(1)HyperLogLog简介
在Redis 在 2.8.9 版本才添加了 HyperLogLog,HyperLogLog算法是用于基数统计的算法,每个 HyperLogLog 键只需要花费 12 KB 内存,就可以计算接近 2^64 个不同元素的基数。HyperLogLog适用于大数据量的统计,因为成本相对来说是更低的,最多也就占用12kb内存
业务场景,HyperLogLog常用于大数据量的统计,比如页面访问量统计或者用户访问量统计
举个例子,假如要统计一个页面的访问量(PV),这个还比较好办,可以直接用redis计数器或者直接存数据库都可以做,然后如果再加需求,现在要统计一个页面的用户访问量(UV),一个用户一天内如果访问多次的话,也只能算一次,这样的话,你可能会想到用SET集合来做,因为SET集合是有去重功能的,key存储页面对应的关键字,value存储对应userId,这种方法是可行,可是访问量一多的话,假如有几千万访问量,那就麻烦了,为了统计一个访问量,要频繁创建SET集合对象
那有其它方法吗?针对上面大访问量的情况,redis是有实现了HyperLogLog算法,HyperLogLog 这个数据结构的发明人 是Philippe Flajolet 教授
Redis集成的HyperLogLog使用语法主要有pfadd和pfcount,顾名思义,一个是来添加数据,一个是来统计的,使用比较容易掌握,不过算法是比较复杂的,然后为什么用pf?是因为HyperLogLog 这个数据结构的发明人 是Philippe Flajolet教授 ,所以用发明人的英文缩写,这样我们也容易记住这个语法了
下面给出一些简单例子,启动redis客户端
127.0.0.1:6379> flushall
OK
127.0.0.1:6379> pfadd uv user1
(integer) 1
127.0.0.1:6379> pfcount uv
(integer) 1
127.0.0.1:6379> pfadd uv user2
(integer) 1
127.0.0.1:6379> pfcount uv
(integer) 2
127.0.0.1:6379> pfadd uv user3
(integer) 1
127.0.0.1:6379> pfcount uv
(integer) 3
127.0.0.1:6379> pfadd uv user4
(integer) 1
127.0.0.1:6379> pfcount uv
(integer) 4
127.0.0.1:6379> pfadd uv user5 user6 user 7 user8 user9 user10
(integer) 1
127.0.0.1:6379> pfcount uv
(integer) 10
127.0.0.1:6379>
然后用java的Jedis库来实现
加上Maven:
<dependencies>
<dependency>
<groupId>redis.clients</groupId>
<artifactId>jedis</artifactId>
<version>2.9.0</version>
</dependency>
</dependencies>
写个测试类,要先启动redis服务端
package com.test.redis;
import redis.clients.jedis.Jedis;
public class RedisPFCountTest {
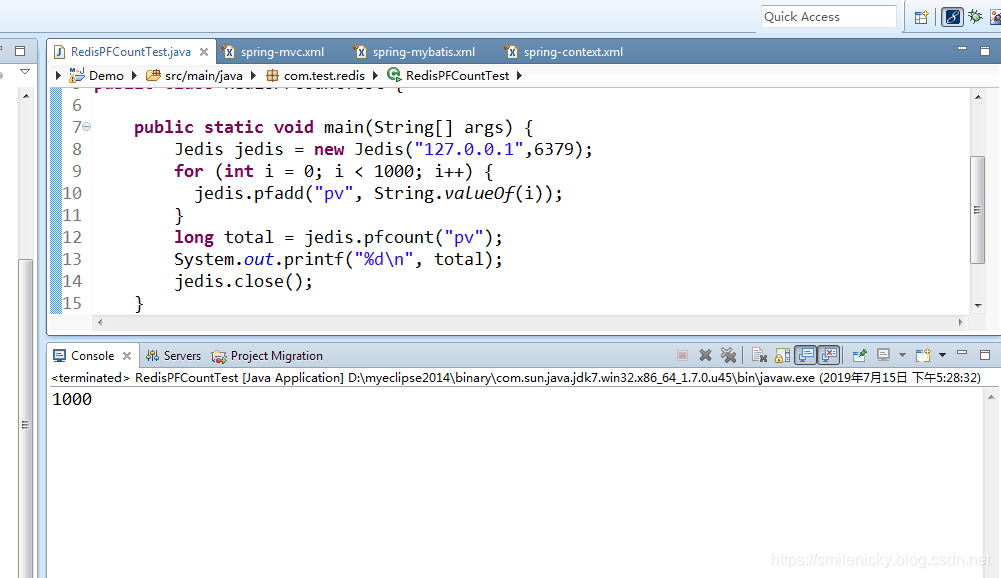
public static void main(String[] args) {
Jedis jedis = new Jedis("127.0.0.1",6379);
for (int i = 0; i < 1000; i++) {
jedis.pfadd("pv", String.valueOf(i));
}
long total = jedis.pfcount("pv");
System.out.printf("%d
", total);
jedis.close();
}
}
再加大数据量,这里写了10万次的统计,可以看出是有一点误差的
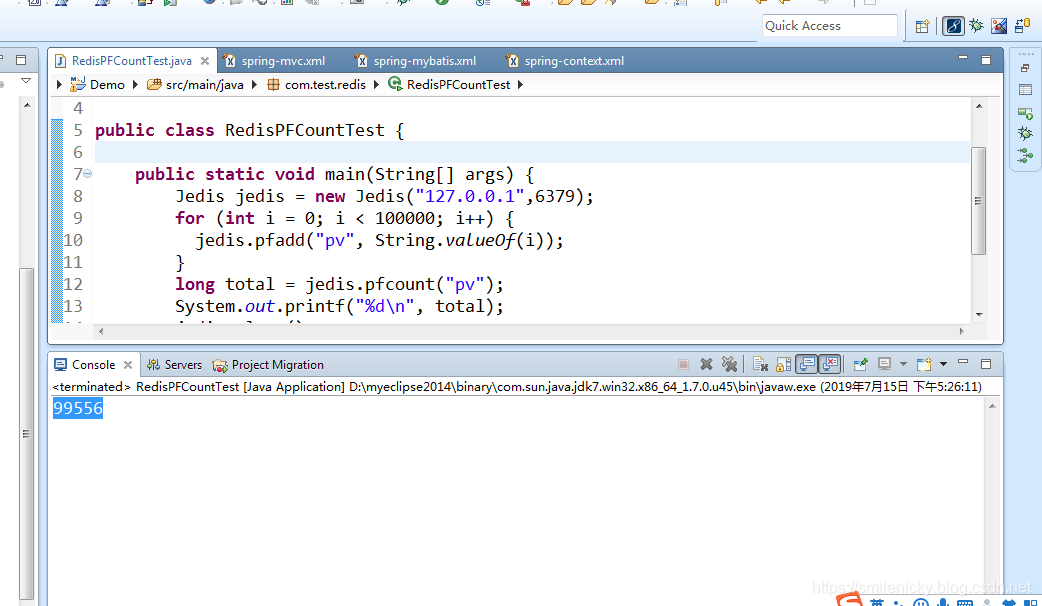
当然HyperLogLog算法一开始就是为了大数据量的统计而发明的,所以很适合那种数据量很大,然后又没要求不能有一点误差的计算,HyperLogLog 提供不精确的去重计数方案,虽然不精确但是也不是非常不精确,标准误差是 0.81%,不过这对于页面用户访问量是没影响的,因为这种统计可能是访问量非常巨大,但是又没必要做到绝对准确,访问量对准确率要求没那么高,但是性能存储方面要求就比较高了,而HyperLogLog正好符合这种要求,不会占用太多存储空间,同时性能不错
(2) PFMERGE 用法
pfadd和pfcount常用于统计,然后来个需求,假如两个页面很相近,现在想统计这两个页面的用户访问量呢?这里就可以用pfmerge合并统计了,语法如例子:
127.0.0.1:6379> PFADD test1 "apple" "banana" "cherry"
(integer) 1
127.0.0.1:6379> PFCOUNT test1
(integer) 3
127.0.0.1:6379> PFADD test2 "apple" "cherry" "durian" "mongo"
(integer) 1
127.0.0.1:6379> PFCOUNT test2
(integer) 4
127.0.0.1:6379> PFMERGE test1&test2 test1 test2
OK
127.0.0.1:6379> PFCOUNT test1&test2
(integer) 5