豆瓣电影
1. 分析
分析流程图
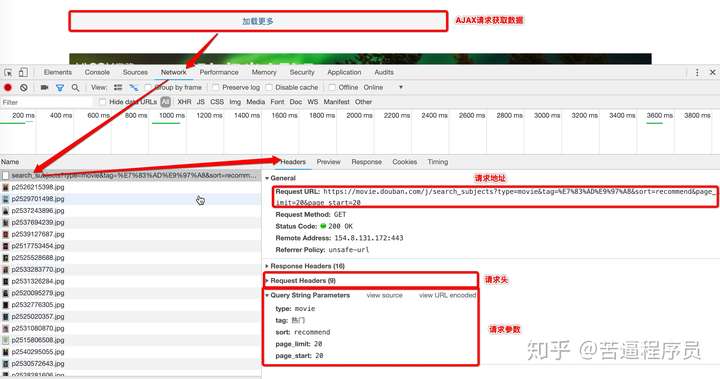
分析结果
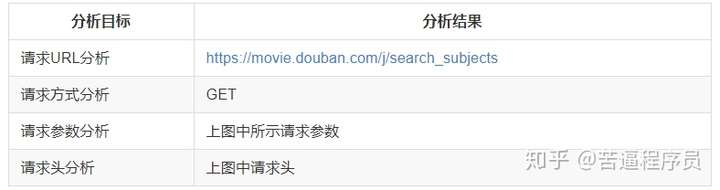
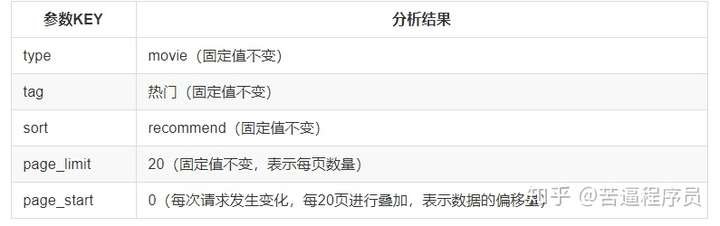
请求头一般都是先放User-Agent,如果爬取失败再补Referer,还是失败就再补Cookie,如果喜欢稳一点的,可以每次都加上
代码实现流程分析
- 先完成一次请求的抓取
- 再完成多次请求的爬取
- 总结:
- python高薪就业(视频、学习路线、免费获取)www.jianshu.com
循序渐进养成良好的习惯
代码
#!/usr/bin/python3
# -*- coding: utf-8 -*-
import requests
import json
# 定义请求url
url = "https://movie.douban.com/j/search_subjects"
# 定义请求头
headers = {
"User-Agent": "Mozilla/5.0 (Macintosh; Intel Mac OS X 10_14_0) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/70.0.3538.110 Safari/537.36"
}
# 循环构建请求参数并且发送请求
for page_start in range(0, 100, 20):
params = {
"type": "movie",
"tag": "热门",
"sort": "recommend",
"page_limit": "20",
"page_start": page_start
}
response = requests.get(
url=url,
headers=headers,
params=params
)
# 方式一:直接转换json方法
# results = response.json()
# 方式二: 手动转换
# 获取字节串
content = response.content
# 转换成字符串
string = content.decode('utf-8')
# 把字符串转成python数据类型
results = json.loads(string)
# 解析结果
for movie in results["subjects"]:
print(movie["title"], movie["rate"])