1. tf.reuse_default_graph() # 对graph结构图进行清除和重置操作
2.tf.summary.FileWriter(path)构造writer实例化,以便进行后续的graph写入
参数说明:path表示路径
3.writer.add_graph(sess.graph) 将当前参数的graph写入到tensorboard中
参数说明:sess.graph当前的网络结构图
4. summ = tf.summary.merge_all() # 将所有的summary都添加
5. writer.add_summary(s) 将所有的summary写入到tensorboard中
参数说明:s为sess.run(summ)
6.tf.summary.image(‘input’, x_image,3) # 在summary中添加图片
参数说明:‘input’表示名称,x_image表示输入图片,3表示取3张图片
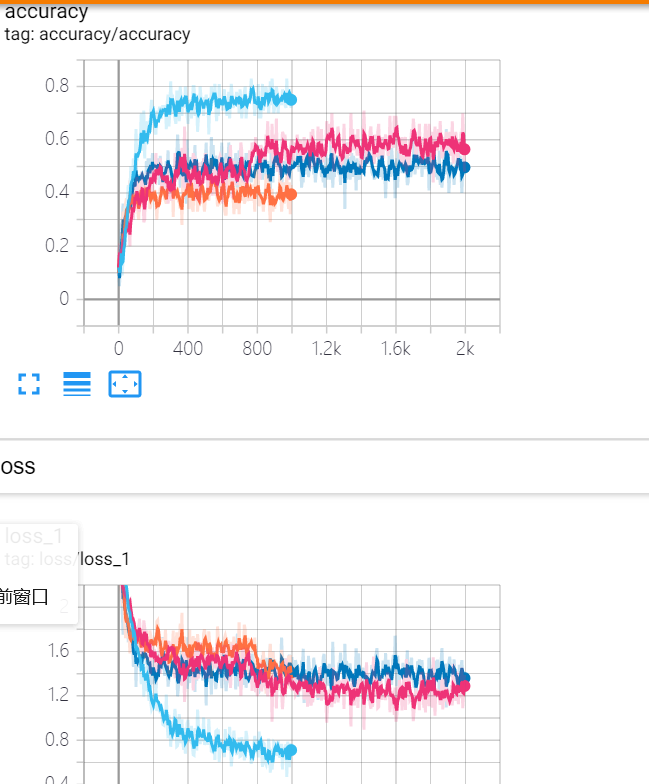
7.tf.summary.scalar('loss', loss) # 在summary中添加迭代的曲线图
参数说明:‘loss’为图的名称,loss为实际损失值
8.tf.summary.histgram('weights', w) # 在summary中添加权重参数w的分布图
参数说明:‘weights’为图的名称,w为参数值
代码说明:这里主要是分为两部分进行探讨,第一部分是对各个参数指标的画图,第二部分是对比不同的参数组合所能达到的效果
数据说明:使用的是mnist数据集,即mnist.train.next_batch
参数说明:传入的参数包括学习率,是否使用两层卷积,是否使用两层全连接,以及保存的名字
第一部分代码说明:
使用tf.variable_scope(name): 指定范围,然后再定义参数w和b,这样的话画出来的图像更加的清楚
使用tf.summary.histogram(‘weight’, w) # 画出参数的柱状图
使用tf.summary.image('input', x_image, 3) # 画出前三个图像的样子
使用tf.summary.scalar('loss', loss) # 画出变化趋势的折线图
使用tf.summary.merge_all() 在tensorboard中显示所有的信息
第一步:使用input_data.read_data_sets('/data', one_hot=True) 读取mnist数据集
第二步:构造main函数,对学习率,use_two_conv, use_two_fc进行循环
第三步:构造make_hparam_string用于构造learning,use_two_conv,use_two_fc的字符串,以便作为tensorbord文件的basename
第一步:conv_param = 'conv=2' if use_two_conv else 'conv=1' 将True或者False转换为字符串格式
第二步:fc_param = 'fc=2' if use_two_fc else 'fc=1' 将True或者False转换为字符串格式
第三步:‘lr_%.0E,%s,%s’%(learning, conv_param, fc_param), 将串接的结果返回
第四步:构建网络mnist_model,将学习率,use_two_conv, use_two_fc, hparam传入
第一步:使用tf. reuse_default_graph() 清除和重置默认图形
第二步:使用tf.Session() 构造sess
第三步:使用tf.placeholder(tf.float32, [None, 784], name='x') 初始化输入x,同时使用tf.reshape(x, [-1, 28, 28, 1]) 重构输入x的维度, 这里使用tf.summary.image('input', x_image, 3) #展示前3个图片,再使用tf.placeholder(tf.float32, [None, 10], name='labels') 构造y
第四步:if use_two_conv: 判断是进行二层卷积还是一层卷积
调用conv_layer(x, 1, 32, name='conv_1')构造第一层卷积层
调用conv_layer(conv_1, 32, 64, name='conv_2') 构造第二层卷积层
else:
调用conv_layer(x, 1, 64, name='conv') 构造第一层卷积层
使用tf.nn.max_pool(conv, ksize=[1, 2, 2, 1], strides=[1, 2, 2, 1], padding='SAME' ) # 进行降维操作,
为了保证不管是哪种情况,操作完以后的维度是相同的,都是-1, 7,7,64
第五步:将卷积后的特征图片进行维度的变化,变化为[-1, 7*7*64]
第六步:if use_two_fc: 判断是进行二层全连接还是一层全连接
调用fc_layer(x, 7*7*64, 1024, name='fc_1') # 构造第一层全连接
调用logits = fc_layer(fc_1, 1024, 10, name='fc_2') # 构造第二层全连接
else:
调用fc_layer(x, 7*7*64, 10, name='fc') # 构造一层全连接层
第七步:使用with tf.variable_scope('loss') 来定义loss的范围,使用tf.reduce_mean(tf.nn.softmax_cross_entropy_with_logits(labels=y, logits=logits)) 来定义损失值, 使用tf.summary.scalar('loss', loss) # 画出曲线loss的折线图
第八步:使用tf.train. Adaoptimzer(learning_rate).minimize(loss) 梯度下降来降低损失值
第九步:with tf.variable_scope('accuracy') 定义准确率,使用tf.equal和tf.reduce_mean计算准确率,使用tf.summary.scalar() 画出准确率的折线图
第十步:使用summ = tf.summary.merge_all() 将上述的summary全部都加到tensorboard中
第十一步:使用sess.run(tf.global_variables_initializer()) 进行参数初始化操作
第十二步:定义tensorboard_dir, 使用tf.summary.FileWriter(tensorboard_dir + hparam) # 将sumary图像写入到当前文件夹下,writer.add_graph(sess.graph) #将graph添加到writer中
第十三步:进行迭代训练
第一步:使用mnist.train.next_batch获得数据集batch
第二步: 每迭代5次,就执行[accr, s] = sess.run([accuracy, summ]), 并使用writer.add_summary(s, i)
第三步:执行sess.run(train_op)
第五步:执行main()函数
import tensorflow as tf import numpy as np from tensorflow.examples.tutorials.mnist import input_data # 第一步数据导入 mnist = input_data.read_data_sets('/data', one_hot=True) #卷积层的构造 def conv_layer(input, inputS, outputS, name): # 在name的范围内进行操作 with tf.variable_scope(name): # 构造w的初始化矩阵,tf.Variable()维度为[5, 5, inputS, outputS] w = tf.Variable(tf.truncated_normal([5, 5, inputS, outputS], stddev=0.05), name='w') # 构造b的初始化矩阵,维度为[outputS] b = tf.Variable(tf.constant(0.1, shape=[outputS]), name='b') # 使用tf.nn.conv2d进行卷积操作 conv = tf.nn.conv2d(input, w, strides=[1, 1, 1, 1], padding='SAME') # 使用tf.nn.relu进行激活操作 act = tf.nn.relu(conv) # 使用tf.summary.histogram() 做参数分布直方图 tf.summary.histogram('weights', w) tf.summary.histogram('biases', b) tf.summary.histogram('activations', act) # 进行池化操作,返回结果 return tf.nn.max_pool(act, ksize=[1, 2, 2, 1], strides=[1, 2, 2, 1], padding='SAME') def fc_layer(input, inputS, outputS, name): with tf.variable_scope(name): w = tf.Variable(tf.truncated_normal([inputS, outputS], stddev=0.05), name='w') b = tf.Variable(tf.constant(0.1, shape=[outputS]), name='b') fc = tf.matmul(input, w) + b act = tf.nn.relu(fc) tf.summary.histogram('weights', w) tf.summary.histogram('biases', b) tf.summary.histogram('activations', act) return act # 将输入use_two_conv和use_two_fc转换为字符串, 并将转换后的字符串和learning_rate进行组合 def make_hparam_string(learning_rate, use_two_conv, use_two_fc): conv_param = 'conv=2' if use_two_conv else 'conv=1' fc_param = 'fc=2' if use_two_fc else 'fc=1' return 'lr_%.0E,%s,%s'%(learning_rate, conv_param, fc_param) # 构造mnist_model层 def mnist_model(learning_rate, use_two_conv, use_two_fc, hparam): # 使用tf.reset_default_graph() 进行graph的清除和重置操作 tf.reset_default_graph() # 使用tf.Session() 构造执行函数sess sess = tf.Session() # 使用tf.placeholder() 构造初始化输入 x = tf.placeholder(tf.float32, [None, 784], name='x') # 将x进行维度的变化以便进行后续的卷积操作 x_images = tf.reshape(x, [-1, 28, 28, 1]) # 在tf.summary.image在tensorboard画出前3副图 tf.summary.image('input', x_images, 3) # 使用tf.placeholder()构造y的初始化输入 y = tf.placeholder(tf.float32, [None, 10], name='labels') # 如果使用两个卷积层 if use_two_conv: # 构造第一层卷积,输入为x,1为channel,32为输出的num_filter, name表示名字 conv_1 = conv_layer(x_images, 1, 32, name='conv_1') # 构造第二层卷积,输入为conv_1, 32为channel, 64为输出的num_filter, name表示名字 conv_out = conv_layer(conv_1, 32, 64, name='conv_2') else: # 构造第一层卷积层,输入为x_images, 1为channel, 64为输出w的num_filter通道数,name表示名字 conv_1 = conv_layer(x_images, 1, 64, name='conv') # 直接进行池化操作,降低矩阵的维度,为了与二次卷积的维度相同 conv_out = tf.nn.max_pool(conv_1, ksize=[1, 2, 2, 1], strides=[1, 2, 2, 1], padding='SAME') # 对池化的矩阵进行维度的变化,维度转换为[-1, 7*7*64] fcIn = tf.reshape(conv_out, [-1, 7*7*64]) # 使用二层全连接层 if use_two_fc: # 进行第一层全连接层,w的维度是7*7*64, 1024, name表示名字 fc_1 = fc_layer(fcIn, 7*7*64, 1024, name='fc_1') # 进行第二层全连接层,w的维度是1024, 10, name表示名字 logits = fc_layer(fc_1, 1024, 10, name='fc_2') else: # 只进行第一层全连接层,w的维度是7*7*64, 10, name表示名字 logits = fc_layer(fcIn, 7*7*64, 10, name='fc') # 将获得的得分计算损失值,tf.reduce_mean(tf.nn.softmax_cross_entrop)进行交叉熵损失值计算 with tf.variable_scope('loss'): loss = tf.reduce_mean(tf.nn.softmax_cross_entropy_with_logits(labels=y, logits=logits)) # 构造损失值的折线图 tf.summary.scalar('loss', loss) # 使用tf.train.AdamOptimizer进行损失值的降低 train_op = tf.train.AdamOptimizer(learning_rate).minimize(loss) # 计算准确率 with tf.variable_scope('accuracy'): # 使用tf.equal() 计算correct_pred correct_pred = tf.equal(tf.argmax(logits, axis=1), tf.argmax(y, 1)) # 使用tf.reduce_mean() 计算准确率 accuracy = tf.reduce_mean(tf.cast(correct_pred, 'float')) # 在tensorboard画出准确率的折线图 tf.summary.scalar('accuracy', accuracy) # 对参数进行初始化操作 sess.run(tf.global_variables_initializer()) # 将所有的summary在tensorboard进行画图 ssum = tf.summary.merge_all() # 构造tensorboard的路径 tensorboard_dir = './tensorboard/test3/' # 构造summary的写入 writer = tf.summary.FileWriter(tensorboard_dir + hparam) # 将graph进行添加 writer.add_graph(sess.graph) # 进行循环迭代 for i in range(2001): # 获得数据 batch = mnist.train.next_batch(100) # 每迭代5次,执行ssum, 将summary进行添加 if i % 5 == 0: [s, accur] = sess.run([ssum, accuracy], feed_dict={x:batch[0], y:batch[1]}) # 将summary进行添加 writer.add_summary(s, i) # 进行模型的优化操作 sess.run(train_op, feed_dict={x:batch[0], y:batch[1]})
# 第二步:构建main()函数, 循环学习率,循环use_two_conv以及use_two_fc def main(): for learning_rate in [1E-4]: for use_two_conv in [True]: for use_two_fc in [True]: # 第三步:构建basename,将学习率和use_two_conv和use_two_fc组合成字符串 hparam = make_hparam_string(learning_rate, use_two_conv, use_two_fc) # 第四步:构建网络模型,将学习率,是否使用两个卷积层,是否使用两个全连接层,以及文件的basename传入 mnist_model(learning_rate, use_two_conv, use_two_fc, hparam) # 第五步:执行函数 if __name__ == '__main__': main()

进入到tensorboard路径下,输入tensorboard --logdir=./test3
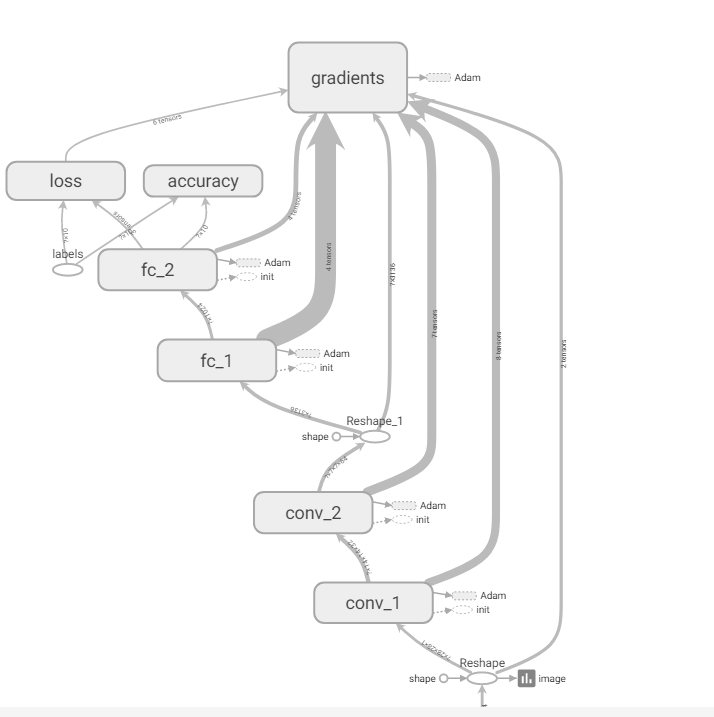
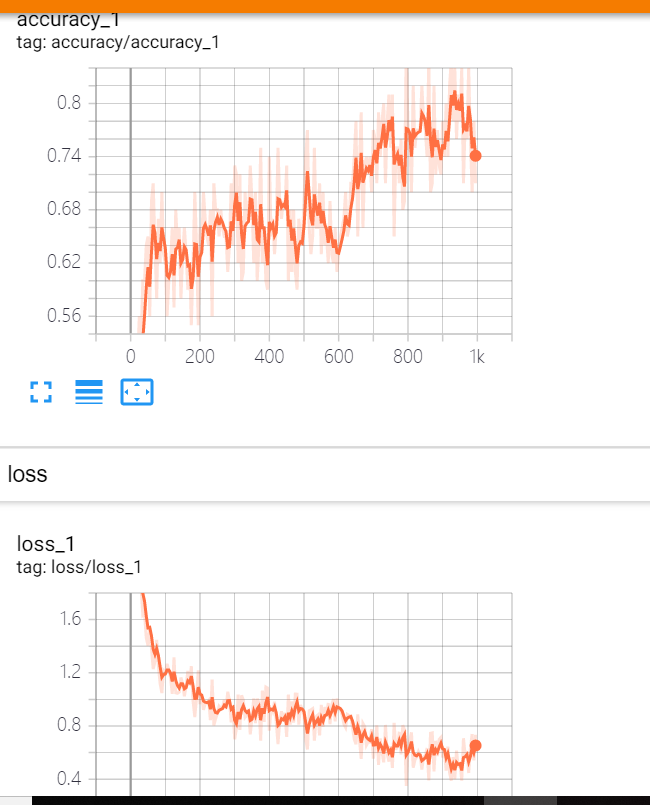

writer.add_graph(sess.graph)结构图 tf.summary.scalar趋势折线图 tf.summary.image 前几个图像

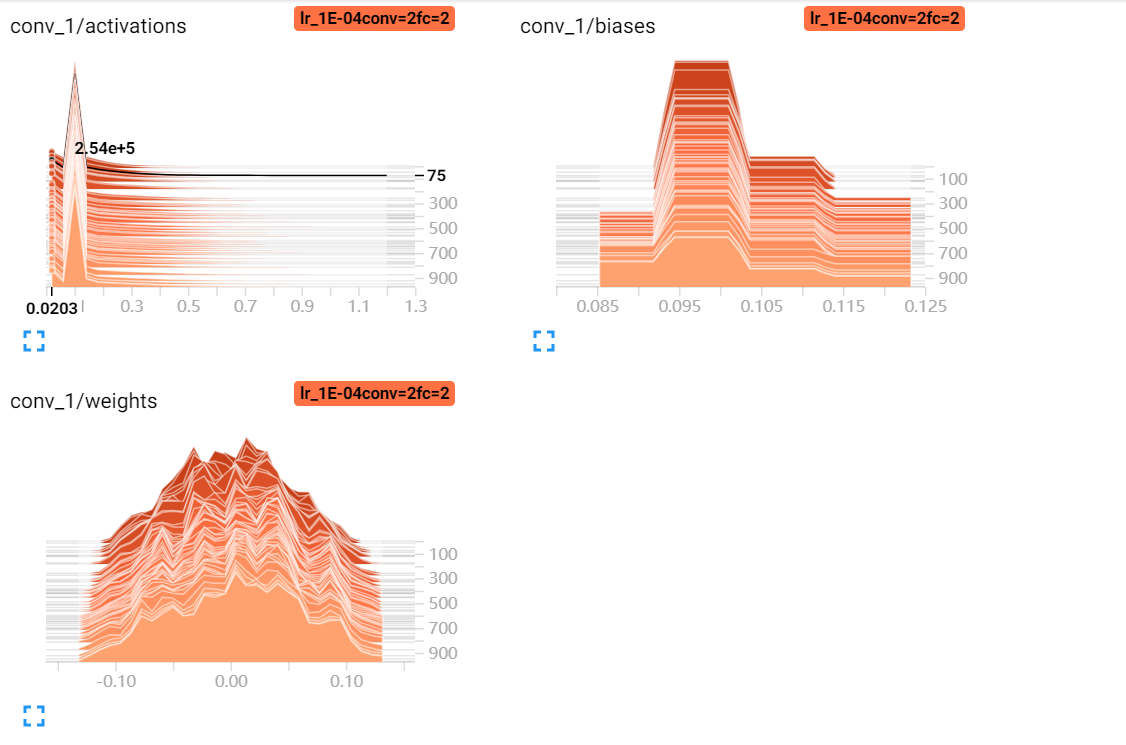
tf.summary.distribution参数分布图 tf.summary.histgraph参数直方图
第二部分:对不同的参数做一个对比,上述的代码只要循环处发生了改变
for learning_rate in [1E-4,1E-3,1E-2]: # Include "False" as a value to try different model architectures for use_two_fc in [True,False]: for use_two_conv in [True,False]: for iter_num in [1000,2000,5000]:
我们可以根据获得的结果,可以使用tersorboard进行参数的筛选