官网文档:https://docs.mongodb.com/
1. 创建数据库
#如果数据库不存在,则创建数据库,否则切换到指定数据库 use DATABASE_NAME
示例:
use runoob
如果你想查看所有数据库,可以使用 show dbs 命令。
2. 删除数据库
#删除当前数据库,默认为 test,你可以使用 db 命令查看当前数据库名。 db.dropDatabase()
示例:
#查看所有数据库 show dbs; #切换数据库 use runoob; #删除数据库 db.dropDatabase();
3. 创建集合
#创建集合 db.createCollection(name, options)
参数说明:
- name: 要创建的集合名称
- options: 可选参数, 指定有关内存大小及索引的选项
- capped:布尔型。(可选)如果为 true,则创建固定集合。固定集合是指有着固定大小的集合,当达到最大值时,它会自动覆盖最早的文档。当该值为 true 时,必须指定 size 参数。
- autoIndexId:布尔型。(可选)如为 true,自动在 _id 字段创建索引。默认为 false。
- size:数值,(可选)为固定集合指定一个最大值,以千字节计(KB)。如果 capped 为 true,也需要指定该字段。
- max:数值,(可选)指定固定集合中包含文档的最大数量。
示例:
db.createCollection("runoob"); db.createCollection("mycol", { capped : true, autoIndexId : true, size : 6142800, max : 10000 } )
在插入文档时,MongoDB 首先检查固定集合的 size 字段,然后检查 max 字段。
如果要查看已有集合,可以使用 show collections 或 show tables 命令。
注:在 MongoDB 中,你不需要创建集合。当你插入一些文档时,MongoDB 会自动创建集合。
4. 删除集合
#语法 db.collection.drop() #示例,mycol2为集合名称 db.mycol2.drop()
可以通过show collections查看是否已成功删除集合。
5. 插入文档
MongoDB 使用 insert() 或 save() 方法向集合中插入文档。
#语法 db.COLLECTION_NAME.insert(document) # 示例,col为集合名称,如果该集合不在该数据库中,会自动创建该集合并插入文档。 db.col.insert({title: 'MongoDB 教程', description: 'MongoDB 是一个 Nosql 数据库', by: '菜鸟教程', url: 'http://www.runoob.com', tags: ['mongodb', 'database', 'NoSQL'], likes: 100 })
6. 更新文档
MongoDB 使用 update() 和 save() 方法来更新集合中的文档。
(1) update()
#语法
db.collection.update(
<query>,
<update>,
{
upsert: <boolean>,
multi: <boolean>,
writeConcern: <document>
}
)
参数说明:
- query : update的查询条件,类似sql update查询内where后面的。
- update : update的对象和一些更新的操作符(如$,$inc...)等,也可以理解为sql update查询内set后面的
- upsert : 可选,这个参数的意思是,如果不存在update的记录,是否插入objNew,true为插入,默认是false,不插入。
- multi : 可选,mongodb 默认是false,只更新找到的第一条记录,如果这个参数为true,就把按条件查出来多条记录全部更新。
- writeConcern :可选,抛出异常的级别。
#示例 db.col.update({'title':'MongoDB 教程'},{$set:{'title':'MongoDB'}}) #类似于SQL update col set title = 'MongoDB' where title='MongoDB 教程';
(2) save()方法
save() 方法通过传入的文档来替换已有文档。
db.collection.save( <document>, { writeConcern: <document> } )
7. 删除文档
#mongo2.6之前 db.collection.remove( <query>, <justOne> ) #mongo2.6之后 db.collection.remove( <query>, { justOne: <boolean>, writeConcern: <document> } )
参数说明:
- query :(可选)删除的文档的条件。
- justOne : (可选)如果设为 true 或 1,则只删除一个文档,如果不设置该参数,或使用默认值 false,则删除所有匹配条件的文档。
- writeConcern :(可选)抛出异常的级别。
示例:
#若查询出多条,则删除多条 db.col.remove({'title':'MongoDB 教程'}); #有多条记录,但是只想删除第一条找到的记录可以设置 justOne 为 1 db.COLLECTION_NAME.remove(DELETION_CRITERIA,1) #删除所有数据 db.col.remove({})
8. 查询文档
#语法 db.collection.find(query, projection)
参数说明:
- query :可选,使用查询操作符指定查询条件
- projection :可选,使用投影操作符指定返回的键。查询时返回文档中所有键值, 只需省略该参数即可(默认省略)。
如果你需要以易读的方式来读取数据,可以使用 pretty() 方法:
#pretty() 方法以格式化的方式来显示所有文档。 db.col.find().pretty();
除了 find() 方法之外,还有一个 findOne() 方法,它只返回一个文档。
(1) MongoDB 与 RDBMS Where 语句比较
| 等于 | {<key>:<value>} | db.col.find({"by":"菜鸟教程"}).pretty(); | where by ='菜鸟教程' |
| 小于 | {<key>:{$lt:<value>}} | db.col.find({"likes":{$lt:50}}).pretty(); | where likes < 50 |
| 小于或等于 | {<key>:{$lte:<value>}} | db.col.find({"likes":{$lte:50}}).pretty(); | where likes <= 50 |
| 大于 | {<key>:{$gt:<value>}} | db.col.find({"likes":{$gt:50}}).pretty(); | where likes > 50 |
| 大于或等于 | {<key>:{$gte:<value>}} | db.col.find({"likes":{$gte:50}}).pretty(); | where likes >= 50 |
| 不等于 | {<key>:{$ne:<value>}} | db.col.find({"likes":{$ne:50}}).pretty(); | where likes != 50 |
(2) MongoDB AND 条件
db.col.find({key1:value1, key2:value2}).pretty();
(3) MongoDB OR 条件
db.col.find( { $or: [ {key1: value1}, {key2:value2} ] } ).pretty();
AND和OR条件可以配合使用。
9. 条件操作符
MongoDB中条件操作符有:
- (>) 大于 : $gt
- (<) 小于 : $lt
- (>=) 大于等于 : $gte
- (<= ) 小于等于 : $lte
#获取 "col" 集合中 "likes" 大于 100 的数据 db.col.find({likes : {$gt : 100}}) #类似于SQL Select * from col where likes > 100;
#获取"col"集合中 "likes" 大于100,小于 200 的数据 db.col.find({likes : {$lt :200, $gt : 100}}) #类似于SQL Select * from col where likes>100 AND likes<200;
10. $type操作符
$type操作符是基于BSON类型来检索集合中匹配的数据类型,并返回结果。
MongoDB 中可以使用的类型如下表所示:
| 类型 | 数字 | 备注 |
|---|---|---|
| Double | 1 | |
| String | 2 | |
| Object | 3 | |
| Array | 4 | |
| Binary data | 5 | |
| Undefined | 6 | 已废弃。 |
| Object id | 7 | |
| Boolean | 8 | |
| Date | 9 | |
| Null | 10 | |
| Regular Expression | 11 | |
| JavaScript | 13 | |
| Symbol | 14 | |
| JavaScript (with scope) | 15 | |
| 32-bit integer | 16 | |
| Timestamp | 17 | |
| 64-bit integer | 18 | |
| Min key | 255 | Query with -1. |
| Max key | 127 |
#获取 "col" 集合中 title 为 String 的数据 db.col.find({"title" : {$type : 2}}) 或 db.col.find({"title" : {$type : 'string'}})
11. Limit与Skip方法
(1) limit()
如果你需要在MongoDB中读取指定数量的数据记录,可以使用MongoDB的Limit方法,limit()方法接受一个数字参数,该参数指定从MongoDB中读取的记录条数。
db.COLLECTION_NAME.find().limit(NUMBER);
注:如果你们没有指定limit()方法中的参数则显示集合中的所有数据。
(2) skip()
使用skip()方法来跳过指定数量的数据,skip方法同样接受一个数字参数作为跳过的记录条数。
db.COLLECTION_NAME.find().limit(NUMBER).skip(NUMBER);
注:skip()方法默认参数为 0 。
12. 排序
在 MongoDB 中使用 sort() 方法对数据进行排序,sort() 方法可以通过参数指定排序的字段,并使用 1 和 -1 来指定排序的方式,其中 1 为升序排列,而 -1 是用于降序排列。
db.COLLECTION_NAME.find().sort({KEY:1});
示例:按字段 likes 的降序排列
db.col.find({},{"title":1,_id:0}).sort({"likes":-1})
{ "title" : "PHP 教程" }
{ "title" : "Java 教程" }
{ "title" : "MongoDB 教程" });
13. 索引
索引通常能够极大的提高查询的效率,如果没有索引,MongoDB在读取数据时必须扫描集合中的每个文件并选取那些符合查询条件的记录。这种扫描全集合的查询效率是非常低的,特别在处理大量的数据时,查询可以要花费几十秒甚至几分钟,这对网站的性能是非常致命的。索引是特殊的数据结构,索引存储在一个易于遍历读取的数据集合中,索引是对数据库表中一列或多列的值进行排序的一种结构。
注意:在 3.0.0 版本前创建索引方法为 db.collection.ensureIndex(),之后的版本使用了 db.collection.createIndex() 方法,ensureIndex() 还能用,但只是 createIndex() 的别名。
#语法, keys 值为你要创建的索引字段 db.collection.createIndex(keys, options); #示例, 1 为指定按升序创建索引,如果你想按降序来创建索引指定为 -1 即可。 db.col.createIndex({"title":1}) #createIndex() 方法中你也可以设置使用多个字段创建索引(关系型数据库中称作复合索引)。 db.col.createIndex({"title":1,"description":-1})
options可选参数列表如下:
- background:布尔型。建索引过程会阻塞其它数据库操作,background可指定以后台方式创建索引, "background" 默认值为false。
- unique:布尔型。建立的索引是否唯一。指定为true创建唯一索引。默认值为false。
- name:索引名称。如果未指定,MongoDB的通过连接索引的字段名和排序顺序生成一个索引名称。
- sparse:布尔型。对文档中不存在的字段数据不启用索引;这个参数需要特别注意,如果设置为true的话,在索引字段中不会查询出不包含对应字段的文档。默认值为 false。
- expireAfterSeconds:数值型。指定一个以秒为单位的数值,完成 TTL设定,设定集合的生存时间。
- v:索引的版本号。默认的索引版本取决于mongod创建索引时运行的版本。
- weights:索引权重值,数值在 1 到 99,999 之间,表示该索引相对于其他索引字段的得分权重。
#查看集合索引 db.col.getIndexes() #查看集合索引大小 db.col.totalIndexSize() #删除集合所有索引 db.col.dropIndexes() #删除集合指定索引 db.col.dropIndex("索引名称")
14. 聚合
聚合主要用于处理数据(诸如统计平均值,求和等),并返回计算后的数据结果。有点类似sql语句中的 count(*)。
#语法 db.COLLECTION_NAME.aggregate(AGGREGATE_OPERATION);
#示例 db.mycol.aggregate([{$group : {_id : "$by_user", num_tutorial : {$sum : 1}}}]) #类似SQL select by_user, count(*) from mycol group by by_user
下表展示了一些聚合的表达式:
| 表达式 | 描述 | 示例 |
| $num | 计算总和 | db.mycol.aggregate([{$group : {_id : "$by_user", num_tutorial : {$sum : "$likes"}}}]) |
| $avg | 计算平均值 | db.mycol.aggregate([{$group : {_id : "$by_user", num_tutorial : {$avg : "$likes"}}}]) |
| $min | 获取集合中所有文档对应值得最小值 | db.mycol.aggregate([{$group : {_id : "$by_user", num_tutorial : {$min : "$likes"}}}]) |
| $max | 获取集合中所有文档对应值得最大值 | db.mycol.aggregate([{$group : {_id : "$by_user", num_tutorial : {$max : "$likes"}}}]) |
| $push | 在结果文档中插入值到一个数组中 | db.mycol.aggregate([{$group : {_id : "$by_user", url : {$push: "$url"}}}]) |
| $addToSet | 在结果文档中插入值到一个数组中,但不创建副本 | db.mycol.aggregate([{$group : {_id : "$by_user", url : {$addToSet : "$url"}}}]) |
| $first | 根据资源文档的排序获取第一个文档数据 | db.mycol.aggregate([{$group : {_id : "$by_user", first_url : {$first : "$url"}}}]) |
| $last | 根据资源文档的排序获取最后一个文档数据 | db.mycol.aggregate([{$group : {_id : "$by_user", last_url : {$last : "$url"}}}]) |
(1) 管道
管道在Unix和Linux中一般用于将当前命令的输出结果作为下一个命令的参数。
MongoDB的聚合管道将MongoDB文档在一个管道处理完毕后将结果传递给下一个管道处理。管道操作是可以重复的。
表达式:处理输入文档并输出。表达式是无状态的,只能用于计算当前聚合管道的文档,不能处理其它的文档。
这里我们介绍一下聚合框架中常用的几个操作:
- $project:修改输入文档的结构。可以用来重命名、增加或删除域,也可以用于创建计算结果以及嵌套文档。
- $match:用于过滤数据,只输出符合条件的文档。$match使用MongoDB的标准查询操作。
- $limit:用来限制MongoDB聚合管道返回的文档数。
- $skip:在聚合管道中跳过指定数量的文档,并返回余下的文档。
- $unwind:将文档中的某一个数组类型字段拆分成多条,每条包含数组中的一个值。
- $group:将集合中的文档分组,可用于统计结果。
- $sort:将输入文档排序后输出。
- $geoNear:输出接近某一地理位置的有序文档。
#$project示例 db.article.aggregate( { $project : { title : 1 , author : 1 , }} ); #这样的话结果中就只还有_id,tilte和author三个字段了,默认情况下_id字段是被包含的,如果要想不包含_id话可以这样: db.article.aggregate( { $project : { _id : 0 , title : 1 , author : 1 }});
#$match示例:用于获取分数大于70小于或等于90记录,然后将符合条件的记录送到下一阶段$group管道操作符进行处理。 db.articles.aggregate( [ { $match : { score : { $gt : 70, $lte : 90 } } }, { $group: { _id: null, count: { $sum: 1 } } } ] );
#$skip示例:经过$skip管道操作符处理后,前五个文档被"过滤"掉。 db.article.aggregate( { $skip : 5 });
15. 复制(副本集)
MongoDB复制是将数据同步在多个服务器的过程。
复制提供了数据的冗余备份,并在多个服务器上存储数据副本,提高了数据的可用性, 并可以保证数据的安全性。
(1) 复制原理
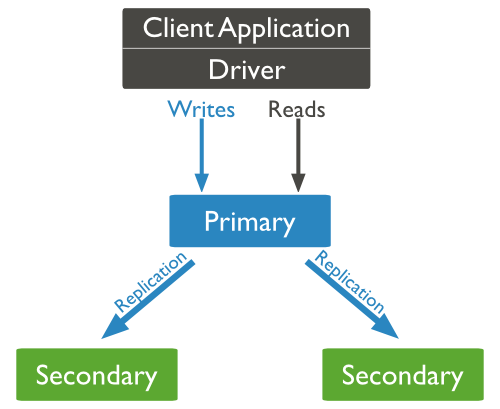
mongodb的复制至少需要两个节点。其中一个是主节点,负责处理客户端请求,其余的都是从节点,负责复制主节点上的数据。
mongodb各个节点常见的搭配方式为:一主一从、一主多从。
主节点记录在其上的所有操作oplog,从节点定期轮询主节点获取这些操作,然后对自己的数据副本执行这些操作,从而保证从节点的数据与主节点一致。
MongoDB复制结构图如下所示:
(2) 副本集设置
#指定 --replSet 选项来启动mongoDB mongod --port "PORT" --dbpath "YOUR_DB_DATA_PATH" --replSet "REPLICA_SET_INSTANCE_NAME" #示例, 启动一个名为rs0的MongoDB实例,其端口号为27017 mongod --port 27017 --dbpath "/usr/local/mongodb" --replSet rs0
在Mongo客户端使用命令rs.initiate()来启动一个新的副本集。
我们可以使用rs.conf()来查看副本集的配置。
查看副本集状态使用 rs.status() 命令。
(3) 副本集添加成员
添加副本集的成员,我们需要使用多台服务器来启动mongo服务。进入Mongo客户端,并使用rs.add()方法来添加副本集的成员。
#语法 rs.add(HOST_NAME:PORT)
MongoDB中你只能通过主节点将Mongo服务添加到副本集中, 判断当前运行的Mongo服务是否为主节点可以使用命令db.isMaster() 。
MongoDB的副本集与我们常见的主从有所不同,主从在主机宕机后所有服务将停止,而副本集在主机宕机后,副本会接管主节点成为主节点,不会出现宕机的情况。
16. 分片
在Mongodb里面存在另一种集群,就是分片技术,可以满足MongoDB数据量大量增长的需求。
当MongoDB存储海量的数据时,一台机器可能不足以存储数据,也可能不足以提供可接受的读写吞吐量。这时,我们就可以通过在多台机器上分割数据,使得数据库系统能存储和处理更多的数据。
下图展示了在MongoDB中使用分片集群结构分布:
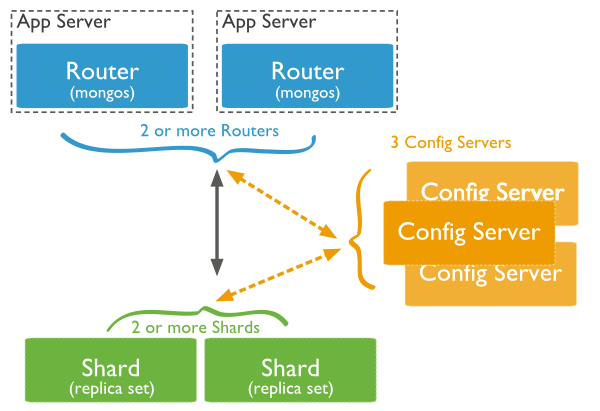
- Shard:用于存储实际的数据块,实际生产环境中一个shard server角色可由几台机器组个一个replica set承担,防止主机单点故障
- Config Server:mongod实例,存储了整个 ClusterMetadata,其中包括 chunk信息。
- Query Routers:前端路由,客户端由此接入,且让整个集群看上去像单一数据库,前端应用可以透明使用。
17. 备份与恢复
(1) 数据备份
在Mongodb中我们使用mongodump命令来备份MongoDB数据。该命令可以导出所有数据到指定目录中。
mongodump命令可以通过参数指定导出的数据量级转存的服务器。
mongodump -h dbhost -d dbname -o dbdirectory
- -h:MongoDB所在服务器地址,例如:127.0.0.1,当然也可以指定端口号:127.0.0.1:27017。
- -d:需要备份的数据库实例,例如:test
- -o:备份的数据存放位置,例如:/tmp/data/ump,该目录需要提前建立,在备份完成后,系统自动在dump目录下建立一个test目录,这个目录里面存放该数据库实例的备份数据。
mongodump 命令可选参数列表如下所示:
- mongodump --host HOST_NAME --port PORT_NUMBER:该命令将备份所有MongoDB数据
- mongodump --dbpath DB_PATH --out BACKUP_DIRECTORY
- mongodump --collection COLLECTION --db DB_NAME:该命令将备份指定数据库的集合。
(2) 数据恢复
mongodb使用 mongorestore 命令来恢复备份的数据。
mongorestore -h <hostname><:port> -d dbname <path>
-
--host <:port>, -h <:port>:
MongoDB所在服务器地址,默认为: localhost:27017 -
--db , -d :
需要恢复的数据库实例,例如:test,当然这个名称也可以和备份时候的不一样,比如test2 -
--drop:
恢复的时候,先删除当前数据,然后恢复备份的数据。就是说,恢复后,备份后添加修改的数据都会被删除,慎用哦! -
<path>:
mongorestore 最后的一个参数,设置备份数据所在位置,例如:c:datadump est。你不能同时指定 <path> 和 --dir 选项,--dir也可以设置备份目录。
-
--dir:
指定备份的目录你不能同时指定 <path> 和 --dir 选项。