本文地址:http://www.cnblogs.com/myresearch/p/hadoop-standalone-pseudo-distributed-operation.html,转载请注明源地址。
基本环境配置
可以使用命令uname -a 查看linux的版本:
master@ubuntu:~$ uname -a
Linux ubuntu 3.13.0-24-generic #46-Ubuntu SMP Thu Apr 10 19:11:08 UTC 2014 x86_64 x86_64 x86_64 GNU/Linux
使用 Ubuntu 14.04 64位 作为系统环境,也可以使用RedHat、CentOS等,本教程也可以作为参考,配置是相似的,就是Linux命令、具体操作有所不同。本教程基于Hadoop 2.6.0 (stable) 版本下验证通过,可适合任何 Hadoop 2.x.y 版本,例如 Hadoop 2.4.1。
装好了Ubuntu系统之后,在安装Hadoop前还需要做一些必备工作。
创建hadoop用户
如果你安装 Ubuntu 的时候不是用的 hadoop 用户,那么最好增加一个名为 hadoop 的用户,密码随意指定。首先打开终端,输入如下命令创建新用户 :
$ sudo useradd -m hadoop -s /bin/bash
这条命令创建了可以登陆的 hadoop 用户,并使用 /bin/bash 作为shell。
接着使用如下命令修改密码,按提示输入两次密码
$ sudo passwd hadoop
可为 hadoop 用户增加管理员权限,方便部署,避免一些对新手来说比较棘手的权限问题:
$ sudo adduser hadoop sudo
完整的运行情况如下:
master@ubuntu:~$ sudo useradd -m hadoop -s /bin/bash
[sudo] password for master:
master@ubuntu:~$ sudo passwd hadoop
Enter new UNIX password:
Retype new UNIX password:
passwd: password updated successfully
master@ubuntu:~$ sudo adduser hadoop sudo
[sudo] password for master:
Adding user `hadoop' to group `sudo' ...
Adding user hadoop to group sudo
Done.
最后注销当前用户(点击屏幕右上角的齿轮,选择注销),在登陆界面使用刚创建的 hadoop 用户进行登陆。
使用下面的命令更新apt:
hadoop@ubuntu:~$ sudo apt-get update
接着安装vim
hadoop@ubuntu:~$ sudo apt-get install vim
安装SSH server、配置SSH无密码登陆
集群、单节点模式都需要用到SSH登陆(类似于远程登陆,你可以登录某台Linux电脑,并且在上面运行命令),Ubuntu 默认已安装了 SSH client,此外还需要安装 SSH server:
$ sudo apt-get install openssh-server
安装后,可以使用如下命令登陆本机:
$ ssh localhost
这样登陆是需要每次输入密码的,我们需要配置成SSH无密码登陆比较方便。
首先退出刚才的 ssh,就回到了我们原先的终端窗口,然后利用 ssh-keygen 生成密钥,并将密钥加入到授权中:
cd ~/.ssh/ ssh-keygen -t rsa cat id_rsa.pub >> authorized_keys
再次使用ssh localhost登录就不需要输入密码了
hadoop@ubuntu:~/.ssh$ ssh localhost
Welcome to Ubuntu 14.04 LTS (GNU/Linux 3.13.0-24-generic x86_64)
* Documentation: https://help.ubuntu.com/
Last login: Wed May 13 04:34:05 2015 from localhost
下载配置JDK
下载jdk1.8,下载地址:http://www.oracle.com/technetwork/java/javase/downloads/jdk8-downloads-2133151.html
新建两个文件夹:opt、soft;分别存放安装后的软件和软件包
分别解压缩jdk和hadoop:
hadoop@ubuntu:~/opt$ sudo tar -zxvf jdk-8u45-linux-x64.tar.gz
接着需要配置一下 JAVA_HOME 环境变量:
在文件最前面添加如下单独一行(注意 = 号前后不能有空格),并保存
export JAVA_HOME=/home/hadoop/opt/java1.8.0_45
接着还需要让该环境变量生效,执行如下代码:
$ source ~/.bashrc # 使变量设置生效 $ echo $JAVA_HOME # 检验是否设置正确
没有错误会出现下面的结果:
hadoop@ubuntu:~$ echo $JAVA_HOME
/home/hadoop/opt/jdk1.8.0_45
但是此时运行java -version 命令,会出现如下提示:
hadoop@ubuntu:~$ java -version
The program 'java' can be found in the following packages:
* default-jre
* gcj-4.8-jre-headless
* openjdk-7-jre-headless
* gcj-4.6-jre-headless
* openjdk-6-jre-headless
Try: sudo apt-get install <selected package>
提示jre的安装问题,而实际是环境没有配置全面,继续vim ~/.bashrc,加入:
export JAVA_HOME=/home/hadoop/opt/jdk1.8.0_45 export JRE_HOME=${JAVA_HOME}/jre export CLASSPATH=.:${JAVA_HOME}/lib:${JRE_HOME}/lib export PATH=${JAVA_HOME}/bin:$PATH
hadoop@ubuntu:~$ java -version
java version "1.8.0_45"
Java(TM) SE Runtime Environment (build 1.8.0_45-b14)
Java HotSpot(TM) 64-Bit Server VM (build 25.45-b02, mixed mode)
搞定~~~
下载安装 Hadoop 2.6
下载hadoop2.6,下载地址:http://mirrors.cnnic.cn/apache/hadoop/common/stable/

注意:hadoop-2.6.0.tar.gz这个格式的文件,这是编译好的,另一个包含 src 的则是 Hadoop 源代码。
同时强烈建议也下载 hadoop-2.6.0.tar.gz.mds 这个文件,该文件包含了检验值可用于检查 hadoop-2.6.0.tar.gz 的完整性,否则若文件发生了损坏或下载不完整,Hadoop 将无法正常运行。
解压缩hadoop
hadoop@ubuntu:~/opt$ sudo tar -zxvf hadoop-2.6.0.tar.gz
现在使用下列命令得出hadoop-2.6.0.tar.gz.mds的MD5值:
$ cat ./hadoop-2.6.0.tar.gz.mds | grep 'MD5'
出现下面的结果:
hadoop-2.6.0.tar.gz: MD5 = 37 F3 71 FA AB 03 3B B8 C2 CB 50 10 0C 57 74 DC
计算hadoop-2.6.0.tar.gz的MD5值,使用下面的命令:
$ ~/opt$ md5sum ./hadoop-2.6.0.tar.gz | tr "a-z" "A-Z"
出现下面的结果:
37F371FAAB033BB8C2CB50100C5774DC ./HADOOP-2.6.0.TAR.GZ
字符对应相等,说明安装包没有问题
修改文件权限:
sudo chown -R hadoop:hadoop ./hadoop-2.6.0
输入如下命令来检查 Hadoop 是否可用:
hadoop@ubuntu:~/opt$ cd ./hadoop-2.6.0 hadoop@ubuntu:~/opt/hadoop-2.6.0$ ./bin/hadoop
成功则会显示命令用法:
Usage: hadoop [--config confdir] COMMAND
where COMMAND is one of:
fs run a generic filesystem user client
version print the version
jar <jar> run a jar file
checknative [-a|-h] check native hadoop and compression libraries availability
distcp <srcurl> <desturl> copy file or directories recursively
archive -archiveName NAME -p <parent path> <src>* <dest> create a hadoop archive
classpath prints the class path needed to get the
credential interact with credential providers
Hadoop jar and the required libraries
daemonlog get/set the log level for each daemon
trace view and modify Hadoop tracing settings
or
CLASSNAME run the class named CLASSNAME
Most commands print help when invoked w/o parameters.
Hadoop单机配置
Hadoop 默认配置是以非分布式模式运行,即单 Java 进程,方便进行调试。可以执行附带的例子 WordCount 来感受下 Hadoop 的运行。将 input 文件夹中的文件作为输入,统计当中符合正则表达式 wo[a-z.]+ 的单词出现的次数,并输出结果到 output 文件夹中。
$ cd /home/hadoop/opt/hadoop-2.6.0 $ mkdir input $ cp ./etc/hadoop/*.xml input $ ./bin/hadoop jar share/hadoop/mapreduce/hadoop-mapreduce-examples-*.jar grep input output 'wo[a-z.]+' $ cat ./output/*
执行成功后如下所示,输出了作业的相关信息,输出的结果是符合正则的单词dfsadmin出现了1次
hadoop@ubuntu:~/opt/hadoop-2.6.0$ cat ./output/*
2 word
1 work
如果需要再次运行,需要删除output文件夹(因为Hadoop 默认不会覆盖结果文件):
$ sudo rm -rf output
Hadoop伪分布式配置
Hadoop 可以在单节点上以伪分布式的方式运行,Hadoop 进程以分离的 Java 进程来运行,节点既作为 NameNode 也作为 DataNode。
Hadoop 的配置文件位于 /home/hadoop/opt/hadoop-2.6.0/etc/hadoop/ 中,伪分布式需要修改2个配置文件 core-site.xml 和 hdfs-site.xml 。
修改配置文件 core-site.xml
<configuration> <property> <name>hadoop.tmp.dir</name> <value>file:/home/hadoop/opt/hadoop-2.6.0/tmp</value> </property> <property> <name>fs.defaultFS</name> <value>hdfs://localhost:9000</value> </property> </configuration>
接着修改配置文件 hdfs-site.xml:
<configuration> <property> <name>dfs.replication</name> <value>1</value> </property> <property> <name>dfs.namenode.name.dir</name> <value>file:/home/hadoop/opt/hadoop-2.6.0/tmp/dfs/name</value> </property> <property> <name>dfs.datanode.data.dir</name> <value>file:/home/hadoop/opt/hadoop-2.6.0/tmp/dfs/data</value> </property> </configuration>
配置完成后,执行 namenode 的格式化:
hadoop@ubuntu:~/opt/hadoop-2.6.0$ bin/hdfs namenode -format
最后几行如下:
15/05/13 08:50:15 INFO namenode.FSImage: Allocated new BlockPoolId: BP-707136192-127.0.1.1-1431532215593
15/05/13 08:50:15 INFO common.Storage: Storage directory /home/hadoop/opt/hadoop-2.6.0/tmp/dfs/name has been successfully formatted.
15/05/13 08:50:16 INFO namenode.NNStorageRetentionManager: Going to retain 1 images with txid >= 0
15/05/13 08:50:16 INFO util.ExitUtil: Exiting with status 0
15/05/13 08:50:16 INFO namenode.NameNode: SHUTDOWN_MSG:
/************************************************************
SHUTDOWN_MSG: Shutting down NameNode at ubuntu/127.0.1.1
************************************************************/
接着开启 NaneNode 和 DataNode 守护进程。
hadoop@ubuntu:~/opt/hadoop-2.6.0$ sbin/start-dfs.sh
出现下面的错误提示:
Starting namenodes on [localhost]
localhost: Error: JAVA_HOME is not set and could not be found.
localhost: Error: JAVA_HOME is not set and could not be found.
Starting secondary namenodes [0.0.0.0]
解决办法:
打开hadoop-env.sh文件,修改
export JAVA_HOME=/home/hadoop/opt/jdk1.8.0_45
问题解决~~~
Starting namenodes on [localhost]
localhost: starting namenode, logging to /home/hadoop/opt/hadoop-2.6.0/logs/hadoop-hadoop-namenode-ubuntu.out
localhost: starting datanode, logging to /home/hadoop/opt/hadoop-2.6.0/logs/hadoop-hadoop-datanode-ubuntu.out
Starting secondary namenodes [0.0.0.0]
The authenticity of host '0.0.0.0 (0.0.0.0)' can't be established.
ECDSA key fingerprint is 1a:e1:fa:ce:18:2c:44:b7:0f:3b:38:fc:fd:05:8d:97.
Are you sure you want to continue connecting (yes/no)? yes
0.0.0.0: Warning: Permanently added '0.0.0.0' (ECDSA) to the list of known hosts.
0.0.0.0: starting secondarynamenode, logging to /home/hadoop/opt/hadoop-2.6.0/logs/hadoop-hadoop-secondarynamenode-ubuntu.out
启动完成后,可以通过命令 jps 来判断是否成功启动,若成功启动则会列出如下进程: NameNode、DataNode和SecondaryNameNode。(如果SecondaryNameNode没有启动,请运行 sbin/stop-dfs.sh 关闭进程,然后再次尝试启动尝试;如果 NameNode 或 DataNode 没有启动,请仔细检查之前步骤)。
hadoop@ubuntu:~/opt/hadoop-2.6.0$ jps
4576 Jps
4274 DataNode
4162 NameNode
4473 SecondaryNameNode
成功启动后,可以访问 Web 界面 http://localhost:50070 来查看 Hadoop 的信息:
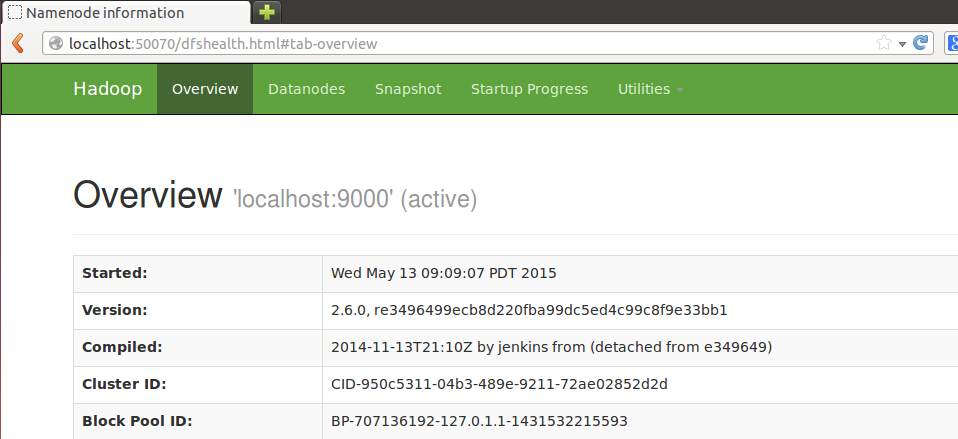
Hadoop伪分布式实例-WordCount
上面的单机模式,WordCount 读取的是本地数据,伪分布式读取的则是HDFS上的数据。要使用 HDFS,首先需要创建用户目录
hadoop@ubuntu:~/opt/hadoop-2.6.0$ bin/hdfs dfs -mkdir -p /user/hadoop
解释如下:
-mkdir [-p] <path> ... :
Create a directory in specified location.
-p Do not fail if the directory already exists
接着将 etc/hadoop 中的文件作为输入文件复制到分布式文件系统中,即将 /home/hadoop/opt/hadoop-2.6.0/etc/hadoop 复制到分布式文件系统中的 /user/hadoop/input 中。上一步已创建了用户目录 /user/hadoop ,因此命令中就可以使用相对目录如 input,其对应的绝对路径就是 /user/hadoop/input:
$ bin/hdfs dfs -mkdir input $ bin/hdfs dfs -put etc/hadoop/*.xml input
复制完成后,可以通过如下命令查看文件列表:
hadoop@ubuntu:~/opt/hadoop-2.6.0$ bin/hdfs dfs -ls input
Found 8 items
-rw-r--r-- 1 hadoop supergroup 4436 2015-05-13 18:26 input/capacity-scheduler.xml
-rw-r--r-- 1 hadoop supergroup 991 2015-05-13 18:26 input/core-site.xml
-rw-r--r-- 1 hadoop supergroup 9683 2015-05-13 18:26 input/hadoop-policy.xml
-rw-r--r-- 1 hadoop supergroup 1121 2015-05-13 18:26 input/hdfs-site.xml
-rw-r--r-- 1 hadoop supergroup 620 2015-05-13 18:26 input/httpfs-site.xml
-rw-r--r-- 1 hadoop supergroup 3523 2015-05-13 18:26 input/kms-acls.xml
-rw-r--r-- 1 hadoop supergroup 5511 2015-05-13 18:26 input/kms-site.xml
-rw-r--r-- 1 hadoop supergroup 690 2015-05-13 18:26 input/yarn-site.xml
伪分布式运行MapReduce作业的方式跟单机模式相同,区别在于伪分布式读取的是HDFS中的文件(可以将单机步骤中创建的本地 input 文件夹删掉来验证这一点)。
$ bin/hadoop jar share/hadoop/mapreduce/hadoop-mapreduce-examples-*.jar grep input output 'dfs[a-z.]+'
查看运行结果的命令(查看的是位于 HDFS 中的输出结果):
$ bin/hdfs dfs -cat output/*
也可以将运行结果取回到本地:
$ rm -R ./output $ bin/hdfs dfs -get output output # 将 HDFS 上的 output 文件夹拷贝到本机 $ cat ./output/*
结果如下:
1 dfsadmin
1 dfs.replication
1 dfs.namenode.name.dir
1 dfs.datanode.data.dir
Hadoop运行程序时,默认输出目录不能存在,因此再次运行需要执行如下命令删除 output文件夹:
$ bin/hdfs dfs -rm -r /user/hadoop/output # 删除 output 文件夹
参考资料
http://www.powerxing.com/install-hadoop/
http://hadoop.apache.org/docs/stable/hadoop-project-dist/hadoop-common/SingleCluster.html
http://www.cnblogs.com/xia520pi/archive/2012/05/16/2503949.html
http://www.micmiu.com/bigdata/hadoop/hadoop-2x-ubuntu-build/