公司通讯录产品设计
做任何开发前我们都要做一个产品的规划,公司通讯录虽然看起来很简单,但是这个步骤依然少不了。
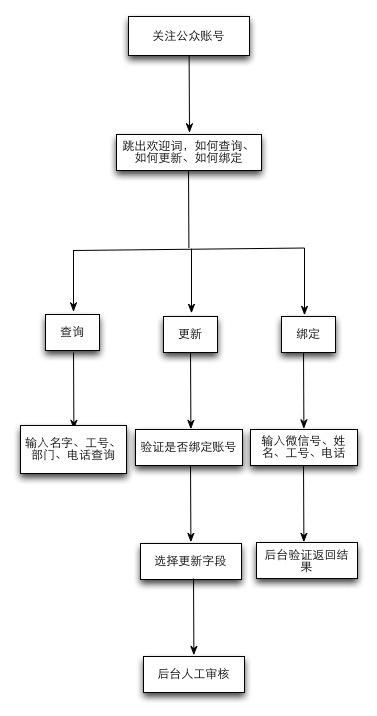
通讯录的功能:
1. 后台通讯录管理,包括分级、录入、修改、删除;
2. 后台日志查询,包括后台操作记录和前台修改记录;
3. 公司员工微信账号与通讯录绑定;
4. 已绑定账号可查询;
5. 部门、关键词等查询;
6. 前台已绑定账号可更新自己信息。
前台逻辑图:
数据库的设计
员工表:序号、姓名、工号、照片、性别、生日、手机、电话、部门、邮箱、微信号、员工状态
部门表:序号、部门名、上级部门序号、部门状态
日志表:序号、操作内容、操作时间、操作人、操作类别
管理员表:序号、用户名、密码
公司通讯录后台开发
我设计的公司通讯录是先人工输入到后台,然后前台进行绑定、查询、更新等操作
在开发前我们先要上传一个文件“base-class.php”,这个文件主要是用来做传递参数的过滤以及格式验证,比如是否邮箱、手机等是否正确输入
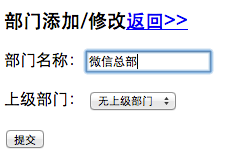
3.1、部门设置
第一个要开发的模块是部门设置,一般的公司架构都是多层级的,比如总经理-》部门-》小组,因此我们的部门设置里也要具备多层级的功能。
首先第一个页面部门录入页面,我们新建一个文件,命名为class_add.php,主要实现功能为添加和修改部门名称及上下级分类。代码如下:
后台页面是需要在浏览器里打开操作的,因此需要有HTML代码部分,一般正规开发都会将数据操作、逻辑操作、网页模板分离,我这里图方便就混排了。
这个页面实现的是两个功能:一是新增部门,二是修改部门,两个是放在同一个页面里的,那么如何判断是新增操作还是修改操作呢?根据url里是否有传递过来部门的序号即ID号,如果有就是修改,没有就是新增,具体后面会有解释。
命名为class_manager.php,代码如下:


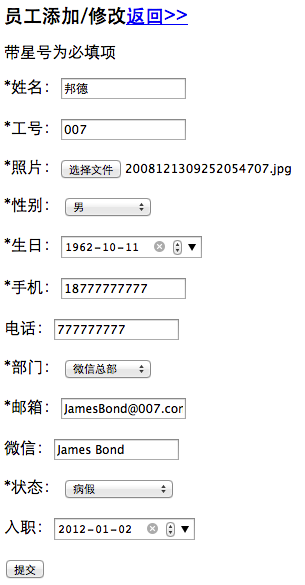
昨天有不少朋友在问如何测试不知道如何绑定账号,具体步骤是先在后台添加一个员工,然后在微信公众账号里根据提示将添加的员工信息输入完成绑定,如图添加一个员工:

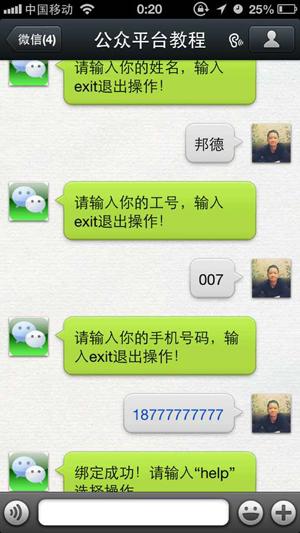
公司通讯录开发
微信账号绑定
微信用户的账号如何与自己网站的用户系统打通,这个是很多人关心的问题,其实很简单,我们都知道微信用户在关注公众号或者发送消息时都会有一个唯一的OPENID传过来,这个OPENID就是这个用户对应这个公众账号的唯一身份标示,我们只要将这个OPENID与自己网站的用户系统一一绑定就可以了。
方法有两种,一是将OPENID作为登陆页面或者注册页面的URL参数,当用户点击这个URL时跳转到WAP页面(即自己网站)上进行绑定,另外就是在对话框里进行绑定,我今天介绍的就是在对话框里进行绑定。
首先是检测用户是否绑定了微信号,这里我写了个函数,如下图:
第593行是定义函数的名字为check_user,函数传入的变量为$fromUsername,即微信用户的OPENID。
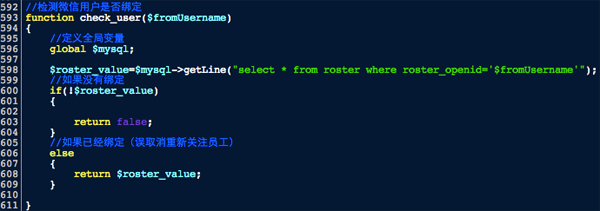
第598行是通过传入的OPENID为条件,检测在员工数据表中是否存在某条记录的roster_openid等于该OPENID。
第600到609行是返回函数运行的记过,如果有记录的话返回该条数据,如果没有就返回失败。
在用户关注公众账号时我就判断是否有绑定过账号,并且根据绑定情况回复不同的欢迎词,如下图:
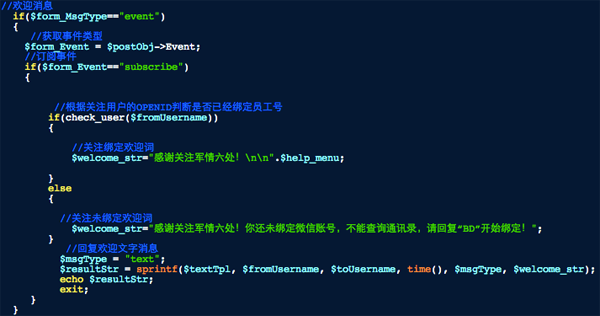
当检测到用户关注的事件,调用check_user这个函数,如果返回不是失败则提示使用帮助,否则提示绑定账号,效果如图:

当用户输入BD字符时进入账号绑定模式,如下图:
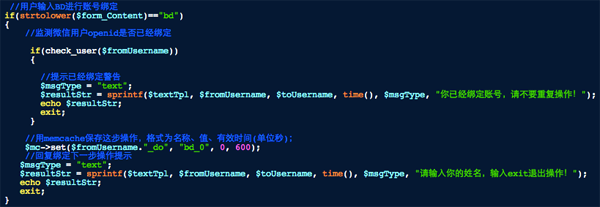
先判断用户是否已经绑定过,绑定过给提醒中断执行。否则进入绑定流程,由于绑定操作需要分多个步骤验证多个条件,然后一并查询数据库,因此我们要保存每一步的动作和数据,这里使用memcache来保存每个用户的上一步操作。这里先保存了BD_0标示这是绑定的第一个步骤,提示用户信息为“请输入你的姓名”。

memcache服务的开启请查看《微信公众平台入门到精通》Vol.13,在程序里使用方法为在代码最开头启动memcache,如下图:

保存memcache的方法为:
$mc->set(缓存变量名, 保存的数据, 0, 缓存时间单位秒);
读取memcache的方法为:
$mc->get(缓存变量名);
我在程序的开头加了获取memcache值的代码,每次用户请求时都会从memcache中获取用户上一步的操作和数据。其中$fromUsername."_do" 为用户操作,$fromUsername."_data" 为用户数据,用 $fromUsername 可以保证每个用户都有独立的缓存变量名。

接下来等用户输入姓名后,接口会收到新的请求,这个时候由于memcache保存过上步标示,因此这里会根据操作缓存的数据判断进入到第二步,$last_do的值是从程序开始就获取memcache值后获取的,如下图:
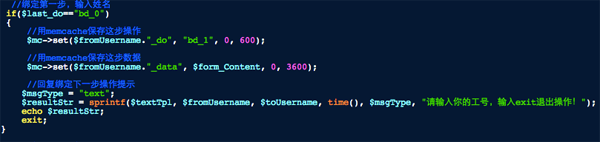
这里多了一个保存数据的缓存设置,保存了用户提交的姓名数据,同时将操作缓存的值改为了BD_1,然后继续提示用户输入工号。
当用户输入工号后,会进入第三步,如下图:
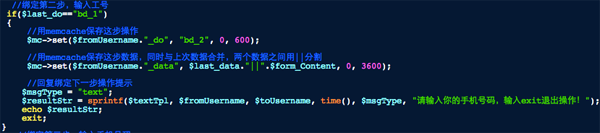
继续保存数据,将上一步的数据(姓名)与本次数据(工号)合并用“||”分割,同时将操作缓存的值改为了BD_2,然后继续提示用户输入手机号。

当用户输入手机号后,就进入最后一步验证,如下图:
进入最后一步后先清空操作和数据缓存,然后将之前保存的数据$last_do加上本次用户输入内容合并转换成数组,并用list函数分别赋值给$roster_name,$roster_number,$roster_mp。
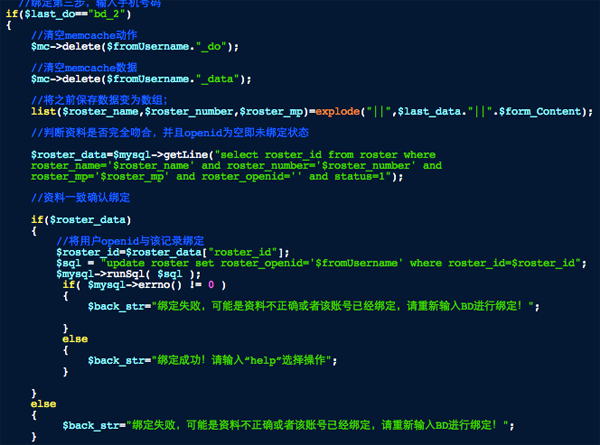
再进行数据库查询满足用户姓名、工号和手机与输入数据完全相同并且roster_openid(员工openid)为空的记录,如果有符合条件的记录则更新该记录,将$fromUsername(当前操作用户的openid)保存到roster_openid里,完成绑定。
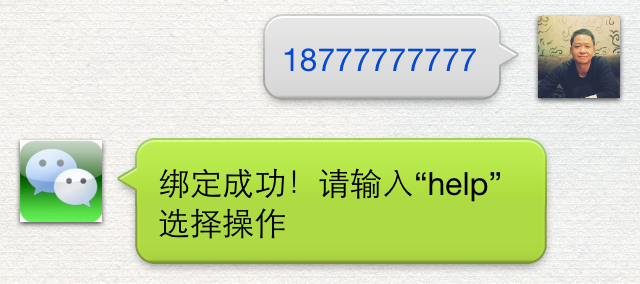
这个时候我们输入“help”就会可以进行后续操作了。
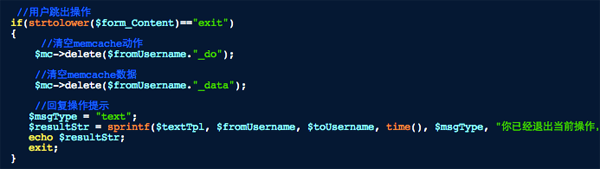
PS:“输入exit退出操作”这个也很简单,当用户输入exit的时候程序会清空操作和数据缓存,也就是说所有之前的操作和数据都没有了,即所有操作重新开始,如下图:
这个流程使用了memcache来保存一些临时变量和多步骤操作,除了用来绑定用户账户外,也适合一些调查问卷或者注册登陆操作。
微信搜索
搜索其实就是编辑模式下的关键字自动回复,我这里拿姓名搜索举例,首先我们要先切换当前模式到姓名搜索,如下图:
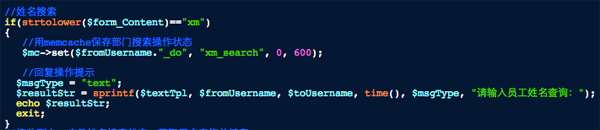
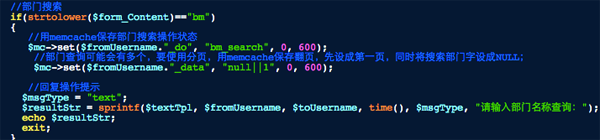
这部分代码与账号绑定的第一步是一样的,我们用memcache存放当前的操作,这个时候存放操作动作的缓存变量里就标示了当前是在姓名搜索状态下。同时输出提示,请输入员工姓名。

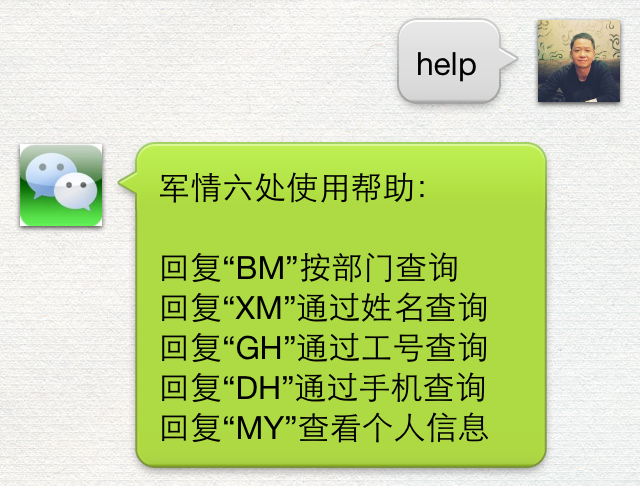
其实这步可以理解为进入网站的二级导航页面,一个网站有首页和各种导航栏目,那么在这个通讯录里帮助就是首页,你输入HELP就到了首页,输入XM就到员工查询这个二级栏目,之后除非你输入BM、GH等一些栏目名,其他的操作都默认是在员工栏目下进行。
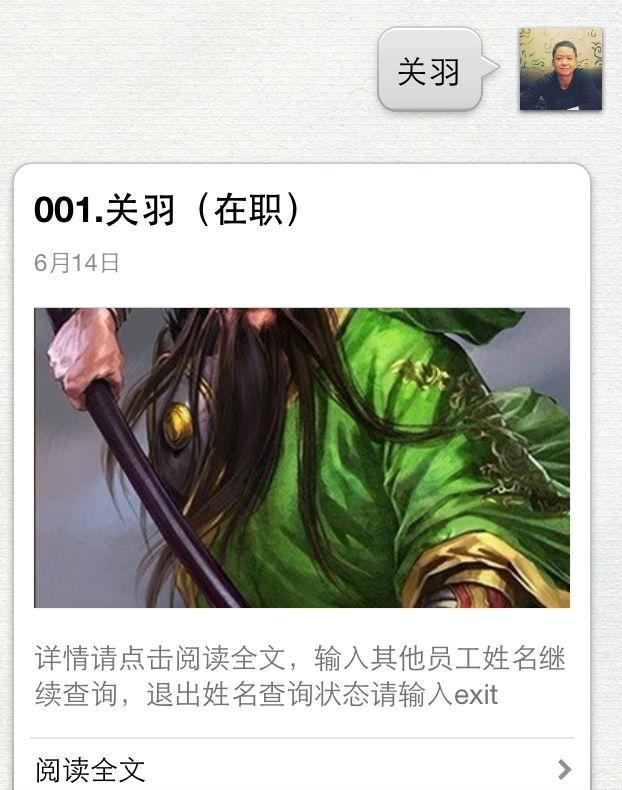
然后根据提示输入员工名字进行查询,如下图:
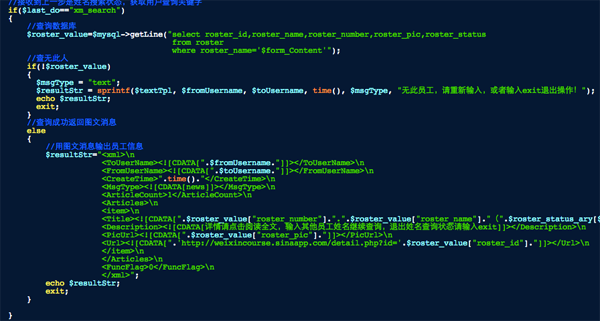
从数据库中查找与用户输入一致的记录,如果没有则返回提醒:

如果查询到则返回一个图文消息,这里没有去考虑员工重名的情况,所以查询和返回结果都是只取一条记录的。
前端展现原因我只取工号、姓名、当前状态、照片等字段返回,查看详情点击阅读原文进入到detail页,把该员工的ID号(不是工号)作为URL参数传递过去,然后再做一次数据库查询将所有字段提取出来展现。

微信翻页
很多人非常好奇ZTalk的公众账号是如何实现文章查询翻页的,其实原理也很简单,只是把网页上的翻页代码稍微改装一下,然后使用memcache保存每个用户当前的页码和搜索的关键字就可以了。
在通讯录里是用部门查询来示例的,首先依然是进入部门查询这个栏目,如下图:
上面的代码除了保存当前操作状态为部门查询以外,又用另外一个memcache的变量保存当前搜索关键字和页码“null || 1”,其中null为当前搜索关键字(因为一开始用户没有输入所以是空的),1表示起始页是第一页,然后输出提示,请输入部门名称。

当用户输入部门名称后,先查询这个部门的ID号,因为在员工表里没有直接存放部门名称而是存放的与部门对应的ID号,如下图:
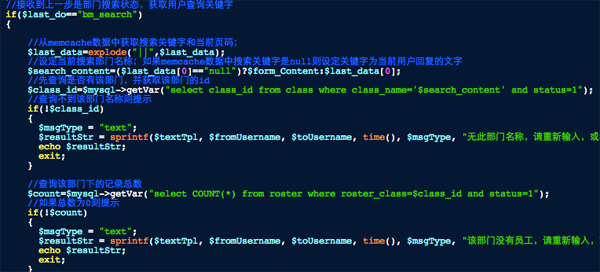
在这里我们获取搜索关键字会有两个来源,一个是用户输入的,一个是在翻页时在缓存中保存的,所以先得尝试从缓存里获取用户之前保存的搜索关键字,如果值为null则表示这是第一次搜索,关键字为用户输入的$from_content,否则就使用缓存中保存的关键字,这就是为什么能够翻页的关键,我们利用缓存机制存放了用户之前输入的搜索关键字。
有了搜索关键字然后查询部门表获取部门ID号,获取到后再去查询员工表里该ID下的员工总数,如果总数为0则表示该部门还没有员工直接提示。否则进入到翻页计算和结果返回,如下图:
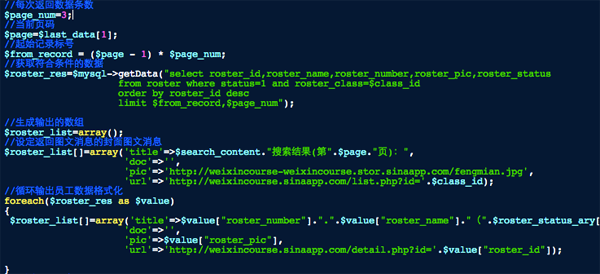
第一个是设置每页显示的条数,我这里是设置成3条,加上封面消息和尾部翻页提示消息最后显示会是5条。
当前页码是从缓存中获取,$last_data在前面已经使用explode函数以||为分割字符变成数组,$last_data[0]为搜索关键字,$last_data1为页码,根据当前页码计算数据库查询开始的记录指针位置。
查询出结果后进行数据转化,这里做了一个数组方便后面循环输入多图文消息,每个图文消息其实就4个元素:标题、描述、图片、链接,先直接用搜索关键字+当前页等做一个封面消息,然后循环将数据库查询结果也转化成图文消息的元素。
然后是判断是否有下一页,如下图:
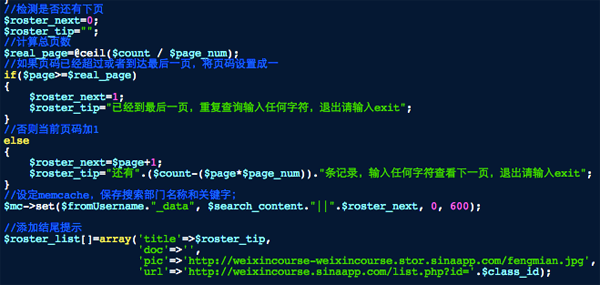
用符合搜索条件的记录总数去除以每页显示数量,ceil是一个向上舍入为最接近的整数的函数,就是ceil(5/4)=2,而不是1.25,这样就知道总页数了,然后判断当前页是否最后一页,如果不是最后一页则将当前页加1然后存放到memcache里,在下次翻页查询时保存数据的这个memcache变量里其实已经变成“搜索关键字||2”。
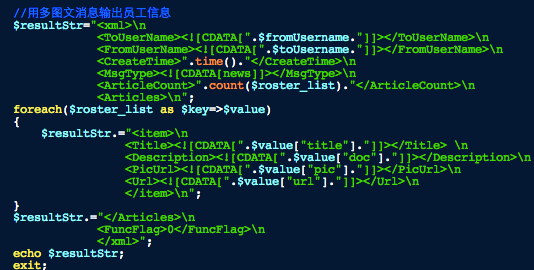
最后就是输出多图文消息了,如下图:
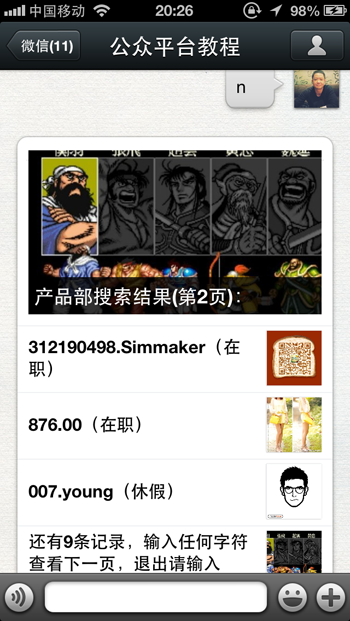
在微信里显示的效果如下:
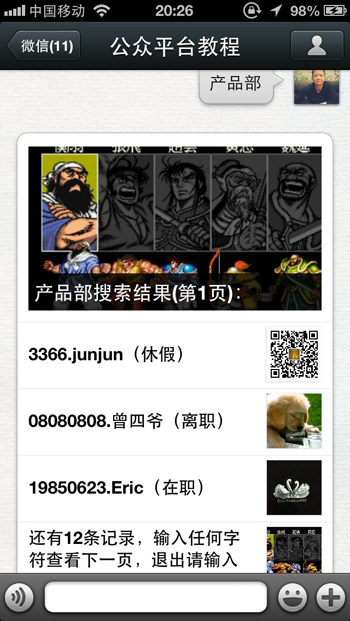
可能还有很多人很迷茫,如何输入任何字符查看下一页的呢?我画个流程图可能会比较清楚,看下图:
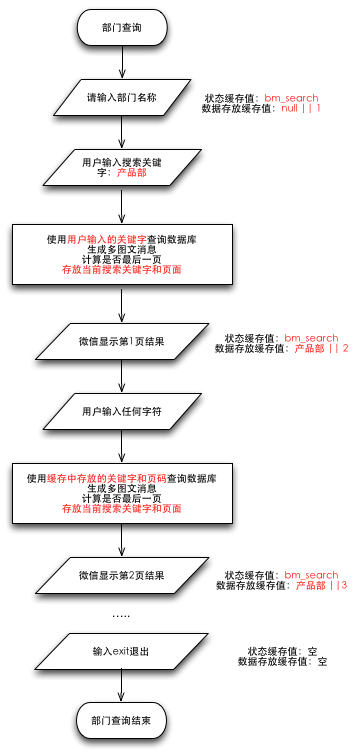
大家可以看到其实从第二页开始用户输入的字符只是触发程序运行,而不能干涉程序运行的结果,除非输入EXIT,或者HELP这些一级栏目关键字。