项目流程:
1. 产品需求
(1)基于用户认证组件和Ajax实现登陆验证(图片验证码)
(2)基于forms组件和Ajax实现注册功能
(3)设计系统首页(文章列表渲染)
(4)设计个人站点页面
(5)文章详情页
(6)实现文章点赞功能
(7)实现文章的评论
--- 文章的评论
--- 评论的评论
(8)富文本编辑框的防止xss攻击
2. 设计表结构
3. 按照每个功能进行开发
4. 功能测试
5. 项目部署上线
所需知识点:
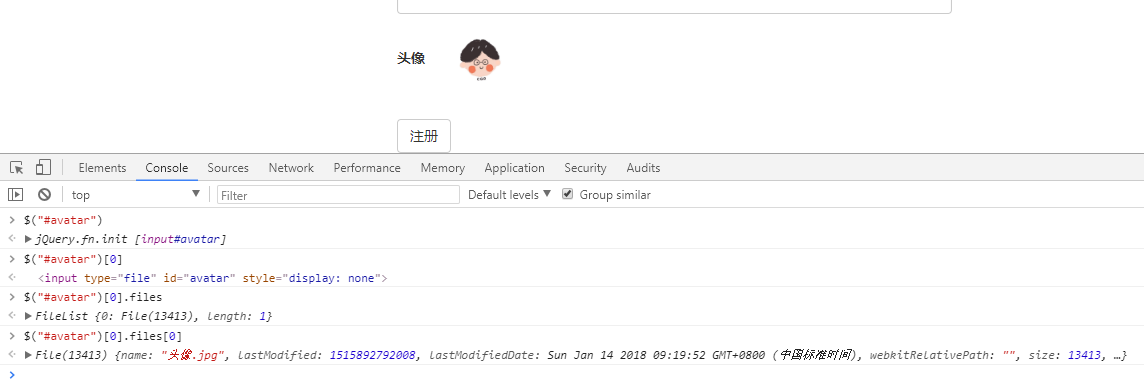
1. JQuery 获取input标签中的文件对象:$("#avatar")[0].files[0]
2.
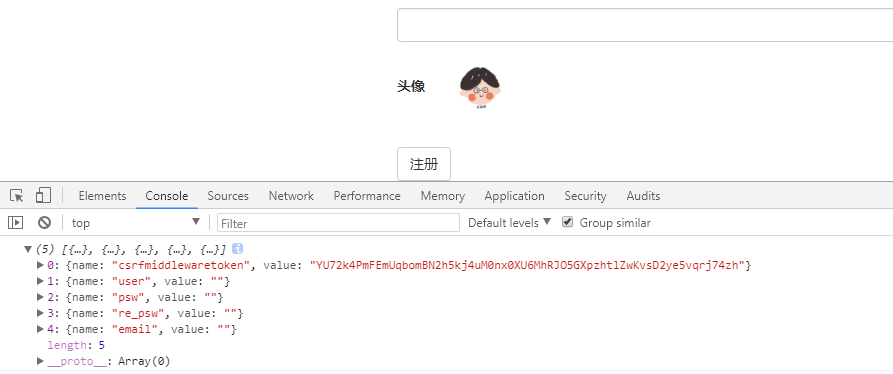
$("#form").serializeArray(); // 返回一个数组,数组中是一个个对象,对象的格式为: {name:"form表单控件的name属性值",value:"form表单控件的value值"}
浏览器效果图:
3. Django的Media配置:
FileField字段和ImageField字段:FileField可用于上传任何文件,ImageField只能上传图片 # 表: class UserInfo(AbstractUser): nid = models.AutoField(primary_key=True) telephone = models.CharField(max_length=11, null=True, unique=True) avatar = models.FileField(upload_to="avatars/", default="/avatars/default.png") # avatar 这个字段不传的时候(avatar字段为空时,也是上传了 avatar字段),才会使用 default 的默认值 # FileField字段一定要接受一个文件对象;ImageFile字段一定要接受一个图片对象 # 给上面的表生成记录: avatar_obj = request.FILES.get("avatar") user_obj = UserInfo.objects.create_user(username=user,password=psw,email=email,avatar=avatar_obj) # 生成记录时,Django会自动下载 avatar_obj 这个文件对象,由于 upload_to = "avatars/",Django会把avatar_obj下载到根目录的 "avatars"文件夹下(没有"avatars"文件夹 django会自动创建一个),user_obj的avatar字段(UserInfo表中)存的是 文件的相对路径 Media配置之 MEDIA_ROOT: Django对静态文件的区分:Django有两种静态文件 1. /static/ :js,css,img;服务器自己用到的文件; 2. /media/ :用户上传的文件 # 用户注册时的代码: avatar_obj = request.FILES.get("avatar") user_obj = UserInfo.objects.create_user(username=user,password=psw,email=email,avatar=avatar_obj) 上面两行代码,一旦在settings.py中配置了 media 文件("media"是project中的一个文件夹名,可放在project下,也可放在 app 下): MEDIA_ROOT = os.path.join(BASE_DIR,"media") Django会自动实现如下功能: 会将文件对象下载到MEDIA_ROOT中的 avatars(因为UserInfo表中是:upload_to="avatars/")文件夹中(如果MEDIA_ROOT中没有 avatars 这个文件夹,Django会自动创建 );user_obj的avatar存的是文件的相对路径 Media配置之 MEDIA_URL: 客户端浏览器如何能直接访问到 media 中的数据? 1. settings.py: MEDIA_URL = "/media/" # MEDIA_URL = "/media/" 也是为上面的 MEDIA_ROOT 那个绝对路径起了一个别名;效果和 STATIC_URL = '/static/' 一样 2. urls.py中的 urlpatterns : from django.views.static import serve re_path(r"media/(?P<path>.*)$",serve,{"document_root":settings.MEDIA_ROOT})
4. Django的 admin 组件:
admin组件:(不是必需的) # Django内部提供的一个组件,作用:后台数据管理组件(通过web页面) # 注:1. 只有超级用户(superuser)才能登陆 admin 路径; 2. python manage.py createsuperuser ---> 针对的是用户认证组件auth对应的那个用户表(auth_user或者Blog项目中的 blog_userinfo 表) # 用admin组件对象后台数据进行操作之前,需要先进行 admin 注册: # admin注册语法: 每一个 app 下面有一个 admin.py 的文件,在这个文件中做 admin 注册,如这个 Blog 项目: # (1) 先把表拿过来: from blog import models # (2) 通过 admin.site.register() 注册 models.py 中的表 admin.site.register(models.UserInfo) admin.site.register(models.Blog) admin.site.register(models.Category) admin.site.register(models.Tag) admin.site.register(models.Article) admin.site.register(models.Article2Tag) admin.site.register(models.ArticleUpDown) admin.site.register(models.Comment) # 在 admin 页面操作 Comment 表,url为:http://127.0.0.1:8000/admin/blog/comment/ # /blog/为app的名字, /comment/为表的名字
5. 日期归档查询
日期归档查询(数据库)1: 1. date_format(时间相关字段,时间格式) # date存“年月日”,time存“时分秒”,datetime存“年月日时分秒” ===============date,time,datetime==============
create table t_mul(d date,t time,dt datetime); insert into t_mul values(now(),now(),now()); select * from t_mul; +------------+----------+---------------------+ | d | t | dt | +------------+----------+---------------------+ | 2017-08-01 | 19:42:22 | 2017-08-01 19:42:22 | +------------+----------+---------------------+ select date_format(dt,"%Y-%m") from t_mul; # 查询结果为: 2017-08 2. extra():用于插入sql语句;该函数的调用者是 QuerySet extra(select=None,where=None,params=None,tables=None,order_by=None,select_params=None) 有点情况下,对于一些复杂的sql语句,Django并没有相应的ORM去对应这些sql语句,这种情况下Django提供了 extra() 函数:QuerySet修改机制---它能在QuerySet生成的SQL从句中注入新子句 extra() 可以指定一个或多个参数,例如 select,where 或者 tables;这些参数都不是必需的,但至少要使用一个 select参数:select参数可以让你在 SELECT 从句中添加其它字段信息;它是一个字典,存放着 属性名到 SQL 从句的映射 如: in MySQL: article_obj = models.Article.objects.extra(select={"is_recent":"create_time > '2017-09-05'"}.values("title","is_recent") # 通过 extra() 就可以写 create_time > '2017-09-05' 这种SQL的写法 # 返回结果还可以继续 annotate()(.values("xxx").annotate())进行分组 # 返回的结果集(也是一个QuerySet)中每个 Entry 对象都有一个额外的属性 is_recent,它是一个布尔值(True为1,False为0),表示 Article对象的 create_time 是否晚于 2017-09-05 日期归档查询(数据库)2: # 利用Django提供的 TruncMonth() 方法: 截取到月 from django.db.models.functions import TruncMonth Sales.objects .annotate(month=TruncMonth('timestamp')) # .annotate()的作用不是分组,而是截取 'timestamp' 到月,并为每个对象添加一个 截取到月 的字段;# Truncate to month and add to select list .values('month') # Group by month .annotate(c=Count('id')) # Select the count of the grouping .values('month','c')
6. inclusion_tag(具体操作见项目)
from django import template from django.db.models import Count from blog.models import * register = template.Library() @register.inclusion_tag("classification.html") # inclusion_tag()中的参数表示所要引入的一套模板文件 def get_classification_data(username): # get_classification_data() 这个方法一旦被调用,它会先执行下面的数据查询,查询完之后会把下面的字典返回 "classification.html" 这个模板文件(没有返回给调用者),因为 "classification.html" 文件会需要下面的这几个变量;下面的变量传给 "classification.html"之后会进行 render 渲染,渲染成一堆完整的 html标签 user = UserInfo.objects.filter(username=username).first() # 查询当前站点对象 blog = user.blog cate_list = Category.objects.filter(blog=blog).values("pk").annotate(c=Count("article__title")).values("title", "c") tag_list = Tag.objects.filter(blog=blog).values("pk").annotate(c=Count("article__title")).values_list("title", "c") date_list = Article.objects.filter(user=user).extra( select={"y_m_date": "date_format(create_time,'%%Y-%%m')"}).values("y_m_date").annotate(c=Count("nid")).values( "y_m_date", "c") # annotate()之前要先 .values() return {"username":username,"blog": blog, "cate_list": cate_list, "tag_list": tag_list, "date_list": date_list}
7. KindEditor上传文件:
uploadJson 指定上传文件的服务器端程序。 数据类型: String 默认值: basePath + ‘php/upload_json.php’ uploadJson对应的value是一个路径 如: { uploadJson:"/upload/", // uploadJson对应的是一个路径 extraFileUploadParams:{ csrfmiddlewaretoken:$("[name=csrfmiddlewaretoken]").val(), // post请求,需要自己组装数据,所以要加上这个 key-value filePostName:"upload_img" // 所上传文件对应的 key } extraFileUploadParams 上传图片、Flash、视音频、文件时,支持添加别的参数一并传到服务器。 数据类型: Array 默认值: {} filePostName 指定上传文件form名称。 数据类型: String 默认值: imgFile
8. BeautifulSoup:
from bs4 import BeautifulSoup # BeautifulSoup的用法1:获取标签字符串文内容 s = "<h1>hello</h1><span>123</span>" soup = BeautifulSoup(s,"html.parser") # 第一个参数放标签字符串,第二参数放 解析器 print(soup.text) # soup.text 表示 获取s 这个标签字符串的文本 # 打印结果: # hello123 # BeautifulSoup的用法2:防止xss攻击:过滤出去 <script> 标签 s = "<h1>hello</h1><span>123</span><script>alert(123)</script>" soup = BeautifulSoup(s,"html.parser") print(soup.find_all()) # soup.find_all():获取标签字符串中所有的标签对象;列表的形式 # 打印结果: [<h1>hello</h1>,<span>123</span>,<script>alert(123)</script>] for tag in soup.find_all(): if tag.name == "script": # tag.name 表示 标签名(字符串格式) tag.decompose() # 从 soup 中把 该标签 删除 print(str(soup)) # 打印结果:<h1>hello</h1><span>123</span>
9. 图片验证码
from random import randint import random def get_random_color(): # 用于随机生成颜色 return (randint(0, 255), randint(0, 255), randint(0, 255)) def get_valid_code_img(request): # 方式四:给生成的图片(画板)中添加文字 from io import BytesIO # BytesIO是内存管理工具 from PIL import Image, ImageDraw, ImageFont img = Image.new("RGB", (260, 33), color=get_random_color()) # new()里面有三个参数:第一个表示模式(RGB表示彩色),第二个表示图片宽高(需要和css中设置的宽高一致),第三个表示背景颜色 # 得到一个Image对象img # 往画板中添加文字 draw = ImageDraw.Draw(img) # 得到一个draw对象 # 可这么理解:用ImageDraw这个画笔往 img 画板上书写 kumo_font = ImageFont.truetype("static/font/KumoFont.ttf", size=20) # 定义字体;第一个参数是字体样式的路径,第二个是字体大小 # 路径中 static 前不能加 / valid_code_str = "" # 用于保存验证码 for i in range(4): random_num = str(randint(0, 9)) # 数字 random_lower = chr(randint(97, 122)) # 小写 random_upper = chr(randint(65, 90)) # 大写 random_char = random.choice([random_num, random_lower, random_upper]) draw.text((i * 60 + 30, 5), random_char, get_random_color(), font=kumo_font) # draw.text():利用draw对象往画板里面书写文字;第一个参数是一个元组(x,y),表示横坐标、纵坐标的距离;第二个参数表示文字内容;第三个参数表示字体颜色;第四个表示字体样式 valid_code_str += random_char # 验证图片的噪点、噪线 width = 260 height = 33 # width 和 height要和前端验证图片的宽高一致 # 噪线 for i in range(5): x1 = randint(0, width) y1 = randint(0, height) # (x1,y1)是线的起点 x2 = randint(0, width) y2 = randint(0, height) # (x2,y2)是线的终点 draw.line((x1, y1, x2, y2), fill=get_random_color()) # 噪点 for i in range(100): draw.point([randint(0, width), randint(0, height)], fill=get_random_color()) # 在给定的坐标点上画一些点。 x = randint(0, width) y = randint(0, height) draw.arc((x, y, x + 4, y + 4), 0, 90, fill=get_random_color()) # 在给定的区域内,在开始和结束角度之间绘制一条弧(圆的一部分) # 参考链接: https://blog.csdn.net/icamera0/article/details/50747084 # 重点:储存随机生成的验证码(不能用 global 的方式去处理验证码 valid_code_str,因为此时当有其他用户登陆时验证码会被别人刷新掉;正确的方式是把该验证码存到 session 中 ) request.session["valid_code_str"] = valid_code_str # 注意:这句代码执行了三个操作过程 # 内存处理 f = BytesIO() # f就是一个内存句柄 img.save(f, "png") # 把img保存到内存句柄中;# save()之后就能把img保存到内存中 data = f.getvalue() # 把保存到内存中的数据读取出来 # BytesIO会有一个自动清除内存的操作 return data