0, keepdims=True) X_train -= mean_img X_val -= mean_img X_test -= mean_img
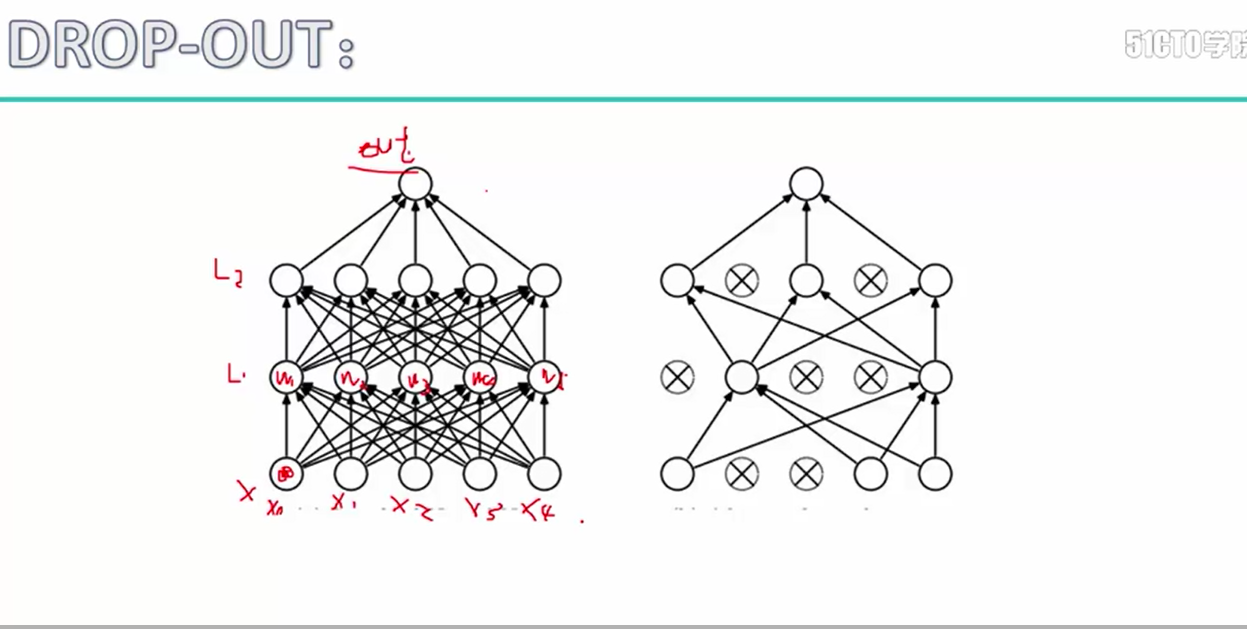
4. dropout,关闭中间的几个隐藏层表示不进行参数的更新操作