一、梗概:
源于Google GFS论文(03年)。
Master - Slave 模式
优点:
超大文件
高容错
适合大数据的批处理(流式访问)
缺点:
高延时访问
小文件存储(元信息,寻道时间大)
不能多用户写,文件不能随机修改,只能追加(不支持并发写入,只能一个线程写入)
数据块blcok:
操作系统也是有 块、簇 的概念,是一种逻辑上的单位(而向磁盘上的扇区单件则是物理上的真实存在的);
块的目的是便于系统管理,不便于使用太小的单位进行寻址;
HDFS中block为何这么大:因为存储的文件很大,便于管理;主要是为了减小守址开销;
也不宜太大,因为通常MR中一个block对于一个map任务,太小不能充分利用其并行处理;
--------------------------------
二、 角色:
Client:
切分文件为block;(一个文件一般占用150B)
获取文件信息(与NameNode交互)
读取文件数据(与DataNode交互)
通过一些接口管理HDFS
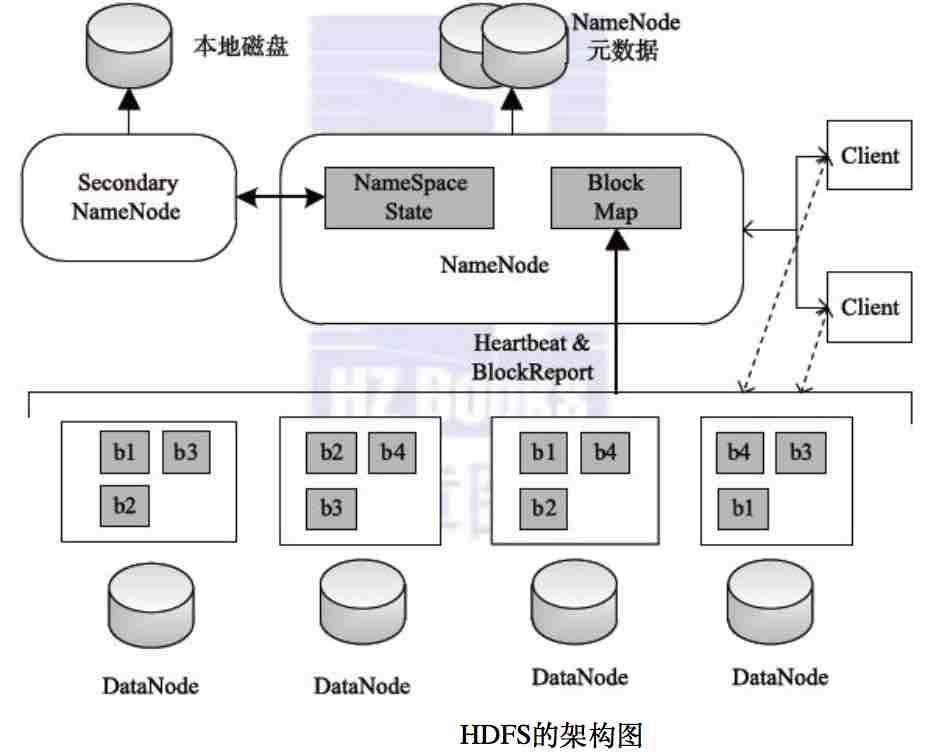
NameNode:
管理文件系统命名空间,存储文件元信息;
文件块的映射,但它并不永久保存块的位置信息,因为这些信息会在系统启动时由数据节点重建;
处理Client的读写请求;
DataNode:
数据的存储;
执行Client的读写操作;
向NameNode汇报状态;
Secondary NameNode:(2.0已弃用,被HA替代)
辅助NameNode,分担其工作量;
定期合并fsimage和fsedits,并推送给NameNode;
紧急情况下,可辅助恢复NameNode;
1.0架构图:
--------------------------------
三、实现HA的两种方式:
NFS ( Network File System ),QJM ( Quorum Journal Manager )
2.0后引进,解决SPOF 单节点故障
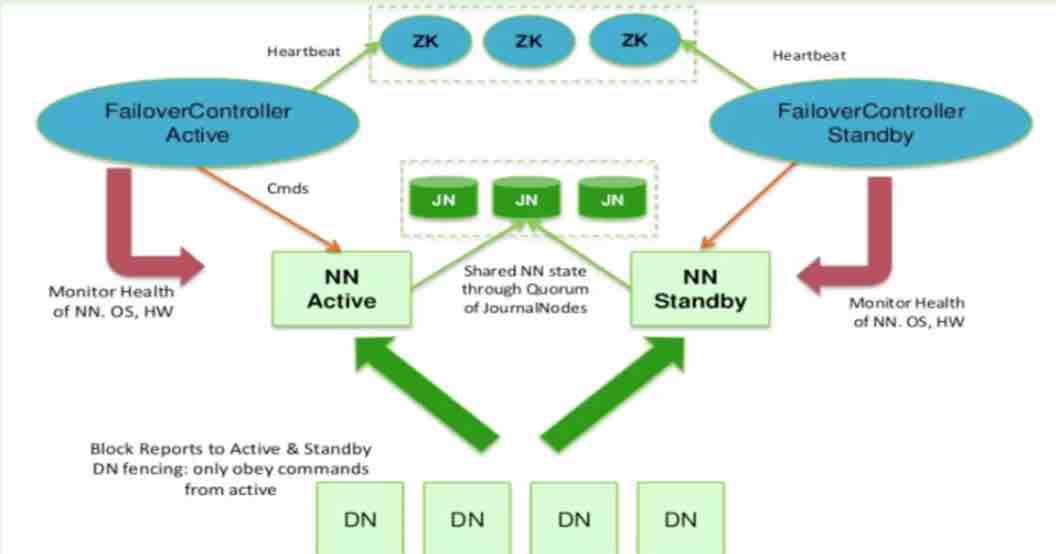
QJM:
In a typical HA cluster, two separate machines are configured as NameNodes. At any point in time, exactly one of the NameNodes is in an Active state, and the other is in a Standby state. The Active NameNode is responsible for all client operations in the cluster, while the Standby is simply acting as a slave, maintaining enough state to provide a fast failover if necessary.
In order for the Standby node to keep its state synchronized with the Active node, both nodes communicate with a group of separate daemons called "JournalNodes" (JNs). When any namespace modification is performed by the Active node, it durably logs a record of the modification to a majority of these JNs. The Standby node is capable of reading the edits from the JNs, and is constantly watching them for changes to the edit log. As the Standby Node sees the edits, it applies them to its own namespace. In the event of a failover, the Standby will ensure that it has read all of the edits from the JounalNodes before promoting itself to the Active state. This ensures that the namespace state is fully synchronized before a failover occurs.
In order to provide a fast failover, it is also necessary that the Standby node have up-to-date information regarding the location of blocks in the cluster. In order to achieve this, the DataNodes are configured with the location of both NameNodes, and send block location information and heartbeats to both.
It is vital for the correct operation of an HA cluster that only one of the NameNodes be Active at a time. Otherwise, the namespace state would quickly diverge between the two, risking data loss or other incorrect results. In order to ensure this property and prevent the so-called "split-brain scenario," the JournalNodes will only ever allow a single NameNode to be a writer at a time. During a failover, the NameNode which is to become active will simply take over the role of writing to the JournalNodes, which will effectively prevent the other NameNode from continuing in the Active state, allowing the new Active to safely proceed with failover.
NFS:
In order for the Standby node to keep its state synchronized with the Active node, the current implementation requires that the two nodes both have access to a directory on a shared storage device (eg an NFS mount from a NAS). This restriction will likely be relaxed in future versions.
以上HA需要解决3个问题:
同步文件系统命名空间、元信息的修改;
datanode需向两个节点汇报状态;
保证只有一个ActivityNameNode,只有一个能写入NFS或JN;
2.0架构图:
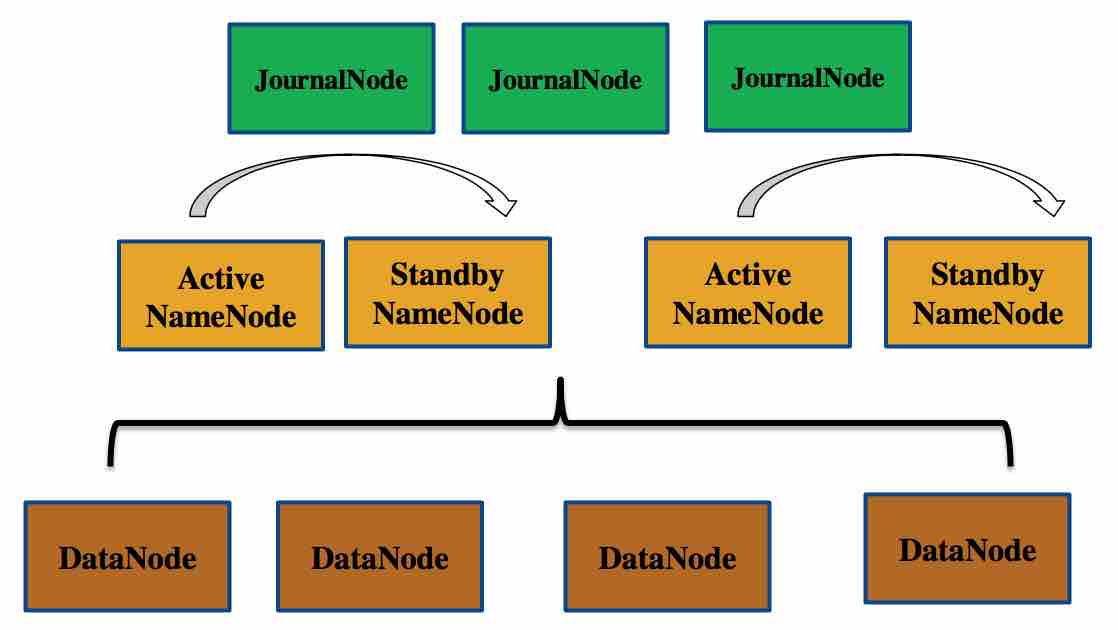
HA 高可用相关节点:(QJM)
ActiveNameNode
StandbyNameNode
JournalNode
Note: There must be at least 3 JournalNode daemons, since edit log modifications must be written to a majority of JNs. This will allow the system to tolerate the failure of a single machine. You may also run more than 3 JournalNodes, but in order to actually increase the number of failures the system can tolerate, you should run an odd number of JNs, (i.e. 3, 5, 7, etc.). Note that when running with N JournalNodes, the system can tolerate at most (N - 1) / 2 failures and continue to function normally.
--------------------------------
四、Federation:
(2.0后引进,解决文件扩展问题)多套 ActiveNameNode 和 StandbyNameNode的组合;
单台namenode内存保存整个文件信息,当有大量文件时,单节点内存就会成为横向扩展文件的瓶颈,Federation即可解决这个问题。
在Federation环境下,每个namenode维护一个命名卷(namespace volume)。命令空间卷之间是相与独立的,两两之间不相互通信。共用数据块池,因此集群中的datanode需要注册到每个namenode。
整体集群架构:
--------------------------------
五、数据读写过程:
读流程图:

读取过程:
a. 首先客户端从 NameNode获取第一批block的位置信息。(同一个block会根据副本数返回多个位置)
b. 客户端根据block位置信息,根据拓扑结构排序,优化选择近的位置;
c. 客户端从block所在最近位置读取数据,然后读取下一个块;直到读完第一批中所有块,然后再重复获取下一批,循环直到所有数据读取完成;
写流程图:

写过程:
a. 客户端申请创建一个文件,通过NameNode创建一个没有block关联的文件;(NameNode会创建前会先较验,比如是否存在,是否有权限等;读过程也如此)
b. 客户端将文件规划为多个block,每个block又划分为packet排成data queue;客户端会询问NameNode一个块存放在哪几个节点上;然后将返回的几个节点排成pipeline;
c. 客户端向第一个DataNode中写入数据,然后DataNode又后向下一个DataNode通过pipeline写入,依次执行;并且DataNode通过ack packet反馈写数据情况,当收到最后一个ack packet后,通知DataNode标示为已完成;
--------------------------------
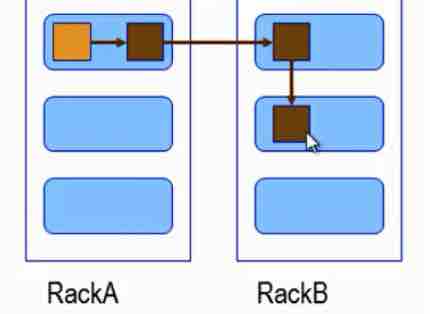
六、文件副本复制策略:
0.17后:
1、同Client的节点上;
2:不同机架上节点上;
3:不同机架上另一个节点上;