相比于上一个版本,这个版本引入了cost = torch.nn.MSELoss(reduction=True) 和 optimizer(Adam)优化器
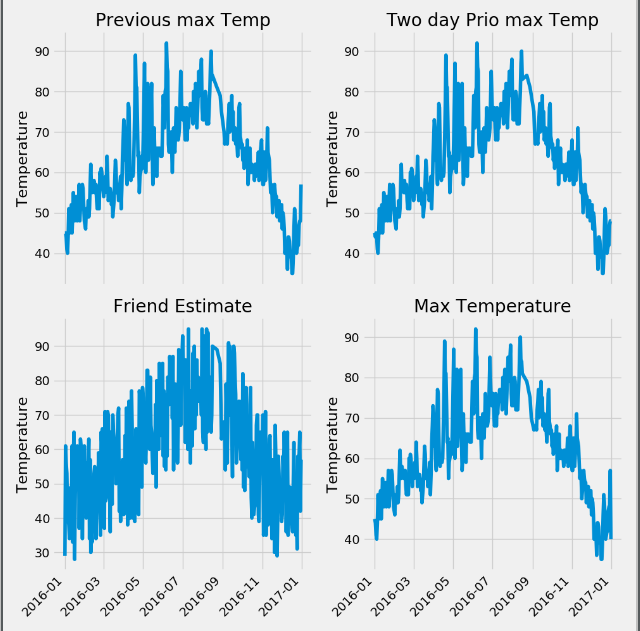
第一步: 进行特征的可视化操作
import pandas as pd import numpy as np import datetime import matplotlib.pyplot as plt features = pd.read_csv('temps.csv') # 可视化图形 print(features.head(5)) #使用日期构造可视化图像 dates = [str(int(year)) + "-" + str(int(month)) + "-" + str(int(day)) for year, month, day in zip(features['year'], features['month'], features['day'])] dates = [datetime.datetime.strptime(date, "%Y-%m-%d") for date in dates] # 进行画图操作 plt.style.use("fivethirtyeight") fig, ((ax1, ax2), (ax3, ax4)) = plt.subplots(nrows=2, ncols=2, figsize=(10, 10)) fig.autofmt_xdate(rotation=45) ax1.plot(dates, features["temp_1"]) ax1.set_xlabel('') ax1.set_ylabel('Temperature') ax1.set_title("Previous max Temp") ax2.plot(dates, features["temp_2"]) ax2.set_xlabel('') ax2.set_ylabel('Temperature') ax2.set_title("Two day Prio max Temp") ax3.plot(dates, features["friend"]) ax3.set_xlabel('') ax3.set_ylabel('Temperature') ax3.set_title("Friend Estimate") ax4.plot(dates, features["actual"]) ax4.set_xlabel('') ax4.set_ylabel('Temperature') ax4.set_title("Max Temperature") plt.tight_layout(pad=2) plt.show()
第二步: 对非数字的特征进行独热编码,使用温度的真实值作为标签,去除真实值的特征作为输入特征,同时使用process进行标准化操作
# 构造独热编码 # 遍历特征,将里面不是数字的特征进行去除 for feature_name in features.columns: print(feature_name) try: float(features.loc[0, feature_name]) except: for s in set(features[feature_name]): features[s] = 0 #根据每一行数据在时间特征上添加为1 for f in range(len(features)): features.loc[f, [features.iloc[f][feature_name]]] = 1 # 去除对应的week特征 features = features.drop(feature_name, axis=1) # 构造独热编码也可以使用 # features = pd.get_dummies(features) # 构造标签 labels = np.array(features['actual']) # 构造特征 features = features.drop('actual', axis=1) # 进行torch网络训练 import torch # 对特征进行标准化操作 from sklearn import preprocessing input_feature = preprocessing.StandardScaler().fit_transform(features) print(input_feature[:, 5])
第三步: 对特征和标签进行torch.tensor处理,转换为tensor格式,使用torch.nn.MseLoss作为损失值, 使用torch.optim.Adam构造优化器
import torch import torch.nn as nn input_size = input_feature.shape[1] hidden_size = 128 output_size = 1 batch_size = 16 epochs = 1000 my_nn = nn.Sequential( torch.nn.Linear(input_size, hidden_size), torch.nn.Sigmoid(), torch.nn.Linear(hidden_size, output_size) ) x = torch.tensor(input_feature, dtype=torch.float) y = torch.tensor(labels, dtype=torch.float) cost = torch.nn.MSELoss(reduction="mean") optimizer = torch.optim.Adam(my_nn.parameters(), lr=0.001) for i in range(epochs): batch_mean = [] for start in range(0, len(input_feature), batch_size): end = start + batch_size if start + batch_size < len(input_feature) else len(input_feature) xx = x[start:end] yy = y[start:end] predict = my_nn(xx) loss = cost(yy, predict) optimizer.zero_grad() loss.backward(retain_graph=True) optimizer.step() batch_mean.append(loss.data.numpy()) if i % 100 == 0: print(np.mean(batch_mean)) for i in my_nn.parameters(): print(i.data.numpy())
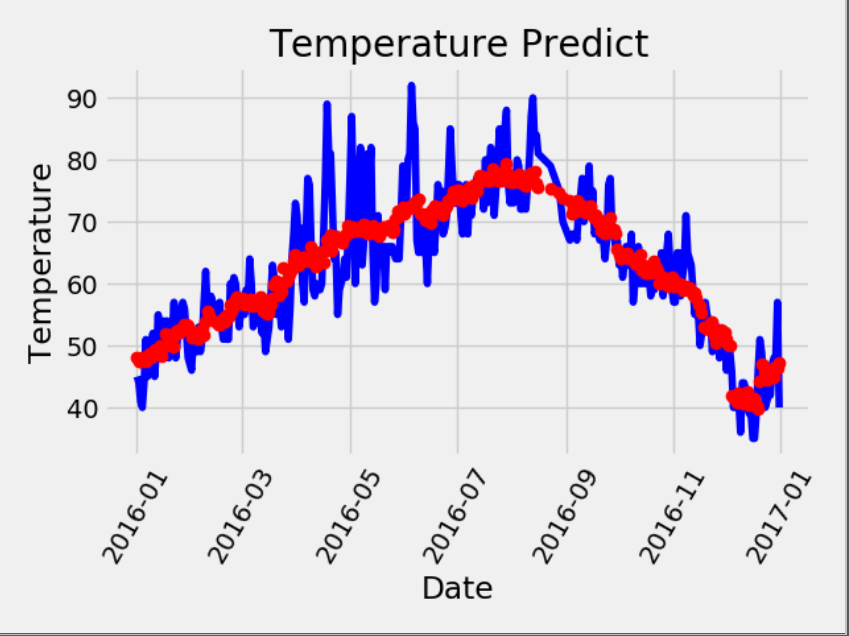
第四步:进行作图的可视化,使用了Adam优化器相较于上述的梯度优化器而言,预测结果更加的平稳
x = torch.tensor(input_feature, dtype=torch.float) predict = np.squeeze(my_nn(x).data.numpy()) dates = [str(int(year)) + '-' + str(int(month)) + '-' + str(int(day)) for year, month, day in zip(years, months, days)] dates = [datetime.datetime.strptime(date, "%Y-%m-%d") for date in dates] true_data = pd.DataFrame(data = {"date":dates, "actual":labels}) predict_data = pd.DataFrame(data= {"date":dates, "predict":predict}) plt.plot(true_data["date"], true_data["actual"], "b-", label='actual') plt.plot(predict_data['date'], predict_data['predict'], 'ro', label='predict') plt.xticks(rotation=60) plt.title("Temperature Predict") plt.xlabel("Date") plt.ylabel("Temperature") plt.show()