redis介绍及特点
Redis是由意大利人Salvatore Sanfilippo开发的一款内存内存高速缓存数据库。
Reids全称为:Remote Dictionary Server(远程数据服务),该软件使用C语言编写,典型的NoSQL数据库服务器。是一个nosql(非关系式数据库),key-value,可持久化,内存,分布式的,缓存的数据库;
结构化数据:有规律的一类数据;例如:人的信息,动物信息,考试信息
非结构化数据:海量的不具备任何共同特性的数据集合;例如:网页,日志;图片
关系型数据库:体现不同类结构化数据之间的关系的数据,例如ORACLE mysql
非关系型数据库:存储的是非结构化的海量数据;无法体现数据的关系;例如 mongoDB redis
key-value: 目前阶段,非关系型数据库使用的存储数据的格式
可持久化内存
服务器存储的介质,只有2个,一个是磁盘(可靠性高,速度慢),一个是内存(速度快,可靠性低);由于内存数据在断电,宕机后数据消失,访问缓存时造成数据未命中,出现一定范围的数据未命中,将会导致缓存的雪崩/缓存击穿
redis具有持久化数据到磁盘的能力,将内存数据在写入之后按照一定规格存储在磁盘文件中,宕机,断电后可以启动redis是读取磁盘的文件恢复缓存数据;
Redis本质上是一个Key-Value类型的内存数据库,整个数据库统统加载在内存中进行操作,定期通过异步操作把数据库数据flush到硬盘上进行保存。因为是纯内存操作,Redis的性能非常出色,每秒可以处理十万次读写操作,是已知性能最快的Key-Value DB。
存储的数据结构
Reids的出色之处不仅仅是性能,Redis最大魅力是支持保存多种数据结构,此外单个value的最大限制是1GB,另外Redis也可以对存入的Key-Value设置expire时间。
Redis的主要特点是数据库容量收到物理内存的限制,不能用作海量数据的高性能读写,因此Reids适合的场景主要局限在较小数据量的高性能操作和运算上。
分布式
分布式集群;
分布式:当个任务被多个节点切分处理,叫做分布式处理一个任务;
集群:一批节点在同时处理一个或多个任务;
redis的分布式:单个服务器内存,磁盘空间有限,无法处理海量的缓存数据,必须支持分布式的结构,这样就解决了Reids不能用作海量数据的高性能读写;
缓存
缓存的逻辑在SSM框架中的使用;
数据库缓存:
sql语句是key值,查询结果resultSet是value,当同一个查询语句访问时(select * from t_product),只要曾经查过,调用缓存直接返回resultSet,节省了数据库技术读取磁盘数据的时间;
持久层缓存:
减少了连接数据库的时间;减少了resultSet封装成对象的过程;
业务层和控制的缓存:
减少调用层次;
描述缓存在业务层的逻辑;
查询商品信息;
判断当前查询在缓存是否有数据
§ 如果有数据,直接返回,当前请求结束
§ 如果没有数据,查询持久层数据库数据,获取数据存储在缓存一份,供后续访问使用;
缓存雪崩/缓存击穿
海量请求访问服务器,服务器的性能由缓存支撑,一旦一定范围的缓存数据未命中,请求的数据访问涌入数据库;承受不了压力造成宕机--重启--海量请求并未消失--宕机--重启,系统长时间不可用;这种情况就是缓存的雪崩.
面试题
1.为什么redis需要把所有的数据放到内存中??
Redis为了达到最快的读写速度将数据都读到内存中,并通过异步的方式将数据写入磁盘。所以redis具有快速和数持久化的特征。如果不将数据放在内存中,磁盘I/O速度为严重影响redis的性能。在内存越来越便宜的今天,redis将会越来越受欢迎,如果设置最大使用的内存,则已有数据记录达到内存限制后不能继续插入新值。
2.redis存储的数据类型有哪些?
redis具备五种数据类型String,Hash,List,Set,Zset。
3.Redis常见的性能问题都有哪些?如何解决?
- Master写内存快照,save命令调度rdbSave函数,会阻塞主线程的工作,当快照比较大时对性能影响是非常大的,会间断性的暂停服务,所以Master最好不要写内存快照。
- Master AOF持久化,如果不重写AOF文件,这个持久化方式对性能的影响是最小的,但是AOF文件会不断增大,AOF文件过大会影响Master重启恢复速度。Master最好不要做任何持久化工作,包括内存快照和Aof日志文件,特别是不要启动内存快照做持久化操作如果数据比较关键某个Slave开启AOF备份数据,策略为每秒同步一次。
- Master调用BGREWRITEAOF重写AOF文件,AOF在重写的时候会占用大量的CPU和内存资源,导致服务load过高,出现短暂暂停服务现象。
- Redis主从复制的性能问题,为了主从复制的速度和连接的稳定性,Salve和Master最好在一个局域网内
4.Reids最合适的场景有哪些?
会话缓存、全页缓存、队列、排行榜/计数器、发布/订阅
5、Reids的优缺点
优点:
- 性能极高-redis能支持超多100k+的每秒读写频率。
- 丰富的数据类型-Reids支持二进制案例的String,Lists、等数据类型操作
- 原子-Redis的所有操作都是原子性的,同时Redis还支持对几个操作全并后的原子性执行
- 丰富的特性-Reids还支持publish/subscribe,通知,key过期等特性
缺点:
- 由于是内存数据库,所以,单台机器,存储的数据量,根机器本身的内存大小。虽然Redis本身有内存过期策略,但是还是要提前预估和节约内存。如果内存增长过快,需要定期删除数据
- 如果进行完整重同步,由于需要生成rdb文件,并进行传输,会占用主机的CPU,并会消耗线网的带宽。
- 修改配置文件,进行重启,将硬盘中的数据加载进内存,时间比较久。在这个过程中,redis不能提供服务。
6、redis的持久化方式
RDB持久化和AOF持久化
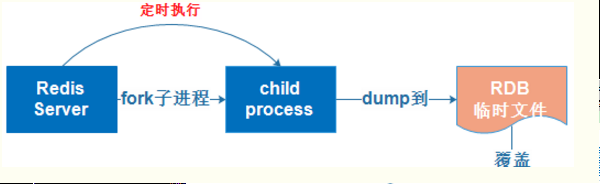
RDB持久化是指在再指定的时间间隔内将内存中的数据集快照写入硬盘,实际的操作过程是fork一个字进程,先将数据集写入临时文件,写入成功后,在替换之前的文件,用二进制压缩存储。
AOF持久化以日志的形式记录服务器所处理的每一个写、删除操作,查询操作不会记录,以文本的方式记录,可以打开文件看到详细的操作记录。
二进制的日志,实时记录 redis客户端操作的所有写命令;没有来得及save的数据不保存在dump里,但是命令内容,保存在了aof文件;恢复时,只需要将每save的所有内容的命令调出来。

RDB的优缺点:
优点:RDB是一个非常紧凑(compact)的文件,它保存了Redis在某个时间点上的数据集。这种文件非常适合用于进行备份:比如说,你可以在最近的24小时内,每小时备份一次RDB文件,并且在每个月的每一天也备份一个RDB文件。这样的话即使遇到了问题,也可以随时将数据集还原到不同的版本。RDB非常适用于灾难恢复(disaster recovery):它只有一个文件,并且内容都非常紧凑,可以(在加密后)将它传送到别的数据中心,RDB可以最大化Redis的性能:父进程在保存RDB文件时唯一要做的就是FORK出一个子进程,然后这个子进程会处理接下来的所有保存工作,父进程无须执行任何磁盘I/O操作,RDB在恢复大数据集时的速度比AOF的恢复速度要快
缺点:如果你需要在服务器故障时尽量避免丢失数据,那么RDB不适合你,虽然Redis允许你设置不同的保存点(save point)来控制保存RDB文件的频率,但是,因为RDB文件需要保存整个数据集的状态,所以它并不是一个轻松的操作。因此你可能会至少5到十分钟才保存一次RDB文件。在这种情况下,一旦发生故障停机,就可能会丢失好几分钟的数据。每次保存RDB时,Redis都要fork()出一个子进程,并由子进程来进行实际的持久化工作。在数据集比较庞大时,fork()可能会非常的耗时,造成服务器在某某毫秒内停止处理客户端;如果数据集非常巨大,并且cpu时间非常紧张的话,那么这种停止时间甚至可能会长达一秒。
AOF的优缺点:
优点:1、使用AOF持久化会让Redis变得非常耐久:你可以设置不同的fsync策略,AOF的默认策略为每秒钟fsync一次,在这种配置下,Reids依然可以保持良好的性能,在这种配置下,Redis仍然可以保持良好的性能,并且就算发生故障停机,也最多只会丢失一秒钟的数据。AOF文件是一个只进行追加操作的日志文件,因此对AOF文件的写入不需要进行seek,即使日志文件因为因为某些原因而包含了未写的命令,reids-check-aof工具也会轻易地修复这种问题。
2、Redis可以在AOF文件体积变得过大时,自动地在后台对AOF进行重写:重写后的新AOF文件包含了恢复当前数据集所需要的最小命令集合。整个重写操作是绝对安全的,因为Reids在创建AOF文件的过程中,会继续将将命令追加到现有的AOF文件中,即使重写的过程发生停机,现有的AOF文件也不会丢失。而一旦新的AOF文件创建完毕,Reids就会从旧的AOF文件切换到新的AOF文件,并开始对新的AOF文件进行追加操作。
缺点:对于相同的数据集来说,AOF的文件体积通常要大于RDB文件的体积。