你说你会关系数据库?你说你会Hadoop?
忘掉它们吧,我们既不需要网络支持,也不需要复杂关系模式,只要读写够快就行。
——论数据存储的本质
浅析数据库技术
内存数据库——STL的map容器
关系数据库横行已久,似乎大家已经忘了早些年那些简陋的数据存储模式。
在ACM选手中,流传着“手艹数据库”的说法,即利用map<string,type>或者map<int,type>,
按照自己编码规则,将数据暂存起来,等待调用。
这就是KV数据库,最简陋的数据库,也是最实用的数据库。
STL的map容器,底层实现由红黑树完成,访问复杂度$O(logn)$,修改复杂度$O(logn)$。
在内存中,具有优良的速度,是非常廉价的内存数据库实现方式。
硬盘数据库——更复杂的B+树
B树是经典的多叉搜索树,相比于在内存中使用的二叉搜索红黑树,在硬盘物理结构上访问更具有优势。
现代关系数据库,底层大部分都是由B+树实现,由于原始的B树只支持单键,关系数据库利用复杂的编码,
由单键模拟出了多键,在IO效率上,是严重的倒退。
应用数据库更关注复杂的数据关系,但是对于机器学习系统来说,显然是多余的。
单机数据库——暴力、小而轻便
不是所有的数据库都像Oracle、MySQL、SQL Server、Hadoop一样,需要远程技术支持。
实际上,单机数据库历来在程序开发中,使用广泛。
Android开发中,通常会使用SQLite,在后来序列化APP中复杂的数据结构。
对于简单的桌面程序而言,早期更是有手写序列化数据存储格式的习惯,这种习惯至今还在游戏开发界保留着。
一个庞大的单机游戏,比如我手里占用空间达35G的巫师3,主程序仅仅40M。
庞大的游戏资源,其本质就是设计者人工设计的单机数据库,没什么稀奇的。
再看Google Protocol Buffer
数据库需要做的最后一步是存储,存储之前必须解决一个问题:如何存储?
对于一个机器学习系统而言,其内部充斥着大量复杂的数据结构,如何存储更是一个难题。
这里大致有两个方案:
①仿照关系数据库,将数据结构与数据关系直接存储。
②将复杂数据结构,编码成简单数据结构,间接存储。
可以说,这两种方案各有优劣。
对于①来说,优势是无须后处理,读取后完整复现数据结构,劣势是IO缓慢。
对于②来说,优势是IO飞快,劣势是IO之前,分别需要解码和编码。
从计算机性能角度分析,我们不难发现,这两种方案是IO与CPU的权衡。
①所需CPU压力很小,但是在计算系统设计中,IO容易成瓶颈。
②所需CPU压力很大,可以说是牺牲CPU来救IO。
So,在机器学习系统设计中,究竟是①合适,还是②合适?很难说。
经典机器学习系统可能更倾向①,但深度学习系统显然毫无争议地选择②。
因为复杂计算都被移到了GPU上,CPU沦为了保姆,保姆就要做好本职工作,专心辅助。
——————————————————————————————————————————————
Protocol Buffer的使用,实际上也是不推荐我们使用①的。
Protocol Buffer所有message结构,都提供了一个核心函数SerializeToString,能够将任意复杂的数据结构,编码成单字符串。
这就为最暴力的单键单值KV数据库提供了可能,在单键单值情况下,IO的速度可以说达到了极致。
KV数据库
LevelDB
Caffe早期使用的KV数据库,Jeff Dean出品。从百度的科普文章来看,应当是借用了Jeff大神的Bigtable技术。
LevelDB的设计目标是硬盘数据库,而不是内存数据库,因而在硬盘IO方面做了不少优化,不得不佩服Jeff大神。
MapReduce(Hadoop)的部分技术似乎也被植入其中,Google宣称支持十亿级别规模的大数据。
LMDB(Lighting Memory DB)
大多数人估计不知道LMDB的全称,M指的是Memory,显然这玩意是瞄准了内存数据库方向设计的。
与传统内存数据库不同,它并不是真正在用物理内存,而用的是虚拟内存。
虚拟内存,又名操作系统分页文件,在Linux下,又叫做交换分区(Swap分区)。
虚拟内存的文件结构是被操作系统优化过的,速度介于普通硬盘介质缓冲文件(LevelDB)和物理内存之间。
得益于此,LMDB的整体IO能力较LevelDB有所提升,似乎国外友人认为LMDB是LevelDB的Killer。
如何选择?
默认情况下,你应该选择LMDB而不是LevelDB,这是新版Caffe主导的一个概念。
LMDB对虚拟内存(交换分区)大小有一定要求,如果你不喜欢设置虚拟内存分页文件,LevelDB或许是你的选择。
注意,虚拟内存是用你的硬盘(SSD更佳)转化的空间,和物理内存没有任何关系。
设置虚拟内存,需要长期占用你的宝贵存储空间,使用前需要三思。
默认情况下,应该保证虚拟内存在4G以上,对于ImageNet等更大数据集,则看情况继续加大。
教程
本教程本着与时俱进和烧硬件的原则,不对LevelDB接口实现,请自行参考Caffe源码。
LMDB
体系结构
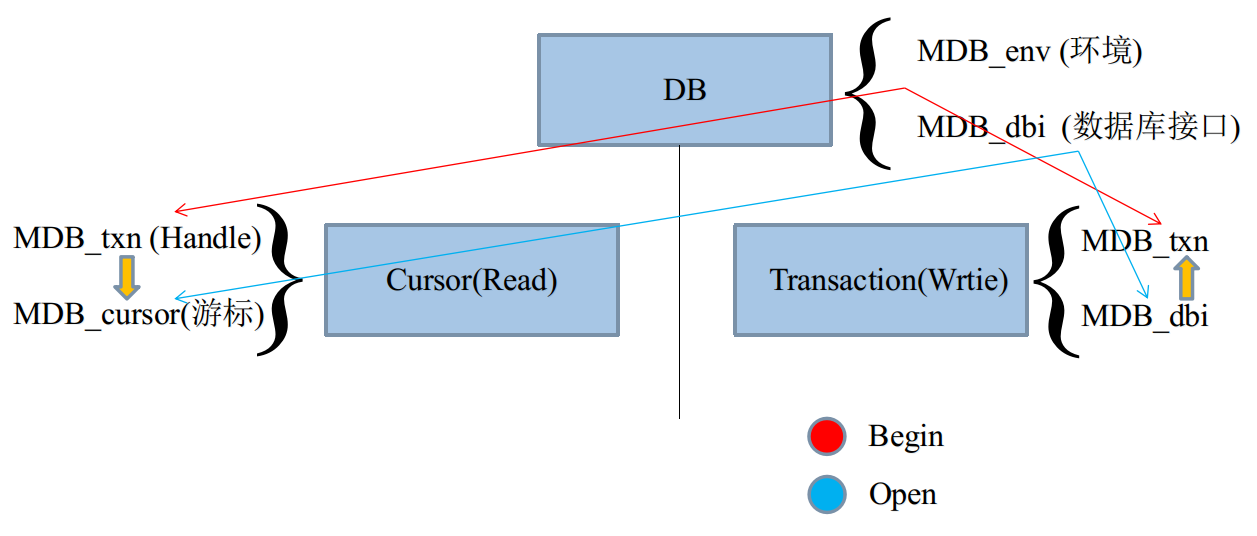
LMDB的主体分为三个部分,数据库、游标、事务。
数据库为基层,首先必须打开,根据打开方式的不同,分为以下两种操作:
①读操作:依赖游标的偏移,获取数据。
②写操作:依赖数据接口,填充数据。
LMDB内部提供了四种结构负责:MDB_env、MDB_dbi、MDB_txn,MDB_cursor
Caffe所有代码,都是参考自LMDB开发文档,这四个东西讲起来是没有意义的。
代码实战
通用接口
Caffe默认需要兼容两种数据库,另外LMDB的API实在是比较难用,所以设计一个通用接口是个不错的主意。
建立db.hpp
class DB{ public: enum Mode { NEW, READ, WRITE }; DB() {} virtual ~DB() {} virtual void Open(const string& source, Mode mode) = 0; virtual void Close() = 0; virtual Cursor* NewCursor() = 0; virtual Transaction* NewTransaction() = 0; };
在上图中,我们发现,无论是Cursor,还是Transaction,工作都需要txn句柄。
而txn句柄,需要由DB的env创建,可以视为是与DB建立灵魂链接。
所以在逻辑结构上,DB应当包含Cursor与Transaction。
另外,需要注意,对于一个DB而言,可以有多个Cursor和Transaction。
无论是LevelDB,还是LMDB,多个Cursor将变成并行读,多个Transaction将变成并行写。
这也是数据库系统(DBMS)应当提供的核心功能,要不然人人都能写数据库系统了。
class Cursor{ public: Cursor() {} virtual ~Cursor() {} virtual void SeekToFirst() = 0; virtual void Next() = 0; virtual string key() = 0; virtual string value() = 0; virtual bool valid() = 0; };
Cursor在嵌入式关系数据库编程中,是经常见到的,如其名“游标”,负责在数据库中乱跑。
尽管我们使用的是KV数据库,但实际上对于深度学习迭代数据过程而言,Key几乎是没用的。
大部分情况下,数据都是序列Read。一遍读完之后,游标移动到文件头,重新再读。
所以,默认的Cursor并没有提供按Key读取的接口,读者可以自行翻阅LMDB开发文档实现。
序列读取,核心函数只需要Next和SeekToFirst,以及基于当前游标下,对Key和Value的访问接口。
还有一个判断文件尾EOF的函数vaild,每次遇到EOF之后,应该调用SeekToFirst,让大侠重新来过。
class Transaction{ public: Transaction() {} virtual ~Transaction() {} virtual void Put(const string& key, const string& val) = 0; virtual void Commit() = 0; };
Transaction相当简陋,实际上,它只会用数据转换阶段,比如官方源码著名的convert_cifar10_data.cpp。
Put接口用于数据灌入,以LMDB为例,Put后首先会被转移到虚拟内存,当最后执行Commit,才封装成文件。
LMDB接口
该部分大部分源于LMDB开发文档,不做过多解释。
建立db_lmdb.hpp
class LMDB :public DB{ public: LMDB() :mdb_env(NULL) {} virtual ~LMDB() { Close(); } virtual void Open(const string& source, Mode mode); virtual void Close(){ if (mdb_env != NULL){ mdb_dbi_close(mdb_env, mdb_dbi); mdb_env_close(mdb_env); mdb_env = NULL; } } virtual LMDBCursor* NewCursor(); virtual LMDBTransaction* NewTransaction(); private: MDB_env* mdb_env; MDB_dbi mdb_dbi; };
从DB接口派生过来,注意Close之后,需要先释放dbi,再释放env。
同时注意,dbi不是指针,是实体。
class LMDBCursor :public Cursor{ public: LMDBCursor(MDB_txn *txn, MDB_cursor *cursor) : mdb_txn(txn), mdb_cursor(cursor), valid_(false) {SeekToFirst(); } virtual ~LMDBCursor(){ mdb_cursor_close(mdb_cursor); mdb_txn_abort(mdb_txn); } virtual void SeekToFirst(){ Seek(MDB_FIRST); } virtual void Next() { Seek(MDB_NEXT); } virtual string key(){ return string((const char*)mdb_key.mv_data, mdb_key.mv_size); } virtual string value(){ return string((const char*)mdb_val.mv_data, mdb_val.mv_size); } virtual bool valid() { return valid_; } private: void Seek(MDB_cursor_op op){ int mdb_status = mdb_cursor_get(mdb_cursor, &mdb_key, &mdb_val, op); if (mdb_status == MDB_NOTFOUND) valid_ = false; else{ MDB_CHECK(mdb_status); valid_ = true; } } MDB_txn* mdb_txn; MDB_cursor* mdb_cursor; MDB_val mdb_key, mdb_val; bool valid_; };
LMDBCurosr在构造时,需要传入MDB_txn和MDB_cursor,句柄和游标的初始化都要依赖DB本身。
Key和Value中,mdb_val默认返回的是void*,需要强转换为char*,再用string封装。
Seek函数中,检测是否到达文件尾EOF,修改vaild状态。SeekToFirst将在外部被调用,重置游标位置。
析构函数我是看不懂的,官方文档即视感。
class LMDBTransaction : public Transaction{ public: LMDBTransaction(MDB_dbi *dbi,MDB_txn *txn):mdb_dbi(dbi), mdb_txn(txn) {} virtual void Put(const string& key, const string&val); virtual void Commit() { MDB_CHECK(mdb_txn_commit(mdb_txn)); } MDB_dbi* mdb_dbi; MDB_txn* mdb_txn; };
LMDBTransaction同样需要传入MDB_txn和MDB_dbi。
实现
建立db_lmdb.cpp
const size_t LMDB_MAP_SIZE = 1099511627776; //1 TB void LMDB::Open(const string& source, Mode mode){ MDB_CHECK(mdb_env_create(&mdb_env)); MDB_CHECK(mdb_env_set_mapsize(mdb_env, LMDB_MAP_SIZE)); if (mode == NEW) CHECK_EQ(_mkdir(source.c_str()), 0); int flags = 0; if (mode == READ) flags = MDB_RDONLY | MDB_NOTLS; int rc = mdb_env_open(mdb_env, source.c_str(), flags, 0664); #ifndef ALLOW_LMDB_NOLOCK MDB_CHECK(rc); #endif if (rc == EACCES){ LOG(INFO) << "Permission denied. Trying with MDB_NOLOCK "; mdb_env_close(mdb_env); MDB_CHECK(mdb_env_create(&mdb_env)); flags |= MDB_NOLOCK; MDB_CHECK(mdb_env_open(mdb_env, source.c_str(), flags, 0664)); } else MDB_CHECK(rc); LOG(INFO) << "Open lmdb file:" << source; }
LMDB的Open接口,我觉得是整个Caffe里面写的最烂的函数,烂在两点:
①让人看不懂的LMDB的Lock锁
②用了OS相关的API,而且很烂。
先说说Lock锁,默认是以Lock访问的,这意味着,一个DB只能被同时打开一次。
如果要并行打开,并且包含写入操作,那么这样非常危险,但并不是不可以(NO_LOCK访问)。
所以,后半部分代码整体就在尝试切换NO_LOCK访问。如果你嫌麻烦,可以删掉,默认就用NO_LOCK。
再说这个很烂API函数的mkdir,首先它在Linux和Windows下,写法略有不同,头文件也不一样。
其次,mkdir返回值只有俩种:创建失败和创建成功。实际上我们更需要第三种:目录是已存在。
很多fresher在玩Caffe的时候,转化数据都会失败,被GLOG宏给Check到:
if (mode == NEW) CHECK_EQ(_mkdir(source.c_str()), 0);
当指定目录存在时,就会被CHECK到。取消这个CHECK宏又不妥,不能排除错误路径的情况。
Linux提供opendir检测目录是否存在,建议改写这步;Windows则没有,不太好办。
为此,使用第三方库是个好主意,Boost的filesystem封装了跨平台的文件系统解决方案。
先做include:
#include <boost/filesystem/path.hpp>
#include <boost/filesystem/operations.hpp>
然后做替换:
void LMDB::Open(const string& source, Mode mode){ ...... // if (mode == NEW) CHECK_EQ(_mkdir(source.c_str()), 0); boost::filesystem::path db_path(source); if (!boost::filesystem::exists(db_path)){ if (mode == READ) LOG(FATAL) << "Specified DB path is illegal [Read Operation]."; if (mode == NEW){ if (!boost::filesystem::create_directory(db_path)) LOG(FATAL) << "Specified DB path is illegal [NEW Operation]."; } }else{ // delete old dir and create new dir if (mode == NEW){ boost::filesystem::remove_all(db_path); boost::filesystem::create_directory(db_path); } } ...... }
这样,数据库部分就能摆脱OS的依赖了,感谢Boost库。
————————————————————————————————————————————————————
env的环境创建,需要指定最大虚拟内存缓冲区容量,默认是1TB,这造成了LMDB在Windows的唯一Bug。
NTFS分区不允许1TB这种容量存在,所以LMDB默认源码在Windows下会提示空间不足。
但是修正之后,创建数据时,你还是能看到,临时文件占用了1TB,尽管你的分区没有1TB,不知道是什么原理。
————————————————————————————————————————————————————
LMDBCursor* LMDB::NewCursor(){ MDB_txn* txn; MDB_cursor* cursor; MDB_CHECK(mdb_txn_begin(mdb_env, NULL, MDB_RDONLY, &txn)); MDB_CHECK(mdb_dbi_open(txn, NULL, 0, &mdb_dbi)); MDB_CHECK(mdb_cursor_open(txn, mdb_dbi, &cursor)); return new LMDBCursor(txn, cursor); } LMDBTransaction* LMDB::NewTransaction(){ MDB_txn *txn; MDB_CHECK(mdb_txn_begin(mdb_env, NULL, 0, &txn)); MDB_CHECK(mdb_dbi_open(txn, NULL, 0, &mdb_dbi)); return new LMDBTransaction(&mdb_dbi, txn); } void LMDBTransaction::Put(const string& key, const string& val){ MDB_val mkey, mval; mkey.mv_data = (void*)key.data(); mkey.mv_size = key.size(); mval.mv_data = (void*)val.data(); mval.mv_size = val.size(); MDB_CHECK(mdb_put(mdb_txn, *mdb_dbi, &mkey, &mval, 0)); }
这些实现几乎就是套文档,没什么需要注意的。
最后建立db.cpp,利用C++的多态性,提供DB的获取接口:
DB* GetDB(const string& backend){ if (backend == "leveldb"){ NOT_IMPLEMENTED; } if (backend == "lmdb"){ return new LMDB(); } return new LMDB(); }
直接用基类指针DB,指向LMDB,多态性的经典应用之一。
完整代码
db.hpp
https://github.com/neopenx/Dragon/blob/master/Dragon/data_include/db.hpp
db_lmdb.hpp
https://github.com/neopenx/Dragon/blob/master/Dragon/data_include/db_lmdb.hpp
db.cpp
https://github.com/neopenx/Dragon/blob/master/Dragon/data_src/db.cpp
db_lmdb.cpp
https://github.com/neopenx/Dragon/blob/master/Dragon/data_src/db_lmdb.cpp