链表(通过“指针”将一组零散的内存块串联起来使用。)
三种常见链表结构:
- 单链表:链表通过指针将一组零散的内存块串联在一起。其中,我们把内存块称为链表的“结点”。为了将所有的结点串起来,每个链表的结点除了存储数据之外,还需要记录链上的下一个结点的地址。如图所示,我们把这个记录下个结点地址的指针叫做后继指针next
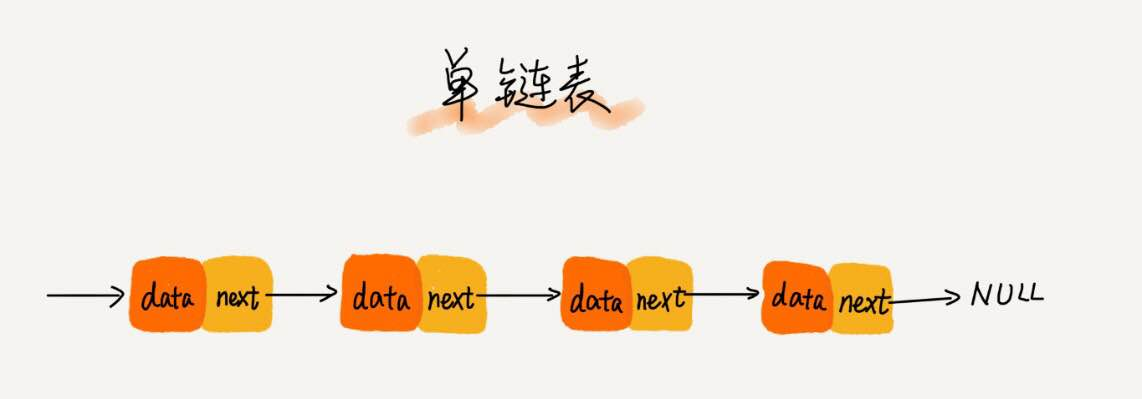
如图所示,你会发现,其中有两个结点比较特殊,他们分别是第一个结点和最后一个结点。我们习惯把第一个结点叫做头结点,把最后一个结点叫做尾结点。其中,头结点用来记录链表的基地址。有了它,我们可以遍历得到整条链表。而尾结点特殊的地方是:指针不是指向下一个结点,而是指向一个空地址NULL,表示这是链表上最后一个结点。与数组一样,链表也支持数据的查找、插入和删除操作。我们知道,进行数组的插入,删除操作时,为了保持内存的连续性,需要做出大量的数据搬移,所以时间复杂度是O(n)。而在链表中插入或者删除一个数据,我们并不需要为了保持内存的连续性而搬移结点,图中可以看出,针对链表的插入和删除操作,我们只需要考虑相邻结点的指针改变,所以对应时间复杂度是O(1)。

但是有利也有弊。链表想要随机访问第K个元素,就没有数组高效了。因为链表中的数据并非连续存储的,所以无法像数组那样,根据首地址和下标,通过寻址公式就能计算出内存地址,而是需要根据指针一个结点一个结点地依次遍历,直到找到对应的结点。所以,链表随机访问的性能没有数组好,需要O(n)的时间复杂度。
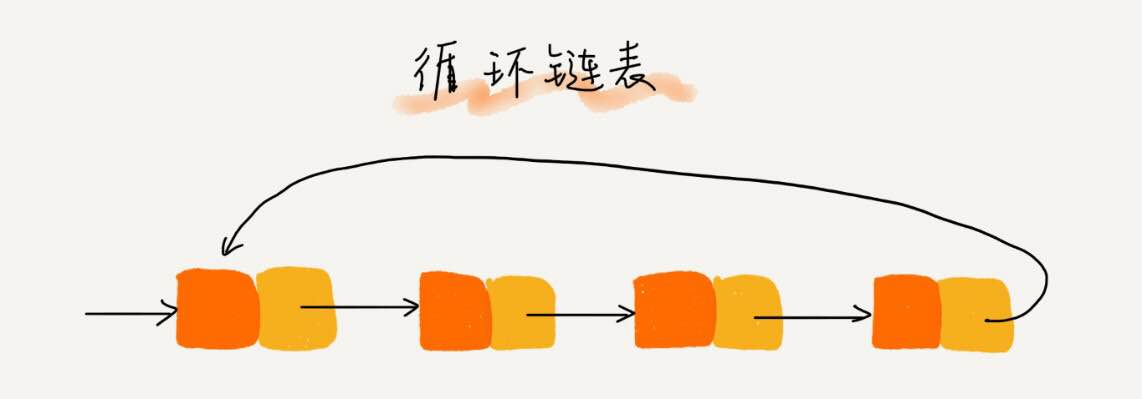
- 循环链表:循环链表实际上是一种特殊的单链表。它跟单链表唯一的区别就在尾结点。循环链表的尾结点指针不是指向NULL,而是指向链表的头结点。
- 双向链表:单向链表只有一个方向,结点只有一个后继指针next指向后面的结点。而双向链表,顾名思义,它支持两个方向,每个结点不止有一个后继指针next指向后面的结点,还有一个前驱指针prev指向前面的结点。
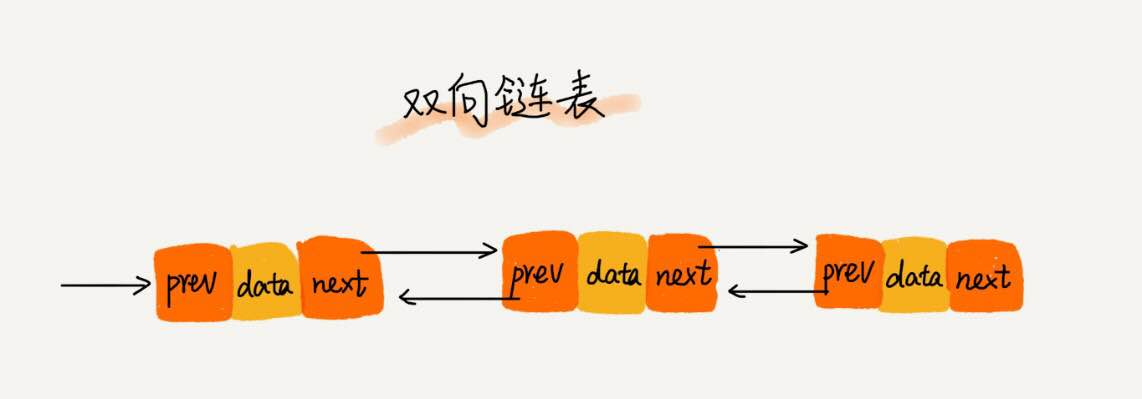
从图中可以看出,双向链表需要额外的两个空间来存储后继结点和前驱结点的地址。所以存储同样多的数据,双向链表要比单链表占用更多的内存空间。虽然两个指针比较浪费存储空间,但可以支持双向遍历。