人脸检测及识别python实现系列(2)——识别出人脸
从实时视频流中识别出人脸区域,从原理上看,其依然属于机器学习的领域之一,本质上与谷歌利用深度学习识别出猫没有什么区别。程序通过大量的人脸图片数据进行训练,利用数学算法建立建立可靠的人脸特征模型,如此即可识别出人脸。幸运的是,这些工作OpenCV已经帮我们做了,我们只需调用对应的API函数即可,先给出代码:
#-*- coding: utf-8 -*- import cv2 import sys from PIL import Image def CatchUsbVideo(window_name, camera_idx): cv2.namedWindow(window_name) #视频来源,可以来自一段已存好的视频,也可以直接来自USB摄像头 cap = cv2.VideoCapture(camera_idx) #告诉OpenCV使用人脸识别分类器 classfier = cv2.CascadeClassifier("/usr/local/share/OpenCV/haarcascades/haarcascade_frontalface_alt2.xml") #识别出人脸后要画的边框的颜色,RGB格式 color = (0, 255, 0) while cap.isOpened(): ok, frame = cap.read() #读取一帧数据 if not ok: break
#将当前帧转换成灰度图像
grey = cv2.cvtColor(frame, cv2.COLOR_BGR2GRAY) #人脸检测,1.2和2分别为图片缩放比例和需要检测的有效点数 faceRects = classfier.detectMultiScale(grey, scaleFactor = 1.2, minNeighbors = 3, minSize = (32, 32)) if len(faceRects) > 0: #大于0则检测到人脸 for faceRect in faceRects: #单独框出每一张人脸 x, y, w, h = faceRect cv2.rectangle(frame, (x - 10, y - 10), (x + w + 10, y + h + 10), color, 2) #显示图像 cv2.imshow(window_name, frame) c = cv2.waitKey(10) if c & 0xFF == ord('q'): break #释放摄像头并销毁所有窗口 cap.release() cv2.destroyAllWindows() if __name__ == '__main__': if len(sys.argv) != 2: print("Usage:%s camera_id " % (sys.argv[0])) else: CatchUsbVideo("识别人脸区域", int(sys.argv[1]))
先看一下程序输出结果:
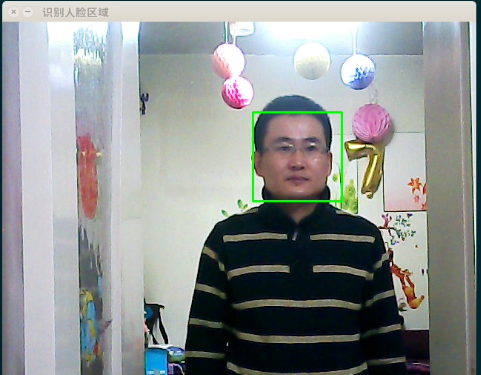
程序正确的识别出了我的脸,加上空白行不到50行代码,还是很简单的。当然,绝大部分的工作OpenCV已经默默地替我们做了,所以我们用起来才这么简单。关于代码有几个地方需要重点交代,首先就是人脸分类器这行:
#告诉OpenCV使用人脸识别分类器 classfier = cv2.CascadeClassifier("/usr/local/share/OpenCV/haarcascades/haarcascade_frontalface_alt2.xml")
这行代码指定OpenCV选择使用哪种分类器(注意,一定习惯分类这个说法,ML的监督学习研究的就是各种分类问题),OpenCV提供了多种分类器:

上图为我的电脑上安装的OpenCV3.2提供的所有分类器,有识别眼睛的(甚至包括左右眼),有识别身体的,有识别笑脸的,甚至还有识别猫脸的,有兴趣的可以逐个试试。关于人脸识别,OpenCV提供多个分类器选择使用,其中haarcascade_frontalface_alt_tree.xml是最严格的分类器,光线、带个帽子都有可能识别不出人脸。其它的稍微好点,default那个识别最宽松,某些情况下我家里的灯笼都会被识别成人脸;)。另外安装环境不同,分类器的安装路径也有可能不同,请在安装完OpenCV后根据分类器的实际安装路径修改代码。另外再多说一句,如果我们想构建自己的分类器,比如检测火焰(火灾报警)、汽车(确定路口汽车数量),我们依然可以使用OpenCV训练构建,详细说明参见OpenCV的官方文档。
接下来解释如下几行代码:
#人脸检测,1.2和2分别为图片缩放比例和需要检测的有效点数 faceRects = classfier.detectMultiScale(grey, scaleFactor = 1.2, minNeighbors = 3, minSize = (32, 32)) if len(faceRects) > 0: #大于0则检测到人脸 for faceRect in faceRects: #单独框出每一张人脸 x, y, w, h = faceRect cv2.rectangle(frame, (x - 10, y - 10), (x + w + 10, y + h + 10), color, 2)
其中classfier.detectMultiScale()即是完成实际人脸识别工作的函数,该函数参数说明如下:
grey:要识别的图像数据(即使不转换成灰度也能识别,但是灰度图可以降低计算强度,因为检测的依据是哈尔特征,转换后每个点的RGB数据变成了一维的灰度,这样计算强度就减少很多)
scaleFactor:图像缩放比例,可以理解为同一个物体与相机距离不同,其大小亦不同,必须将其缩放到一定大小才方便识别,该参数指定每次缩放的比例
minNeighbors:对特征检测点周边多少有效点同时检测,这样可避免因选取的特征检测点太小而导致遗漏
minSize:特征检测点的最小值
对同一个画面有可能出现多张人脸,因此,我们需要用一个for循环将所有检测到的人脸都读取出来,然后逐个用矩形框框出来,这就是接下来的for语句的作用。Opencv会给出每张人脸在图像中的起始坐标(左上角,x、y)以及长、宽(h、w),我们据此就可以截取出人脸。其中,cv2.rectangle()完成画框的工作,在这里我有意识的外扩了10个像素以框出比人脸稍大一点的区域。cv2.rectangle()函数的最后两个参数一个用于指定矩形边框的颜色,一个用于指定矩形边框线条的粗细程度。
好了,人脸识别的事说清楚了,下一篇该讲讲如何准备训练数据了,只有训练数据足够多,我们的程序才能识别出这是谁,而不是无论青红皂白框个人脸就完事。