1.设置浏览器引擎
# 本地Chrome浏览器设置方法 from selenium import webdriver #从selenium库中调用webdriver模块 driver = webdriver.Chrome() # 设置引擎为Chrome,真实地打开一个Chrome浏览器
配置好了浏览器,就可以开始让它帮我们干活啦!
2.selenium的用法
2.1 获取数据
# 本地Chrome浏览器设置方法 from selenium import webdriver #从selenium库中调用webdriver模块
import time
driver = webdriver.Chrome() # 设置引擎为Chrome,真实地打开一个Chrome浏览器 driver.get('https://localprod.pandateacher.com/python-manuscript/hello-spiderman/') # 打开网页 time.sleep(1) driver.close() # 关闭浏览器
get(URL)是webdriver的一个方法,它的使命是为你打开指定URL的网页。
当一个网页被打开,网页中的数据就加载到了浏览器中,也就是说,数据被我们获取到了。
driver.close()是关闭浏览器驱动,每次调用了webdriver之后,都要在用完它之后加上一行driver.close()用来关闭它
2.2 解析与提取数据
from selenium import webdriver import time driver = webdriver.Chrome() driver.get('https://localprod.pandateacher.com/python-manuscript/hello-spiderman/') # 访问页面 time.sleep(2) # 等待2秒 label = driver.find_element_by_tag_name('label') # 解析网页并提取第一个<lable>标签 print(label.text) # 打印label的文本 driver.close() # 关闭浏览器
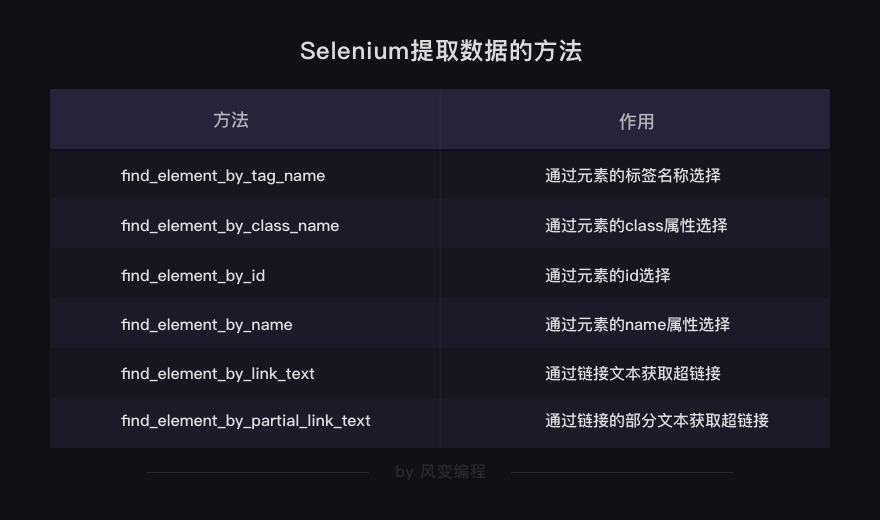
# 以下方法都可以从网页中提取出'你好,蜘蛛侠!'这段文字 find_element_by_tag_name:通过元素的名称选择 # 如<h1>你好,蜘蛛侠!</h1> # 可以使用find_element_by_tag_name('h1') find_element_by_class_name:通过元素的class属性选择 # 如<h1 class="title">你好,蜘蛛侠!</h1> # 可以使用find_element_by_class_name('title') find_element_by_id:通过元素的id选择 # 如<h1 id="title">你好,蜘蛛侠!</h1> # 可以使用find_element_by_id('title') find_element_by_name:通过元素的name属性选择 # 如<h1 name="hello">你好,蜘蛛侠!</h1> # 可以使用find_element_by_name('hello') #以下两个方法可以提取出超链接 find_element_by_link_text:通过链接文本获取超链接 # 如<a href="spidermen.html">你好,蜘蛛侠!</a> # 可以使用find_element_by_link_text('你好,蜘蛛侠!') find_element_by_partial_link_text:通过链接的部分文本获取超链接 # 如<a href="https://localprod.pandateacher.com/python-manuscript/hello-spiderman/">你好,蜘蛛侠!</a> # 可以使用find_element_by_partial_link_text('你好')
以上就是提取单个元素的方法了。
from selenium import webdriver import time driver = webdriver.Chrome() driver.get('https://localprod.pandateacher.com/python-manuscript/hello-spiderman/') # 访问页面 time.sleep(2) # 等待2秒 label = driver.find_element_by_tag_name('label') # 解析网页并提取第一个<lable>标签 print(type(label)) # 打印label的数据类型 print(label.text) # 打印label的文本 print(label) # 打印label driver.close() # 关闭浏览器
运行结果有3行,分别是:
<class 'selenium.webdriver.remote.webelement.WebElement'>、label的文本(提示:吴枫)、以及label本身。
WebElement类对象,如果直接打印它,返回的是一串对它的描述。BeautifulSoup中的Tag对象类似,也有一个属性.text,可以把提取出的元素用字符串格式显示。WebElement类对象与Tag对象类似,它也有一个方法,可以通过属性名提取属性的值,这个方法是.get_attribute()。
因此,我们可以总结出,selenium解析与提取数据的过程中,我们操作的对象转换:

find_element_by_与BeautifulSoup中的find类似,可以提取出网页中第一个符合要求的元素;既然BeautifulSoup有提取所有元素的方法find_all,selenium也同样有方法。
方法也一样很简单,把刚才的element换成复数elements就好了。
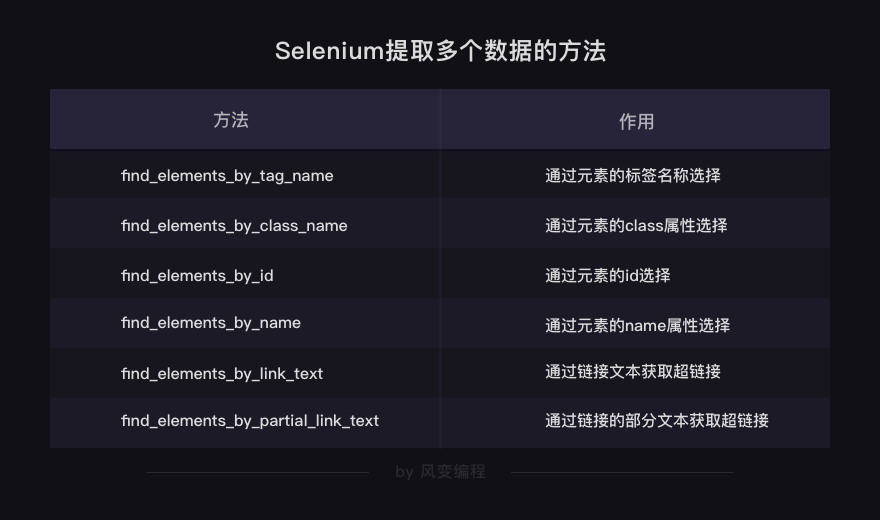
以上就是selenium的解析与提取数据的方法了。
selenium解析与提取数据,还有一种解决方案,那就是,使用selenium获取网页,然后交给BeautifulSoup解析和提取。selenium与BeautifulSoup如何快乐地合作。BeautifulSoup的工作方式吧。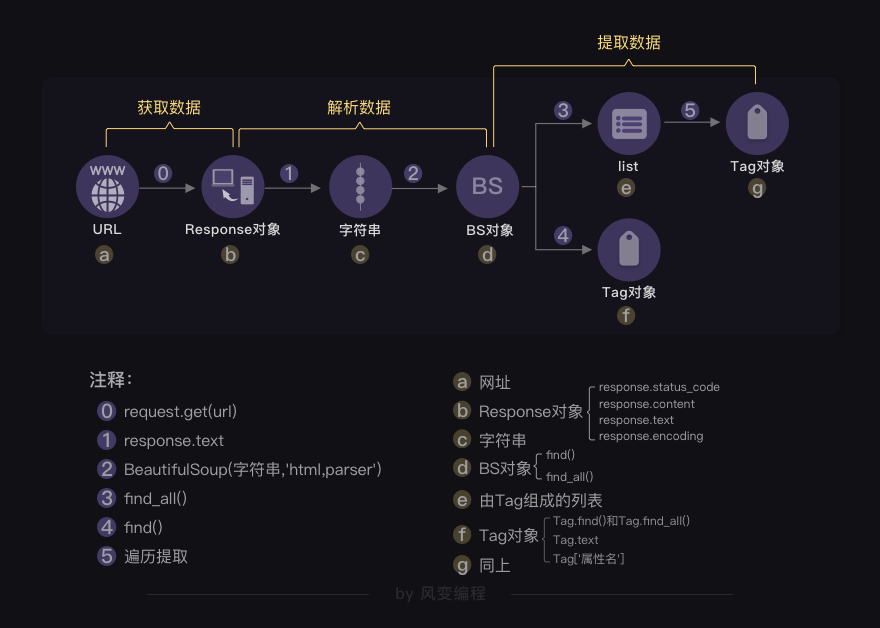
BeautifulSoup需要把字符串格式的网页源代码解析为BeautifulSoup对象,然后再从中提取数据。
selenium刚好可以获取到渲染完整的网页源代码。
如何获取呢?也是使用driver的一个方法:page_source。
HTML源代码字符串 = driver.page_source
#coding= gbk from selenium import webdriver import time driver = webdriver.Chrome() driver.get('https://localprod.pandateacher.com/python-manuscript/hello-spiderman/') time.sleep(3) pageSource = driver.page_source # 获取完整渲染的网页源代码 print(type(pageSource)) # 打印pageSource的类型 print(pageSource) # 打印pageSource driver.close() # 关闭浏览器
我们成功获取并打印出了网页源代码O(∩_∩)O~~而且它的数据类型是<class 'str'>。
你还记不记得,用requests.get()获取到的是Response对象,在交给BeautifulSoup解析之前,需要用到.text的方法才能将Response对象的内容以字符串的形式返回。
而使用selenium获取到的网页源代码,本身已经是字符串了。
获取到了字符串格式的网页源代码之后,就可以用BeautifulSoup解析和提取数据了。
2.3 自动操作浏览器
其实,要做到上面动图中显示的效果,你只需要新学两个方法就好了:
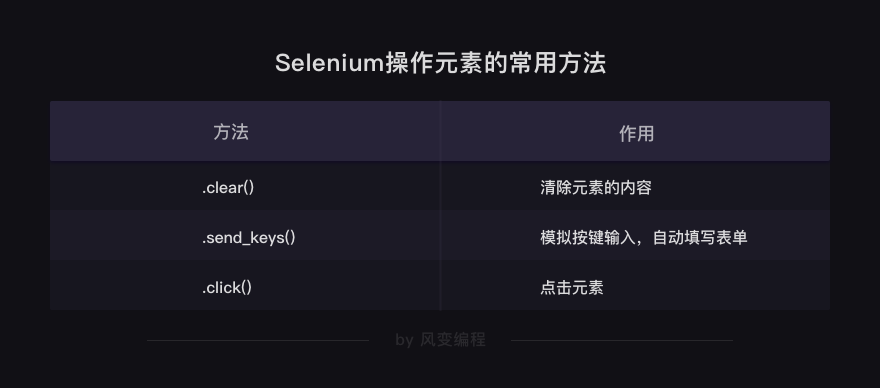
.send_keys() # 模拟按键输入,自动填写表单 .click() # 点击元素
from selenium import webdriver # 从selenium库中调用webdriver模块 import time # 调用time模块 driver = webdriver.Chrome() # 设置引擎为Chrome,真实地打开一个Chrome浏览器 driver.get('https://localprod.pandateacher.com/python-manuscript/hello-spiderman/') # 访问页面 time.sleep(2) # 暂停两秒,等待浏览器缓冲 teacher = driver.find_element_by_id('teacher') # 找到【请输入你喜欢的老师】下面的输入框位置 teacher.send_keys('必须是吴枫呀') # 输入文字 assistant = driver.find_element_by_name('assistant') # 找到【请输入你喜欢的助教】下面的输入框位置 assistant.send_keys('都喜欢') # 输入文字 button = driver.find_element_by_class_name('sub') # 找到【提交】按钮 button.click() # 点击【提交】按钮 time.sleep(1) driver.close() # 关闭浏览器
重点关注最后的8行代码,这段代码所做的是两次输入以及一次点击的操作,然后等待一秒,关闭浏览器驱动。
由于这个代码的命令都是控制浏览器做一些操作,因此终端不会返回任何结果
还想补充一个小知识,除了输入和点击的两个方法,经常配合它们会用到的,还有一个方法.clear(),用于清除元素的内容。