Oracle体系结构由实例和一组数据文件组成,实例由SGA内存区,SGA意思是共享内存区,由share pool(共享池)、data buffer(数据缓冲区)、log buffer(日志缓冲区)组成
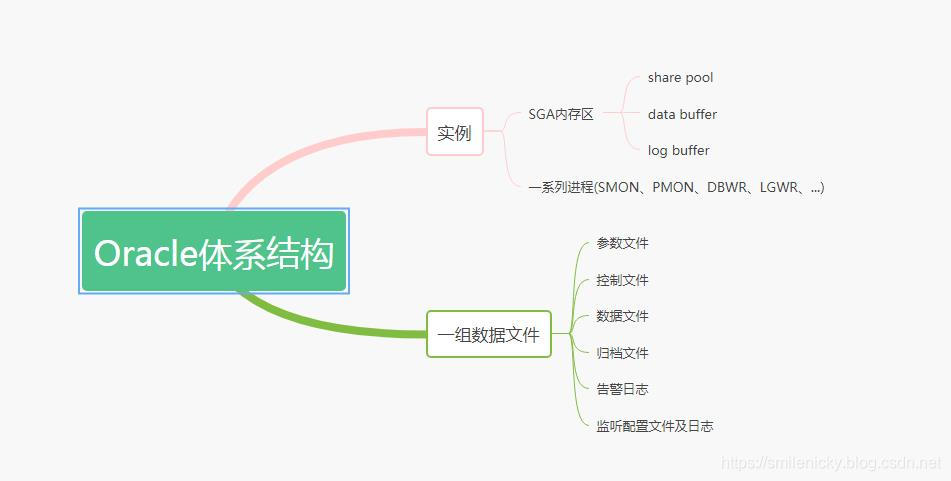
SGA内存区的share pool是解析SQL并保存执行计划的,然后SQL根据执行计划获取数据时先看data buffer里是否有数据,没数据才从磁盘读,然后还是读到data buffer里,下次就直接读data buffer的,当SQL更新时,data buffer的数据就必须写入磁盘备份,为了保护这些数据,才有log buffer,这就是大概的原理简介
系统结构关系图如图,图来自《收获,不止SQL优化》一书: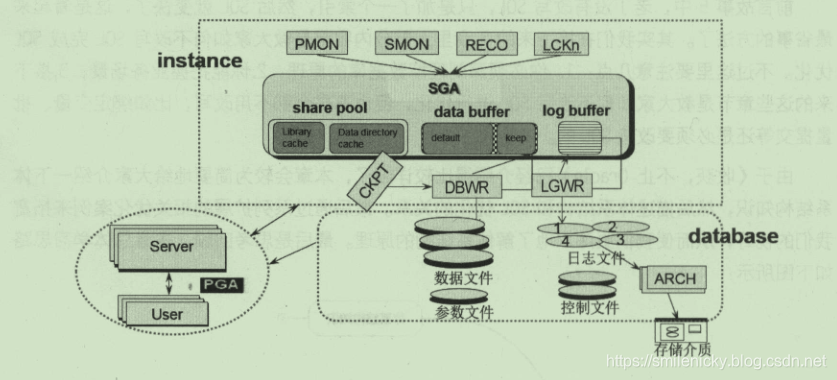
下面介绍共享池、数据缓冲、日志缓冲方面调优的例子
共享池相关例子
未使用使用绑定变量的情况,进行一下批量写数据,在登录系统,经常用的sql是select * from sys_users where username='admin'或者什么什么的,假如有很多用户登录,就需要执行很多次这样类似的sql,能不能用一条SQL代表?意思是不需要Oracle优化器每次都解析sql获取执行计划,对于这种类似的sql是没必要的,Oracle提供了绑定变量的方法,可以用于调优sql,然后一堆sql就可以用
select * from sys_users where username=:x
这里用一个变量x表示,具体例子如下,
新建一张表来测试
create table t (x int);
不使用绑定遍历,批量写数据
begin
for i in 1 .. 1000
loop
execute immediate
'insert into t values('|| i ||')';
commit;
end loop;
end;
/
输出
已用时间: 00: 00: 00.80
加上绑定遍历,绑定变量是用:x的形式
begin
for i in 1 .. 100
loop
execute immediate
'insert into t values( :x )' using i;
commit;
end loop;
end;
/
已用时间: 00: 00: 00.05
数据缓冲相关例子
这里介绍和数据缓存相关例子
(1) 清解析缓存
//创建一个表来测试
SQL> create table t as select * from dba_objects;
表已创建。
//设置打印行数
SQL> set linesize 1000
//设置执行计划开启
SQL> set autotrace on
//打印出时间
SQL> set timing on
//查询一下数据
SQL> select count(1) from t;
COUNT(1)
----------
72043
已用时间: 00: 00: 00.10
//清一下缓冲区缓存(ps:这个sql不能随便在生产环境执行)
SQL> alter system flush buffer_cache;
系统已更改。
已用时间: 00: 00: 00.08
//清一下共享池缓存(ps:这个sql不能随便在生产环境执行)
SQL> alter system flush shared_pool;
//再次查询,发现查询快了
SQL> select count(1) from t;
COUNT(1)
----------
72043
已用时间: 00: 00: 00.12
SQL>
日志缓冲相关例子
这里说明一下,日志关闭是可以提供性能的,不过在生生产环境还是不能随便用,只能说是一些特定创建,SQL如:
alter table [表名] nologging;
调优拓展知识
这些是看《收获,不止SQL优化》一书的小记
(1) 批量写数据事务问题
对于循环批量事务提交的问题,commit放在循环内和放在循环外的区别,
放在循环内,每次执行就提交一次事务,这种时间相对比较少的
begin
for i in 1 .. 1000
loop
execute immediate
'insert into t values('|| i ||')';
commit;
end loop;
end;
放在循环外,sql循环成功,再提交一次事务,这种时间相对比较多一点
begin
for i in 1 .. 1000
loop
execute immediate
'insert into t values('|| i ||')';
end loop;
commit;
end;
《收获,不止SQL优化》一书提供的脚本,用于查看逻辑读、解析、事务数等等情况:
select s.snap_date,
decode(s.redosize, null, '--shutdown or end--', s.currtime) "TIME",
to_char(round(s.seconds / 60, 2)) "elapse(min)",
round(t.db_time / 1000000 / 60, 2) "DB time(min)",
s.redosize redo,
round(s.redosize / s.seconds, 2) "redo/s",
s.logicalreads logical,
round(s.logicalreads / s.seconds, 2) "logical/s",
physicalreads physical,
round(s.physicalreads / s.seconds, 2) "phy/s",
s.executes execs,
round(s.executes / s.seconds, 2) "execs/s",
s.parse,
round(s.parse / s.seconds, 2) "parse/s",
s.hardparse,
round(s.hardparse / s.seconds, 2) "hardparse/s",
s.transactions trans,
round(s.transactions / s.seconds, 2) "trans/s"
from (select curr_redo - last_redo redosize,
curr_logicalreads - last_logicalreads logicalreads,
curr_physicalreads - last_physicalreads physicalreads,
curr_executes - last_executes executes,
curr_parse - last_parse parse,
curr_hardparse - last_hardparse hardparse,
curr_transactions - last_transactions transactions,
round(((currtime + 0) - (lasttime + 0)) * 3600 * 24, 0) seconds,
to_char(currtime, 'yy/mm/dd') snap_date,
to_char(currtime, 'hh24:mi') currtime,
currsnap_id endsnap_id,
to_char(startup_time, 'yyyy-mm-dd hh24:mi:ss') startup_time
from (select a.redo last_redo,
a.logicalreads last_logicalreads,
a.physicalreads last_physicalreads,
a.executes last_executes,
a.parse last_parse,
a.hardparse last_hardparse,
a.transactions last_transactions,
lead(a.redo, 1, null) over(partition by b.startup_time order by b.end_interval_time) curr_redo,
lead(a.logicalreads, 1, null) over(partition by b.startup_time order by b.end_interval_time) curr_logicalreads,
lead(a.physicalreads, 1, null) over(partition by b.startup_time order by b.end_interval_time) curr_physicalreads,
lead(a.executes, 1, null) over(partition by b.startup_time order by b.end_interval_time) curr_executes,
lead(a.parse, 1, null) over(partition by b.startup_time order by b.end_interval_time) curr_parse,
lead(a.hardparse, 1, null) over(partition by b.startup_time order by b.end_interval_time) curr_hardparse,
lead(a.transactions, 1, null) over(partition by b.startup_time order by b.end_interval_time) curr_transactions,
b.end_interval_time lasttime,
lead(b.end_interval_time, 1, null) over(partition by b.startup_time order by b.end_interval_time) currtime,
lead(b.snap_id, 1, null) over(partition by b.startup_time order by b.end_interval_time) currsnap_id,
b.startup_time
from (select snap_id,
dbid,
instance_number,
sum(decode(stat_name, 'redo size', value, 0)) redo,
sum(decode(stat_name,
'session logical reads',
value,
0)) logicalreads,
sum(decode(stat_name,
'physical reads',
value,
0)) physicalreads,
sum(decode(stat_name, 'execute count', value, 0)) executes,
sum(decode(stat_name,
'parse count (total)',
value,
0)) parse,
sum(decode(stat_name,
'parse count (hard)',
value,
0)) hardparse,
sum(decode(stat_name,
'user rollbacks',
value,
'user commits',
value,
0)) transactions
from dba_hist_sysstat
where stat_name in
('redo size',
'session logical reads',
'physical reads',
'execute count',
'user rollbacks',
'user commits',
'parse count (hard)',
'parse count (total)')
group by snap_id, dbid, instance_number) a,
dba_hist_snapshot b
where a.snap_id = b.snap_id
and a.dbid = b.dbid
and a.instance_number = b.instance_number
order by end_interval_time)) s,
(select lead(a.value, 1, null) over(partition by b.startup_time order by b.end_interval_time) - a.value db_time,
lead(b.snap_id, 1, null) over(partition by b.startup_time order by b.end_interval_time) endsnap_id
from dba_hist_sys_time_model a, dba_hist_snapshot b
where a.snap_id = b.snap_id
and a.dbid = b.dbid
and a.instance_number = b.instance_number
and a.stat_name = 'DB time') t
where s.endsnap_id = t.endsnap_id
order by s.snap_date, time desc;