DensePose: Dense Human Pose Estimation In The Wild
论文:https://arxiv.org/abs/1802.00434
caffe2实现:https://github.com/facebookresearch/Densepose
本片文章主要参考了[1]、[2]、[3],详细请参看原文
Facebook 和 Inria France 的研究人员分别在 CVPR 2018 和 ECCV 2018 相继发表了两篇有关「人体姿态估计」(human pose estimation) 的文章 [1] [2],用于介绍他们提出的 Dense Pose 系统以及一个应用场景「密集姿态转移」(dense pose transfer)。
姿态估计的目标是在RGB图像或视频中描绘出人体的形状,这是一种多方面任务,其中包含了目标检测、姿态估计、分割等等。有些需要在非水平表面进行定位的应用可能也会用到姿态估计,例如图形、增强现实或者人机交互。姿态估计同样包含许多基于3D物体的辨认。
密集姿态估计 (Dense Pose Estimation) 将单张 2D 图片中所有描述人体的像素(human pixels),映射到一个 3D 的人体表面模型。如图 1 所示,Facebook 发布了一个名为 DensePose COCO 的大型数据集,包含了预先手工标注的 5 万张各种人类动作的图片。

图 1:密集姿态估计的目标是将 2D 图片中描述人体的像素,映射到一个 3D 表面模型。左:输入的原始图像,以及利用 [1] 中提出的 Dense Pose-RCNN,获得人体各区域的 UV 坐标。UV 坐标又称纹理坐标 (texture coordinates), 用于控制 3D 表面的纹理映射; 中:DensePose COCO 数据集中的原始标注;右:人体表面的分割以及 UV 参数化示意图。
DensePose-RCNN架构
DensePose-RCNN,深度神经网络的结构,是团队新建的。其架构如图:
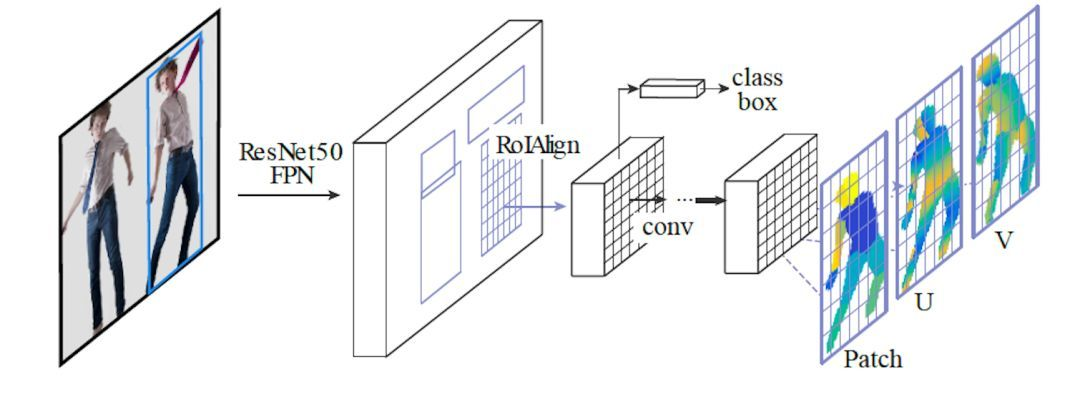
他们是在Facebook自家的物体检测平台Detectron上面,搭起了这样一个模型。
在全卷积处理之后,用了兴趣区域池化层 (ROI Pooling) 。研究人员用三个输出通道,扩增了这个网络。
训练好之后,AI可以把每一个像素,分配到不同的身体部位,给出U坐标和V坐标。
上图中的 ResNet50 FPN (feature pyramid networks) 将输出 feature map,然后通过 ROIAlign 模块对每一个 ROI 生成固定尺寸的 feature map
跨级连(cross-cascading) 架构
下图展示了 ROIAlign 模块的「跨级连」(cross-cascading) 结构,这种结构利用两个辅助任务 (keypoint estimation & mask) 提供的信息,帮助提高 Dense Pose 系统的姿态估计效果。作为 Dense Pose-RCNN 基础之一的 Mask-RCNN结构,正是借助两个相关任务(即 keypoint estimation 和 instance segmentation)提供的信息,用于提高分割效果。
Dense Pose-RCNN中的 ROIAlign 模块采用了「跨级连」(cross-cascading) 架构。如下图:
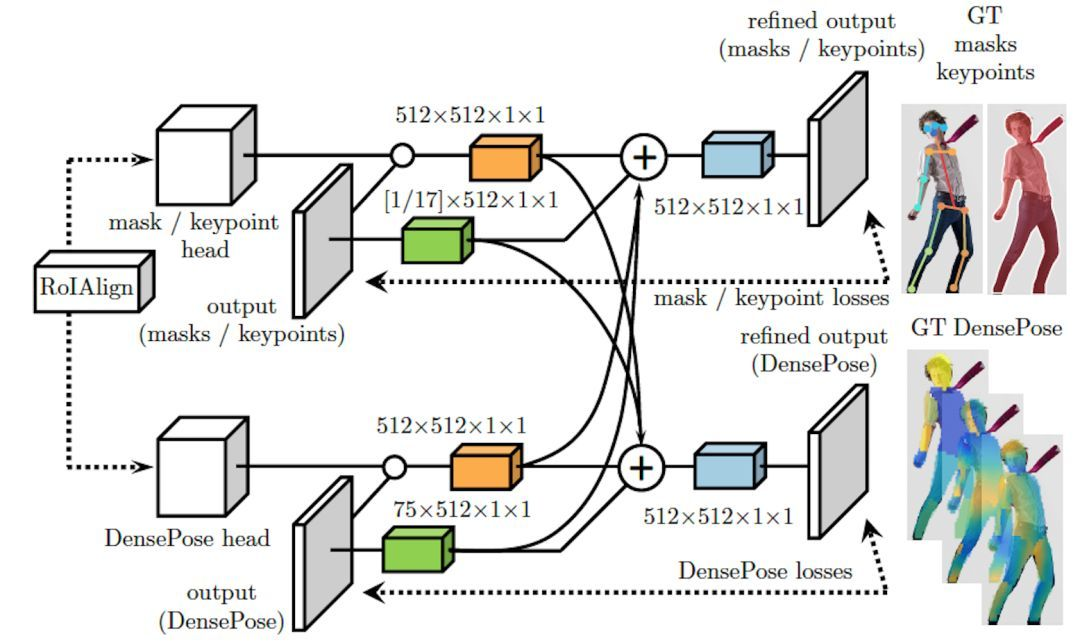
如上图,同时他们利用了多任务的Multi-task cascaded architectures结构,将 mask 和 keypoint的输出特征 与 densepose 的特征互相融合训练。而且也可以看出来使用了多stage的思想,进行“中继监督”训练,利用了任务协同作用和不同监督来源的互补优势。通过级联进一步提升了准确度。
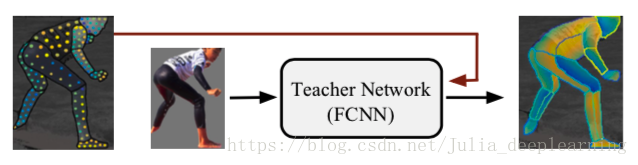
这里“teacher net” (如上图所示)对整体进行辅助训练,它是一个完全卷积神经网络(FCNN),在给定图像尺度把图像和分割蒙版统一化。他们首先使用稀疏的、人工收集的监督信号训练一个“teacher net” ,然后使用该网络来修补用于训练我们的基于区域的系统的密集监督信号。
UV纹理贴图坐标
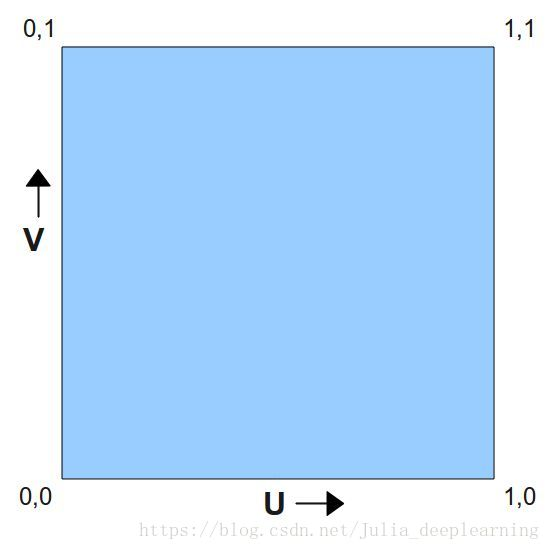
对于三维模型,有两个最重要的坐标系统,一是顶点的位置(X,Y,Z)坐标,另一个就是UV坐标。U和V分别是图片在显示器水平、垂直方向上的坐标,取值一般都是0~1,也 就是(水平方向的第U个像素/图片宽度,垂直方向的第V个像素/图片高度。纹理映射是把图片(或者说是纹理)映射到3D模型的一个或者多个面上。纹理可以是任何图片,使用纹理映射可以增加3D物体的真实感。每个片元(像素)都有一个对应的纹理坐标。由于三维物体表面有大有小是变化的,这意味着我们要不断更新纹理坐标。但是这在现实中很难做到。于是设定了纹理坐标空间,每维的纹理坐标范围都在[0,1]中,利用纹理坐标乘以纹理的高度或宽度就可以得到顶点在纹理上对应的纹理单元位置。纹理空间又叫UV空间。对于顶点来说,纹理坐标相对位置不变。
评测标准
该评测使用GPS(geodesic point similarity)作为度量,使用AP(Average Precision)和AR(Average Recall)作为标准。
$GPS_{j}=frac{1}{|P_{j}|} sum_{p in P_{j}}exp(frac{-g(i_{p}, hat{i}_{p})^{2}}{2k^{2}})$
$GPS$:(1)计算预测的关键点与标签数据的关键点中距离最近的一对点。
(2)计算这对点的距离。
论文效果

从 Dense Pose 到 Dense Pose Transfer
除了介绍 Dense Pose 系统的架构和工作流程,研究人员还在中展示了一个 Dense Pose 的应用,「纹理转移」(texture transfer)。如下图所示,纹理转移这一任务的目标是,将图像中所有人的身体表面纹理,转换为预先提供的目标纹理。

注:Dense Pose 纹理转换 (texture transfer) 的实验结果。该任务的目标是,将输入的视频图像中所有人的身体表面纹理,转换成目标纹理。图中第 1 行为目标纹理 1 和纹理 2。第 2、3 行从左至右依次为,输入图像,转换为纹理 1 的图像,以及转换为纹理 2 的图像。
在 ECCV 2018 上,该论文的三名作者发表了 Dense Pose 的一个后续应用,即「密集姿态转移」(dense pose transfer,以下简称为 DPT)。与纹理转换不同的是,DPT 这一任务的目标是,根据输入的 2D 人体图像和目标姿态 (target dense pose),将输入图像中的人体姿态转换成目标姿态,并且不改变人体表面纹理。
如下图所示,DPT 系统以 Dense Pose为基础,并且由两个互补的模块组成,分别是:
(1)推测模块 (predictive module),用于根据输入图像,预测出具有目标姿态的人体图像;
(2)变形模块 (warping module),负责从输入图像中提取纹理,并「补全」(inpainting) 具有目标姿态的人体表面纹理。此外,系统中还有一个合成模块 (blending module),通过端对端、可训练的单一框架,将推测和变形模块的输出进行合成,并产生最终的图像。
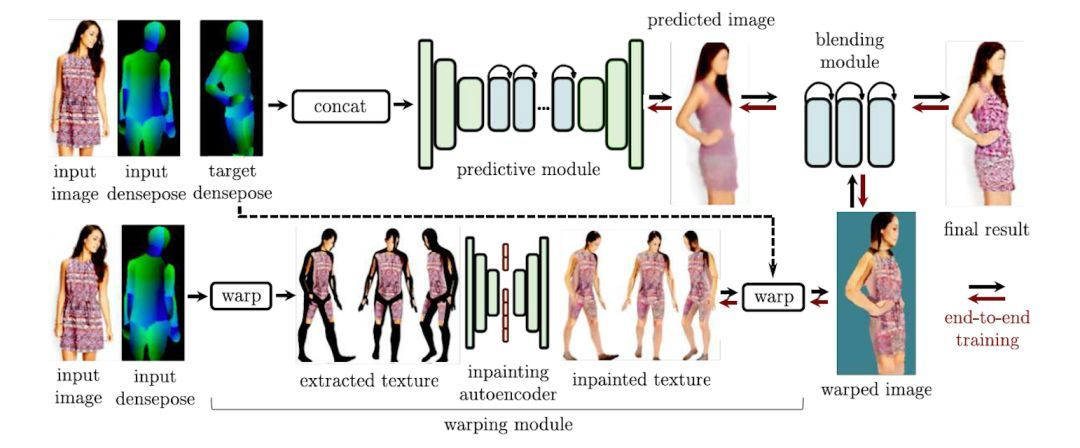
注:密集姿态转移(DPT) 系统的流程图。该系统包括推测模块、变形模块,以及合成模块。
下图展示了在 DeepFashion 数据集上取得的 12 组姿态估计结果。每组姿态结果从左至右依次为:输入图像、正确的目标图像、Deformable GANs (DSC)获得的转移结果,以及 DPT 系统获得的转移结果。由于 DSC 是目前解决「多视角图像合成」(multi-view synthesis) 这一问题中效果最佳的方法,所以DPT的作者将这一方法与 DPT 系统进行比较。
下图能够可以粗略观察到 DPT 系统在纹理转移上还不是特别完善。例如,一些女士上衣的花纹没有被保留,并成功转移到输出图像中;此外,人物的面部特征也在转移中出现一些偏差:身着黄色上衣的男士图像(见下图右侧第 3 行),经过姿态转后,人物面部更为「女性化」。GPT论文的作者指出,要取得更好的姿态转换结果,可能还需要预先获得一些额外的信息,比如面部特征、性别以及肤色。

注:密集姿态转换(dense pose transfer)的实验结果。左右两组结果分别包含了输入图像、正确的目标图像、Deformable GANs (DSC) [7] 得到的转移结果,以及 DPT 系统 [2] 得到的转移结果。
好玩的应用
可以参考用DensePose,教照片里的人学跳舞,系群体鬼畜 | ECCV 2018
Reference
[1] https://zhuanlan.zhihu.com/p/38241179
[2] https://www.sohu.com/a/293908747_129720
[3] https://blog.csdn.net/Julia_deeplearning/article/details/83011798
[4] https://blog.csdn.net/yH0VLDe8VG8ep9VGe/article/details/82598740
[5] Alp Güler, Rıza, Natalia Neverova, and Iasonas Kokkinos. "Densepose: Dense human pose estimation in the wild." Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition. 2018.
[6] Neverova, Natalia, Riza Alp Guler, and Iasonas Kokkinos. "Dense pose transfer." Proceedings of the European Conference on Computer Vision (ECCV). 2018.
[7] Alp Guler, Riza, et al. "Densereg: Fully convolutional dense shape regression in-the-wild." Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition. 2017.
[8] Chen, Liang-Chieh, et al. "Deeplab: Semantic image segmentation with deep convolutional nets, atrous convolution, and fully connected crfs." IEEE transactions on pattern analysis and machine intelligence 40.4 (2017): 834-848.
[9] He, Kaiming, et al. "Mask r-cnn." Computer Vision (ICCV), 2017 IEEE International Conference on. IEEE, 2017.
[10] Liu, Ziwei, et al. "Deepfashion: Powering robust clothes recognition and retrieval with rich annotations." Proceedings of the IEEE conference on computer vision and pattern recognition. 2016.
[11] Siarohin, Aliaksandr, et al. "Deformable gans for pose-based human image generation." CVPR 2018-Computer Vision and Pattern Recognition. 2018.