毕业季加上疫情的影响,最近为了找工作发愁的人肯定不在少数。你通常怎么寻找岗位?
提供招聘信息的网站有许多,且涉及不同领域。即使你处于某一职位,也应该在不停物色其他工作,而这个过程可能会很无聊。很可能翻遍一个网站也一无所获,搜索功能有时也不是那么么好用,
本文将介绍一个简单的解决方案,告别人工筛选,Python帮你找到合适的岗位,还可依据个人喜好对其进行过滤。这是Python的一个简单应用,无需任何特定技能就能完成。快来看看吧!


规划流程
首先,找到招聘网站。笔者选择了一个名为“Indeed”的网站。接着筛选出符合条件的工作,并对结果进行抓取。
这是笔者搜索“美国”(UnitedStates)的“数据科学”(DataScience)职位后,Indeed网站所呈现的结果。
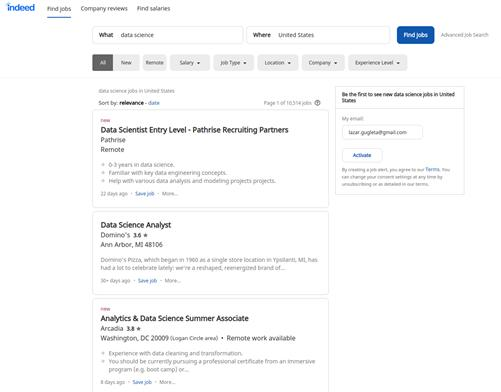
最后再将获得的数据打包到数据框中,得到一个CSV文件,可以使用Excel或LibreOffice轻松打开。

环境设置
接下来的工作需要安装ChromeDriver,并和 Selenium一起使用,这样就能够操控浏览器,向其发送命令以供测试和使用。打开链接并下载适合操作系统的文件。笔者推荐最新版本,会更稳定一些。
接下来,解压该文件。进入文件,通过右键单击手动操作,然后点击“解压到此处”(Extract Here)。python交流裙:点击进入,免费领取学习资料大全适合在校大学生,小白,想转行,想通过这个找工作的加入。裙里有大量学习资料,有大神解答交流问题
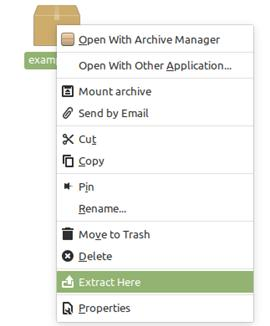
文件夹中存在一个名为“chromedriver”的文件,将其移到计算机上的一个特定文件夹中。
打开终端,键入以下命令:
sudo su #enter the root mode
cd #go back to base from thecurrent location
mv /home/*your_pc_name*/Downloads/chromedriver /usr/local/bin
#move the file to the right location
输入计算机的实际名称,而不是*your_pc_name*。
要运行程序,还需要其他几个库。该终端中,应该安装这些:
pip3 install pandas
Pandas是一个快速、强大、灵活且易于使用的开源数据分析和操作工具,构建在Python编程语言之上。
sudo pip3 install beautifulsoup4
Beautiful Soup是一个Python库,用于从HTML、XML和其他标记语言中获取数据。
完成后,打开编辑器。笔者选择的是Visual Studio Code。它简单易用,可自定义,且在计算机中占用内存小。
在任意位置打开一个新项目并创建两个新文件。以下为项目图例,以帮助读者顺利完成这一操作:
在VS代码中,有一个“终端”(Terminal)标签,可以用它打开一个内部终端,有助于把所有东西放在一个地方。
打开终端后,还需安装虚拟环境和selenium,用于网络驱动程序。将以下命令键入终端。
pip3 install virtualenv
source venv/bin/activate
pip3 install selenium
激活虚拟环境后,就一切准备就绪了。
创建工具
万事俱备,现在开始编码!
首先,如前所述,须导入已安装的库。
from selenium importwebdriver
import pandas as pd
from bs4 import BeautifulSoup
from time import sleep
任何名称都可以创建工具,然后启动Chrome的驱动程序。
class FindJob():
def __init__(self):
self.driver = webdriver.Chrome()
这就是开发所需的全部内容。现在进入终端并键入:
python -i findJob.py
该命令把文件当作一个互动场。它将打开浏览器的新标签。现在可以开始发出命令了。可使用命令行进行实验,而非直接输入到源文件。但要使用bot而非self。
对终端执行以下命令:
bot = FindJob()
bot.driver.get('https://www.indeed.com/jobs?q=data+science&l=United+States&start=')
对源代码执行以下命令:
self.driver.get('https://www.indeed.com/jobs?q=data+science&l=United+States&start=')
从创建要使用的数据框架开始。对于这个数据框架,需存在工作相关信息,包括“职位名称”(Title)、“地点” (Location)、“公司” (Company)、“薪水” (Salary)、“描述” (Description)等。
dataframe = pd.DataFrame(
columns=["Title","Location", "Company", "Salary","Description"])
将该数据框架作为CSV文件的列名。
这个网站的特点是每一页都有10份工作岗位,进入下一页时链接会发生变化。基于这一特征,笔者做了一个for循环检查每一页,完成后会进入下一页:
for cnt in range(0, 50, 10):
self.driver.get("https://www.indeed.com/jobs?q=data+science&l=United+States&start="+ str(cnt))
设置一个计数器变量“cnt”,添加该数字,转换成字符串至链接。for循环从0开始到50,并在10次迭代中完成,因为这是每页显示的工作数量。
进入首页,需逐一抓取工作邀请。工作邀请被打包在一个表格中,按下键盘上的F12,或右键单击->检查,找到该表格。这是表格界面:

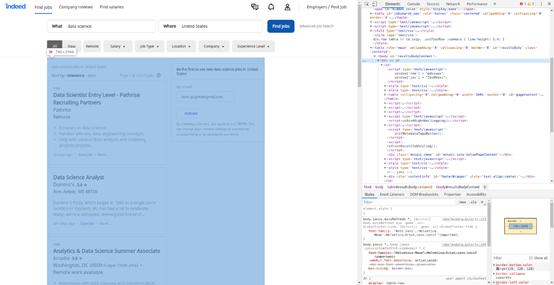
通过类别名找到该表,并输入以下行:
jobs =self.driver.find_elements_by_class_name('result')
这一操作将保存根据类别名结果找到的所有网页元素。保存后,就可以创建另一个for循环,查找表中的每个元素并使用里面的数据。
在展示更多抓取工作邀请的代码前,你还需要了解一些事情。这一部分使用BeautifulSoup ,它的工作速度更快。必须设置BeautifulSoup的一些内容,这些是提供的实际数据,用于执行搜索和解析:
result =job.get_attribute('innerHTML')
soup = BeautifulSoup(result, 'html.parser')
完成后,只需在‘soup’定义的变量中找到元素,一个BeautifulSoup准备的数据。
获得所需数据框架的数据:
title = soup.find("a",class_="jobtitle").text.replace(' ', '')
location = soup.find(class_="location").text
employer = soup.find(class_="company").text.replace(' ', '').strip()
try:
salary =soup.find(class_="salary").text.replace(
' ', '').strip()
except:
salary = 'None'
以该方式完成工资部分,因为有时它没有定义,必须为特定的单元格设置“无”或“空”。笔者在终端上测试代码,读者也可以打印出目前为止找到的内容:
print(title, location, employer,salary)
完成的脚本如下所示:

数据框架构建的最后一件尚未完成的是工作描述,而单独留出来是因为,想要获得工作描述的文本,就必须先单击工作邀请。笔者是这样做的:
summ =job.find_elements_by_class_name("summary")[0]
summ.click()
job_desc = self.driver.find_element_by_id('vjs-desc').text
得到所有应进入数据框架的元素之后,将其填充:
dataframe = dataframe.append(
{'Title': title, 'Location': location,'Employer': employer, 'Description': job_desc}, ignore_index=True)
此外一旦进入网站的第二页,就会出现一个弹出窗口,阻止用户点击任何内容。于是笔者创建了一个try-expect,它将关闭弹出窗口并继续抓取数据。
pop_up =self.driver.find_element_by_xpath('/html/body/table[2]/tbody/tr/td/div[2]/div[2]/div[4]/div[3]/div[2]/a')pop_up.click()
for循环结束后,将数据帧数据复制到名为“工作”的CSV中:
dataframe.to_csv("jobs.csv",index=False)

跟着操作一遍吧,祝你拿到心仪的offer!

留言点赞关注
我们一起分享AI学习与发展的干货
如转载,请后台留言,遵守转载规范