基础模块
def prt(age,name):#函数定义
print("%s is %d 年龄 old"%(name,age))
if __name__=="__main__":#程序入口
print("Hello World")
prt(45,"gaici")
获取输入:使用input()函数
name=input("you name ?")
python的文件类型主要分为3类,分别是源代码、字节代码和优化代码。
1、源代码:文件以“py”为扩展名,“pyw”是图形用户接口的源文件的扩展名。
2、字节代码:python源文件经过编译后生成扩展名为"pyc"的文件,此文件是与平台无关的,可通过脚本生成该类型的文件。
import py_compile
py_compile.compile("ps.py")
运行后即可得到ps.pyc文件
3、优化代码:经过优化的源文件生成扩展名为“pyo”,该类型的文件需要命令行工具生成。
在命令行中输入“python2.7 -O -m py_compile ps.py”生成文件为ps.pyo而
"python3.5 -O -m py_compile ps.py"生成的文件为ps.pyc
类的私有变量、私有方法以两个下划线作为前缀。
class Student: #类名首字母大写
__name="" #私有实例变量前必须有2个下划线
def __init__(self,name): #构造函数
self.__name=name #self相当于Java中的this
def getName(self): #方法名首字母小写,其后每个单词的首字母用大写
return self.__name
def __del__(self): #析构函数
self.__name=None
if __name__=="__main__":
student=Student("borphi") #对象名用小写字母
print(student.getName())
注:python对代码缩进的要求非常严格。如果程序中不采用代码缩进的编码风格,将抛出一个IndentationError异常。
模块是类或函数的集合,用于实现某个功能。在Python中,如果需要在程序中调用标准库或其他第三方库的类时,需要先使用import或from ... import语句导入相关的模块。
1、import语句 如:import sys
2、from ... import ...:导入模块指定的类或函数。 如:from sys import path
函数之间或类的方法之间用空行分隔,表示一段新的代码的开始。与缩进不同,空行并不是python语法的一部分。只是为增加程序可读性而已。
python以“#”作为注释,特殊的注释有:
1、中文注释 #-*-coding:UTF-8-*-
2、跨平台注释 #! /usr/bin/python
python也支持分号,但可以省略,python主要通过换行来识别语句的结束。python同样支持多行写一条语句,使用“\”作为换行符。
如:
sql="select id,name" \
"from dept" \
"where name='A"
局部变量是只能在函数或代码段内使用的变量。python并没有提供定义常量的保留字。
python中的字符串,可以用单引号、双引号和三引号来包括。其中三引号保持字符原样输出,不做任何处理(占位符除外)。
python内置的几种数据结构:元组、列表、字典和序列。
1、元组(Tuple):元组由不同的元素组成,每个元素可以存储不同类型的数据,元组是“写保护”的,即元组创建后不能再做任何修改操作,也不能添加或删除任何元素。元组通常代表一行数据,而元组中的元素代表不同的数据项。tuple_name=(元素1,元素2,...)元组的访问可以通过索引访问。
元组的遍历需要用到range()和len()这两个函数
tuple=(("apple","banana"),("grape","orange"),("watermelon",),("grapefruit",))
for i in range(len(tuple)):
print("tuple[%d]:"%i,"")
for j in range(len(tuple[i])):
print(tuple[i][j], "")
2、列表(List):通常作为函数的返回类型,可以实现添加(append())、删除(remove())和查找(index())操作,元素的值可以被修改。list_name=[元素1,元素2,...]
list0=["apple","banana","grape","orange"]
list0.append("watermelon")
list0.insert(1,"grapefruit")
list0.remove("banana") #如果列表中存在2个相同的元素,只删除位置靠前的。
print(list0.pop())
print(list0[-2])
print(list0[1:3])
print(list0[-3:-1])
print(list0.index("grape"))
print("orange" in list0)
list0.sort()
list0.reverse()
list1=[["apple","banana"],["grape","orange"],["watermelon"],["grapefruit"]]
for i in range(len(list1)):
print("list[%d]:"%i,"")
for j in range(len(list1[i])):
print(list1[i][j])
list0.extend(list1)
list0=list0+list1
list3=["apple","banana"]*2
print(list3)
注:用列表可以实现堆栈(append()、pop())和队列(append()、pop(0))
3、字典(Dictionary):字典是由“键-值”对组成的集合,字典中的“值”通过“键”来引用。dictionary_name={key1:value1,key2:value2, ... }
注意:字典的书写顺序不是字典实际存储顺序,字典根据每个元素的Hashcode值进行排列。
dict={"a":"apple","b":"banana","g":"grape","o":"orange"} #创建
dict["w"]="watermelon" #添加
del(dict["a"]) #删除
dict["g"]="grapefruit" #修改
print(dict.pop("b"))
dict.clear()
#字典的遍历
for k in dict:
print("dict[%s]="%k,dict[k])
print(dict.items())#返回由元组组成的列表
for (k,v) in dict.items():
print("dict[%s]="%k,v)
print(dict.keys())#输出key的列表
print(dict.values())#输出value的列表
4、序列:具有索引和切片能力的集合,元组、列表和字符串都属于序列。
包、模块、函数
python的程序由包(package)、模块(module)和函数组成。包是一系统模块组成的集合。模块是处理某一类问题的函数和类的集合。
包是一个完成特定任务的工具箱,python提供了许多有用的工具包,如字符串处理、图形用户接口、Web应用、图形图像处理等。
注意:包必须至少含有一个__init__.py文件,该文件内容可以为空。__init__.py用于标识当前文件夹是一个包。
1、模块把一组相关的函数或代码组织到一个文件中。一个Python文件即是一个模块。模块由代码、函数或类组成。
当python导入一个模块时,python首先查找当前路径,然后查找lib目录、site-package目录(python\lib\site-packages)和环境变量PYTHONPATH设置的目录。
模块导入
import 模块名
导入模块一次与多次的意义是一样的。
重新导入:hello=reload(hello)
如果不想在程序中使用前缀符,可以使用from ... import ...语句将模块导入。
from module_name import function_name
将函数存储在被称为模块的独立文件中, 再将模块导入到主程序中。import语句允许在当前运行的程序文件中使用模块中的代码。
通过将函数存储在独立的文件中,可隐藏程序代码的细节,将重点放在程序的高层逻辑上。将函数存储在独立文件中后,可与其他程序员共享这些文件而不是整个程序。
导入整个模块
要让函数是可导入的,得先创建模块。模块 是扩展名为.py的文件,包含要导入到程序中的代码。
import pizza
Python读取这个文件时,代码行import pizza让Python打开文件pizza.py,并将其中的所有函数都复制到这个程序中。
只需编写一条import 语句并在其中指定模块名,就可在程序中使用该模块中的所有函数。如果你使用这种import 语句导入了名为module_name.py 的整个模块,就可使用下面的语法来使用其中任何一个函数: module_name.function_name()
导入特定的函数
from module_name import function_name
通过用逗号分隔函数名,可根据需要从模块中导入任意数量的函数:
from module_name import function_0, function_1, function_2
使用as 给函数指定别名
如果要导入的函数的名称可能与程序中现有的名称冲突,或者函数的名称太长,可指定简短而独一无二的别名 ——函数的另一个名称,类似于外号。要给函数指定这种特殊外 号,需要在导入它时这样做。
from pizza import make_pizza as mp
使用as 给模块指定别名
还可以给模块指定别名。通过给模块指定简短的别名(如给模块pizza 指定别名p ),让你能够更轻松地调用模块中的函数。
import pizza as p
p.make_pizza(16, 'pepperoni')
导入模块中的所有函数
使用星号(* )运算符可让Python导入模块中的所有函数:
from pizza import *
make_pizza(16, 'pepperoni')
import 语句中的星号让Python将模块pizza中的每个函数都复制到这个程序文件中。由于导入了每个函数,可通过名称来调用每个函数,而无需使用句点表示法。
最佳的做法是,要么只导入你需要使用的函数,要么导入整个模块并使用句点表示法。这能让代码更清晰,更容易阅读和理解。
模块的属性
模块有一些内置属性,用于完成特定的任务,如__name__、__doc__。每个模块都有一个名称。例如,__name__用于判断当前模块是否是程序的入口,如果当前程序正在被使用,__name__的值为“__main__”。通常给每个模块都添加一个条件语句,用于单独测试该模块的功能。例如,创建一个模块myModule:
if __name__=="__main__":
print("myModule作为主程序运行")
else:
print("myModule被另一个模块调用")
__doc__可以输出文档字符串的内容。
模块内置函数:
1、apply():可以实现调用可变参数列表的函数,把函数的参数存放在一个元组或序列中。
apply(func [,args [,kwargs]])
2、filter():可以对某个序列做过滤处理,对自定义函数的参数返回的结果是否为“真”来过滤,并一次性返回处理结果
filter(func or None,sequence) -> list, tuple, or string
3、reduce():对序列中元素的连续操作可以通过循环来处理。
reduce(func,sequence[,initial])->value
4、map():多个序列的每个元素都执行相同的操作,并组成列表返回。
map(func,sequence[,sequence, ...]) ->list
2、自定义包
包就是一个至少包含__init__.py文件的文件夹。例如,定义一个包parent,parent包中包含2个子包pack和pack2。pack包中包含myModule模块,pack2包中包含myModule2模块。
pack包的__init__.py
__all__=["myModule"] #用于记录当前包所包含的模块,如果模块多于2个,用逗号分开。这样就可在调用时一次导入所有模块
if __name__=="__main__":
print("作为主程序运行")
else:
print("pack初始化")
pack包的myModule.py
def func():
print("pack.myModule.func()")
if __name__=="__main__":
print("myModule作为主程序运行")
else:
print("myModule被另一个模块调用")
pack2包__init__.py
__all__=["myModule2"] #用于记录当前包所包含的模块,如果模块多于2个,用逗号分开。这样就可在调用时一次导入所有模块
if __name__=="__main__":
print("作为主程序运行")
else:
print("pack2初始化")
包pack2的myModule2:
def func():
print("pack2.myModule.func2()")
if __name__=="__main__":
print("myModule2作为主程序运行")
else:
print("myModule2被另一个模块调用")
parent模块调用:
from pack import *
from pack2 import *
myModule.func()
myModule2.func2()
3、函数
定义:
def 函数名(参数1[=默认值1],参数2[=默认值2] ...):
...
return 表达式
调用:
函数名(实参1, 实参2, ...)
注意:实参必须与形参一一对应,如果参数提供默认值,顺序可以不一致。
位置实参 :调用函数时,Python必须将函数调用中的每个实参都关联到函数定义中的一个形参。为此,最简单的关联方式是基于实参的顺序。
def describe_pet(animal_type, pet_name):
"""显示宠物的信息"""
print("\nI have a " + animal_type + ".")
print("My " + animal_type + "'s name is " + pet_name.title() + ".")
describe_pet('hamster', 'harry')
关键字实参:是传递给函数的名称—值对。你直接在实参中将名称和值关联起来了,因此向函数传递实参时不会混淆(不会得到名为Hamster的harry这样的结果)。关键字实参让你无需考虑函数调用中的实参顺序,还清楚地指出了函数调用中各个值的用途。
def describe_pet(animal_type, pet_name):
"""显示宠物的信息"""
print("\nI have a " + animal_type + ".")
print("My " + animal_type + "'s name is " + pet_name.title() + ".")
describe_pet(animal_type='hamster', pet_name='harry')
默认值
def describe_pet(pet_name, animal_type='dog'):
"""显示宠物的信息"""
print("\nI have a " + animal_type + ".")
print("My " + animal_type + "'s name is " + pet_name.title() + ".")
describe_pet(pet_name='willie')
禁止函数修改列表
function_name(list_name[:]) #要将列表的副本传递给函数
传递任意数量的实参
def make_pizza(*toppings):
"""打印顾客点的所有配料"""
print(toppings)
make_pizza('pepperoni')
make_pizza('mushrooms', 'green peppers', 'extra cheese')
使用任意数量的关键字实参
def build_profile(first, last, **user_info):
"""创建一个字典,其中包含我们知道的有关用户的一切"""
profile = {}
profile['first_name'] = first
profile['last_name'] = last
for key, value in user_info.items():
profile[key] = value
return profile
user_profile = build_profile('albert', 'einstein', location='princeton',field='physics')
print(user_profile)
说明:形参**user_info 中的两个星号让Python创建一个名为user_info 的 空字典,并将收到的所有名称—值对都封装到这个字典中。
在函数中为了获得对全局变量的完全控制(主要用于修改全局变量),需要使用关键字global。
python中的任何变量都是对象,所以参数只支持引用传递的方式。即形参和实参指向内存的同一个存储空间。
python不仅支持函数体内的嵌套,还支持函数定义的嵌套。
函数嵌套的层数不宜过多,就控制在3层以内。
# 嵌套函数
def func():
x=1
y=2
m=3
n=4
def sum(a,b): # 内部函数
return a+b
def sub(c,d): # 内部函数
return c-d
return sum(x,y)*sub(m,n)
print(func())
注意:尽量不要在函数内部定义函数。
lambda函数
lambda函数用于创建一个匿名函数。
func=lambda 变量1, 变量1, ... : 表示式
调用:func()
# lambda
def func():
x=1
y=2
m=3
n=4
sum=lambda a,b:a+b
sub=lambda c,d:c-d
return sum(x,y) * sub(m,n)
print(func())
注意:lambda也称之为表达式,只能使用表达式,不能使用判断、循环等多重语句。
Generator函数
生成器(Generator)的作用是一次产生一个数据项,并把数据项输出。可以用在for循环中遍历。Generator函数所具有的每次返回一个数据项的功能,使得迭代器的性能更佳。定义如下:
def 函数名(参数列表):
...
yield 表达式
Generator函数的定义与普通函数的定义没有什么区别,只要在函数体内使用yield生成数据项即可。
Generator函数可以被for循环遍历,而且可以通过next()方法获得yield生成的数据项。
# 定义Generator函数
def func(n):
for i in range(n):
yield i
#在for循环中输出
for i in func(3):
print(i)
#使用next()输出
r=func(3)
print(r.__next__())
print(r.__next__())
print(r.__next__())
注意:yield保留字与return语句的返回值和执行原理并不相同。yield生成值并不会中止程序的执行,返回值继续往后执行。return返回值后,程序将中止执行。
字符串
1、字符串格式化
Python将若干值插入到带“%”标记的字符串中,语法如下
"%s" % str1
"%s %s"% (str1,str2)
注意:如果要格式化多个值,元组中元素的顺序必须和格式化字符串中替代符的顺序一致。
Python格式化字符串的替代符及其含义
注意:如果要在字符串中输出“%”,则需要使用“%%”。
2、字符串的转义符
Python中转义字符的用法与Java相同,都是使用“\”作为转义字符。
Python的转义字符及其含义
注意:如果要在字符串中输出"\",需要使用“\\”
3、字符串合并
Python使用“+”连接不同的字符串,如果两侧都是字符串,执行连接操作,如果两侧都是数字类型,则执行加法运算;如果两侧类型不同,则抛出异常:TypeError
4、字符串的截取
Python字符串内置了序列,可以通过“索引”、“切片”获取子串,也可以使用函数split来获取。
切片的语法格式如下所示:string[start:end:step]
5、字符串的比较
Python直接使用“==”、“!=”运算符比较两个字符串的内容。startswith()、endswith()
6、字符串反转
Python使用列表和字符串索引来实现字符串的反转,并通过range()进行循环。
# 循环输出反转的字符串
def reverse(s):
out=""
li=list(s)
for i in range(len(li),0,-1):
out+="".join(li[i-1])
return out
利用序列的“切片”实现字符串反转最为简洁:
# 循环输出反转的字符串
def reverse(s):
return s[::-1]
7、字符串的查找和替换
查找:find()、rfind()
替换:replace():不支持正则
8、字符串与日期转换
Python提供了time模块处理日期和时间
从时间到字符串的转换strftime(),格式:strftime(format[,tuple])->string
格式化日期常用标记
字符串到日期的转换:需要进行两次转换,使用time模块和datetime类。转换过程分为3个步骤。
(1)、调用函数strptime()把字符串转换为一个元组,进行第一次转换,格式如下
strptime(string,format)->struct_time
(2)、把表示时间的元组赋值给表示年、月、日的3个变量
(3)、把表示年、月、日的3个变量传递给函数datetime(),进行第2次转换,格式如下
datetime(year,month,day[,hour[,minute[,second[,microsecond[,tzinfo]]]])
正则表达式
1、基础
正则表达式中的特殊字符
正则表达式中的常用限定符
限定符与“?”的组合
2、使用syt.re模块处理正则表达式
re模块的规则选项
pattern对象的属性和方法
match对象的方法和属性
类与对象
1、类
定义:
class Fruit:
def grow(self): #类的方法必须有1个self参数,但是方法调用时可以不传这个参数
print("Fruit grow ...")
if __name__=="__main__":
fruit=Fruit()
fruit.grow()
2、对象的创建
if __name__=="__main__":
fruit=Fruit()
fruit.grow()
属性和方法
1、python类的属性分为私有属性和公有属性,但python并没有提供公有属性和私有属性的修饰符。类的私有属性不能被该类之外的函数调用,类属性的作用范围完全取决于属性的名称。如果函数、方法或属性的名字以两个下划线开始,则表示私有类型;没有使用两个下划线开始则表示公有属性。
python的属性分为实例属性和静态属性。实例属性是以self作为前缀的属性。__init__方法即Python类的构造函数。如果__init__方法中定义的变量没有使用self作为前缀声明,则该变量只是普通的局部变量。在python中静态变量称之为静态属性。
class Fruit:
price=0 #类属性
def __init__(self):
self.color="red" #实例属性
zone="China" #局部变量
if __name__=="__main__":
print(Fruit.price)
apple=Fruit()
print(apple.color)
Fruit.price=Fruit.price+10
print("apple's price:"+str(apple.price))
banana=Fruit()
print("banana's price:" + str(banana.price))
注意:Python的类和对象都可以访问类属性。
python提供了直接访问私有属性的方式,可用于程序的测试和调试,访问的格式如下:
instance_classname_attribute #instance表示对象;classname表示类名;attribute表示私有属性。
class Fruit:
def __init__(self):
self.__color="red" #私有属性
if __name__=="__main__":
apple=Fruit()
print(apple._Fruit__color)
类提供了一些内置属性,用于管理类的内部关系。如,__dict__、__bases__、__doc__等
2、类的方法
类的方法也分为公有方法和私有方法。私有函数不能被该类之外的函数调用,私有方法也不能被外部的类或函数调用。Python使用函数staticmethod()或"@staticmethod"指令的方式把普通函数转换为静态方法。Python的静态方法并没有和类的实例进行名称绑定,Python的静态方法相当于全局函数。
class Fruit:
price = 0
def __init__(self):
self.__color="red" #私有属性
def getColor(self):
print(self.__color)
@staticmethod
def getPrice():
print(Fruit.price)
def __getPrice():
Fruit.price=Fruit.price+10
print(Fruit.price)
count=staticmethod(__getPrice)
if __name__=="__main__":
apple=Fruit()
apple.getColor()
Fruit.count()
banana = Fruit()
Fruit.count()
Fruit.getPrice()
Python中还有一种方法称之为类方法。类方法的作用与静态方法相似,都可以被其它实例对象共享,不同的是类方法必须提供self参数。类方法可以使用函数classmethod()或“@classmethod”指令定义。
class Fruit:
price = 0
def __init__(self):
self.__color="red" #私有属性
def getColor(self):
print(self.__color)
@classmethod
def getPrice(self):
print(self.price)
def __getPrice(self):
self.price=self.price+10
print(self.price)
count=classmethod(__getPrice)
if __name__=="__main__":
apple=Fruit()
apple.getColor()
Fruit.count()
banana = Fruit()
Fruit.count()
Fruit.getPrice()
如果某个方法需要被其他实例共享,同时又需要使用当前实例的属性,则将其定义为类方法。
3、内部类的使用
内部类中的方法可以使用两种方法调用
第一种方法是直接使用外部类调用内部类,生成内部类的实例,再调用内部类的方法,调用格式如下所示:
object_name=outclass_name.inclass_name()
object_name.method()
第二种方法是先对外部类进行实例化,然后再实例化内部类,最后调用内部类
out_name=outclass_name()
in_name=out_name.inclass_name()
in_name.method()
内部类使用方法:
class Car:
class Door: #内部类
def open(self):
print("open door")
class Wheel: #内部类
def run(self):
print("car run")
if __name__=="__main__":
car=Car()
backDoor=Car.Door() #内部类的实例化方法一
frontDoor=car.Door() #内部类的实例化方法二
backDoor.open()
frontDoor.open()
wheel=Car.Wheel()
wheel.run()
4、__init__方法
python的构造函数名为__init__。__init__方法除了用于定义实例变量外,还用于程序的初始化。__init__方法是可选的,如果不提供__init__方法,Python将会给出一个默认的__init__方法。
5、__del__方法
Python提供了析构函数__del__()。析构函数可以显式的释放对象占用的资源,析构函数也是可选的,如果程序不提供析构函数,Python会在后台提供默认的析构函数。
如果要显式的调用析构函数,可以使用del语句,在程序的末尾添加如下语句
del fruit #执行析构函数
6、垃圾回收机制
Python也采用垃圾回收机制清除对象,Python提供了gc模块释放不再使用的对象。垃圾回收的机制有许多种算法,Python采用的是引用计算的方式。函数collect()可以一次性收集所有待处理的对象。
import gc
class Fruit:
def __init__(self,name,color): #初始化name,color属性
self.__name=name
self.__color=color
def getColor(self):
return self.__color
def setColor(self,color):
self.__color=color
def getName(self):
return self.__name
def setName(self,name):
self.__name=name
class FruitShop: #水果店类
def __init__(self):
self.fruits=[]
def addFruit(self,fruit): #添加水果
fruit.parent=self #把Fruit类关联到FruitShop类
self.fruits.append(fruit)
if __name__=="__main__":
shop=FruitShop()
shop.addFruit(Fruit("apple","red"))
shop.addFruit(Fruit("banana", "yellow"))
print(gc.get_referents(shop))
del shop
print(gc.collect()) #显式调用垃圾回收器
7、类的内置方法
__new__()
__new__()在__init__()之前调用,用于生成实例对象。利用这个方法和类属性的特性可以实现设计模式中的单例模式。
class Singleton(object):
__instance=None #定义实例
def __init__(self):
pass
def __new__(cls, *args, **kwargs): #在__init__之前调用
if Singleton.__instance is None: #生成唯一实例
Singleton.__instance=object.__new__(cls,*args,**kwargs)
return Singleton.__instance
8、方法的动态特性
Python作为动态脚本语言,编写的程序具有很强的动态性。可以动态添加类的方法,把某个已经定义的函数添加到类中。添加新方法的语法格式如下所示:
class_name.method_name=function_name
注意:function_name表示一个已经存在的函数
class Fruit:
pass
def add(self):
print("grow ...")
if __name__=="__main__":
Fruit.grow=add()
fruit=Fruit()
fruit.grow()
继承
Python不提倡过度包装。继承可以重用已经存在的数据和行为,减少代码的重复编写。Python在类名后使用一对括号表示继承关系,括号中的类即为父类。如果父类定义了__init__方法,子类必须显式调用父类的__init__方法。如果子类需要扩展父类的行为,可以添加__init__方法的参数。
class Fruit():
def __init__(self,color):
self.color=color
print("fruit's color:%s"%self.color)
def grow(self):
print("grow ...")
class Apple(Fruit):
def __init__(self,color):
Fruit.__init__(self,color)
print("apple's color:%s"%self.color)
class Banana(Fruit):
def __init__(self,color):
Fruit.__init__(self,color)
print("banana's color:%s"%self.color)
def grow(self):
print("banana grow ...")
if __name__=="__main__":
apple=Apple("red")
apple.grow()
banana=Banana("yellow")
banana.grow()
还可以使用super类的super()调用父类的__init__方法。super()可以绑定type类的父类。
super(type,obj)
class Fruit(object):
def __init__(self):
print("parent")
class Apple(Fruit):
def __init__(self):
super(Apple, self).__init__()
print("apple child")
if __name__=="__main__":
Apple()
注意:super类的实现代码继承了object,因此Fruit类必须继承object.如果不继承object,使用super()将出现错误。
python没有提供对接口的支持。
运算符的重载
Python把运算符和类的内置方法关联起来,每个运算符都对应1个函数。
class Fruit:
def __init__(self,price=0):
self.price=price
def __add__(self, other): #重载加号运算符
return self.price+other.price
def __gt__(self, other): #重载大于运算符
if self.price>other.price:
flag=True
else:
flag=False
return flag
class Apple(Fruit):
pass
class Banana(Fruit):
pass
python工厂方法模式
工厂方法类图
实现方法
class Factory: #工厂类
def createFruit(self,fruit): #工厂方法
if fruit=="apple":
return Apple()
elif fruit=="banana":
return Banana()
class Fruit:
def __str__(self):
return "fruit"
class Apple(Fruit):
def __str__(self):
return "apple"
class Banana(Fruit):
def __str__(self):
return "banana"
if __name__=="__main__":
factory=Factory()
print(factory.createFruit("apple"))
print(factory.createFruit("banana"))
异常处理与程序调试
Python中的异常类定义在exceptions模块中,并继承自基类BaseException。BaseException类是属于new-style class,BaseException类下有3个子类,分别是Exception、KeyboardInterrupt、SystemExit。
Exception类是最常用的异常类,该类包括StandardError、StopIteration、GeneratorExit、Warning等异常类。
BaseException
+-- SystemExit
+-- KeyboardInterrupt
+-- GeneratorExit
+-- Exception
+-- StopIteration
+-- StopAsyncIteration
+-- ArithmeticError
| +-- FloatingPointError
| +-- OverflowError
| +-- ZeroDivisionError
+-- AssertionError
+-- AttributeError
+-- BufferError
+-- EOFError
+-- ImportError
+-- LookupError
| +-- IndexError
| +-- KeyError
+-- MemoryError
+-- NameError
| +-- UnboundLocalError
+-- OSError
| +-- BlockingIOError
| +-- ChildProcessError
| +-- ConnectionError
| | +-- BrokenPipeError
| | +-- ConnectionAbortedError
| | +-- ConnectionRefusedError
| | +-- ConnectionResetError
| +-- FileExistsError
| +-- FileNotFoundError
| +-- InterruptedError
| +-- IsADirectoryError
| +-- NotADirectoryError
| +-- PermissionError
| +-- ProcessLookupError
| +-- TimeoutError
+-- ReferenceError
+-- RuntimeError
| +-- NotImplementedError
| +-- RecursionError
+-- SyntaxError
| +-- IndentationError
| +-- TabError
+-- SystemError
+-- TypeError
+-- ValueError
| +-- UnicodeError
| +-- UnicodeDecodeError
| +-- UnicodeEncodeError
| +-- UnicodeTranslateError
+-- Warning
+-- DeprecationWarning
+-- PendingDeprecationWarning
+-- RuntimeWarning
+-- SyntaxWarning
+-- UserWarning
+-- FutureWarning
+-- ImportWarning
+-- UnicodeWarning
+-- BytesWarning
+-- ResourceWarning
StandardError类中常见的异常
Python使用try ... exception语句捕获异常,异常类型定义在try子句的后面。
注意:如果在except子句后将异常类型设置为"Exception",异常处理程序将捕获除程序中断外的所有异常,因为Exception类是其他异常类的基类。
try ... exception用法:
try:
file("hello.txt",'r')
print('读文件')
except IOError:
print("文件不存在")
except:
print("程序异常")
else:
print("结束")
try ... finally用法
try:
f=file("hello.txt",'r')
print('读文件')
except IOError:
print("文件不存在")
finally:
f.close()
使用raise抛出异常
可以通过raise语句显式引发异常。一旦执行了raise语句,raise语句后的代码将不能被执行。
try:
s=None
if s is None:
print("s 是空对象")
raise NameError
print(len(s))
except TypeError:
print("空对象没有长度")
自定义异常
自定义异常必须继承Exception类,自定义异常按照命名规范以"Error"结尾,使用raise引发,且只能通过手工方式触发
from __future__ import division
class DivisionException(Exception):
def __init__(self,Exception):
Exception.__init__(self,x,y)
self.x=x
self.y=y
if __name__=="__main__":
try:
x=3
y=2
if x%y>0:
print(x/y)
raise DivisionException(x,y)
except DivisionException as div:
print("DivisionException:x/y=%.2f"%(div.x/div.y))
assert语句的使用
assert语句用于检测某个条件表达是否为真,又称断言语句
t=("hello")
assert len(t)>=1
注意:python支持形如"m<=x<=n"的表达式。
Python中的traceback对象可记录异常信息和当前程序的状态。当异常发生时,traceback对象将输出异常信息。异常信息应从下往上阅读。
python的数据库编程
Python提供了连接数据库的专用模块,不同的数据库可以使用相应的专用模块访问数据库。
1、cx_Oracle模块
python的cx_Oracle模块可以访问Oracle数据库。
cx_Oracle模块的下载地址:http://cx-oracle.sourceforge.net/
代码示例:
import cx_Oracle
connection=cx_Oracle.Connection("scott","tiger,","ORCL") #连接oracle数据库
cursor=connection.cursor() #获取cursor对象操作数据库
sql="";
cursor.execute(sql)
for x in cursor.fetvchall():
for value in x:
print(value)
cursor.close()
connection.close()
2、MySQLdb模块
MySQLdb模块是python操作MySQL数据库的。
代码示例
import os,sys
import MySQLdb
#连接数据库
try:
conn=MySQLdb.connect(host="localhost",user="root",passwd="",db="")
cursor=conn.cursor()
sql="insert into address(name,address) values (%s,%s)"
values=(("张三","北京海淀区"),("李四","北京海淀区"),("王五","北京海淀区"))
cursor.executemany(sql,values) #插入多条数据
except Exception as e:
print(e)
sys.exit()
~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~
try:
sql=""
cursor.execute(sql) #查询数据
data=cursor.fetchall()
if data:
for x in data:
print(x[0],x[1])
cursor.close() #关闭游标
conn.close() #关闭数据库
except Exception as e:
print(e)
3、SQLite数据库
#-*-coding:utf-8-*-
import sqlite3
#连接数据库
conn=sqlite3.connect("./address.db")
#创建表
conn.execute("create table if not exists address(id integer primary key autoincrement,name VARCHAR(128),address VARCHAR (128))")
conn.execute("insert into address(name,address) VALUES ('Tom','Beijing road')")
conn.execute("insert into address(name,address) VALUES ('Jerry','Shanghai road')")
#手动提交数据
conn.commit()
#获取游标对象
cur=conn.cursor()
#使用游标查询数据
cur.execute("select * from address")
#获取所有结果
res=cur.fetchall()
print "address:",res
for line in res:
for f in line:
print f
#关闭连接
cur.close()
conn.close()
Python的持久化模块
python的标准库提供了几种持久化模块。这些模块可以模拟数据库的操作,会把数据保存在指定的文件中。例如dbhash、anydbm、shelve等模块。
1、dbhash模块读写数据
DBM是一种文件式数据库,采用哈希结构进行存储。是一种简单的数据库,并不具备管理能力,但是比普通文件更稳定、可靠,而且查询速度快。unix操作系统使用gdbm,而windows可以使用dbhash模块。
window环境下DBM数据库的读写操作
import dbhash
db=dbhash.open('temp','c') #创建并打开数据库
db["Tom"]="Beijing road" #写数据
db["Jerry"]="Shanghai road"
for k,v in db.iteritems(): #遍历db对象
print(k,v)
if db.has_key("Tom"):
del db["Tom"]
print(db)
db.close() #关闭数据库
注意:dbhash模块返回字典的key、value值只支持字符串类型
为了统一不同操作系统对DBM数据库的要求,Python的anydbm模块提供了操作DBM数据库的一般性操作。其用法和dbhash模块类似。
2、shelve模块读写数据
shelve模块是Python的持久化对象模块,用法与anydbm模块的用法相似,但是shelve模块返回字典的value值支持基本的Python类型。
import shelve
addresses=shelve.open('addresses') #创建并打开数据库
addresses["1"]=["Tom","Beijing road","2018-01-03"] #写数据
addresses["2"]=["Jerry","Shanghai road","2008-03-30"]
if addresses.has_key("2"):
del addresses["2"]
print(addresses)
addresses.close() #关闭数据库
注意:shelve模块返回字典的key值只支持字符串类型
文件处理
文件通常用于存储数据或应用程序的参数。Python提供了os、os.path、shutil等模块用于处理文件。其中包括打开文件、读写文件、复制和删除文件等函数。
文件的处理一般分为以下3个步骤:
(1)创建并打开文件,使用file()函数返回一个file对象。
file(name[, mode[, buffering]])
文件打开的模式(mode)
|
参数 |
说明 |
|
r |
以只读的方式打开文件 |
|
r+ |
以读写的方式打开文件 |
|
w |
以写入的方式打开文件。先删除文件原有的内容,再重新写入新的内容。如果文件不存在,则创建1个新的文件。 |
|
w+ |
以读写的方式打开文件。先删除文件原有的内容,再重新写入新的内容。如果文件不存在,则创建1个新的文件。 |
|
a |
以写入的方式打开文件,在文件的末尾追加新的内容。如果文件不存在,则创建1个新的文件. |
|
a+ |
以读写的方式打开文件,在文件的末尾追加新的内容。如果文件不存在,则创建1个新的文件. |
|
b |
以二进制的模式打开文件。可与r、w、a、+结合使用 |
|
U |
支持所有的换行符号。"\r","\n","\r\n"都表示换行 |
注意:对于图片、视频等文件必须使用"b"的模式读写
(2)调用file对象的read()、write()等方法处理文件。
(3)调用close()关闭文件,释放file对象占用的资源。
示例:
#创建文件
context='''helloworld
hellochina
'''
f=open('hello.txt','w')#打开文件
f.write(context)#把字符串写入文件
f.close()#关闭文件
~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~
#按行读取方式:使用readline()读文件
f=open('hello.txt')
while True:
line=f.readline()
if line:
print(line)
else:
break
f.close()
#多行读取方式:使用readlins()读文件
f=open('hello.txt')
lines=f.readlines()
for line in lines:
print(line)
f.close()
#一次性读取方式:read()
f=open('hello.txt')
context=f.read()
print(context)
f.close()
~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~
#使用writelines()写文件
f=open('hello.txt','w+')
li=['helloworld\n','hellochina\n']
f.writelines(li)
f.close()
#使用write()写文件:追加新的内容到文件
f=open('hello.txt','a+')
new_context="goodbye"
f.write(new_context)
f.close()
~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~
文件的删除需要使用os模块和os.path模块。os模块提供了对系统环境、文件、目录等操作的系统级的接口函数。
os模块常用的文件处理函数
|
函数 |
说明 |
|
access(path,mode) |
按照mode指定的权限访问文件 |
|
chmod(path,mode) |
改变文件的访问权限,mode用UNIX系统中的权限代号表示 |
|
open(filename,flag[,mode=0777]) |
按照mode指定的权限打开文件,默认情况下,给所有用户读、写、执行的权限 |
|
remove(path) |
删除path指定的文件 |
|
rename(old,new) |
重命名文件或目录,old表示原文件或目录,new表示新文件或目录 |
|
stat(path) |
返回path指定文件的所有属性 |
|
fstat(path) |
返回打开的文件的所有属性 |
|
lseek(fd,pos,how) |
设置文件的当前位置,返回当前位置的字节数 |
|
startfile(filepath[,operation]) |
启动关联程序打开文件。例如,打开的是1个html文件,将启动浏览器 |
|
tmpfile() |
创建1个临时文件,文件创建在操作系统的临时目录中 |
os.path模块常用的函数
|
函数 |
说明 |
|
abspath(path) |
返回path所在的绝对路径 |
|
dirname(p) |
返回目录的路径 |
|
exists(path) |
判断文件是否存在 |
|
getatime(filename) |
返回文件的最后访问时间 |
|
getctime(filename) |
返回文件的创建时间 |
|
getmtime(filename) |
返回文件的最后修改时间 |
|
getsize(filename) |
返回文件的大小 |
|
isabs(s) |
测试路径是否为绝对路径 |
|
isdir(path) |
判断path指定的是否为目录 |
|
isfile(path) |
判断path指定的是否为文件 |
|
split(p) |
对路径进行分割,并以列表的方式返回 |
|
splitext(p) |
从路径中分割文件的扩展名 |
|
splitdrive(p) |
从路径中分割驱动器的名称 |
|
walk(top,func,arg) |
遍历目录树,与os.walk()的功能相同 |
~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~
#删除文件
importos
if os.path.exists('hello.txt'):
os.remove('hello.txt')
~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~
file类没有提供直接复制文件的方法,但是可以使用read(),write()方法模拟实现文件复制功能。
#使用read()、write()实现拷贝
#创建文件hello.txt
src=open('hello.txt','w')
li=['helloworld\n','hellochina\n']
src.writelines(li)
src.close()
#把hello.txt拷贝到hello2.txt
src=open('hello.txt','r')
dst=open('hello2.txt','w')
dst.write(src.read())
src.close()
dst.close()
shutil模块是另一个文件、目录的管理接口,提供了一些用于复制文件、目录的函数。copyfile()函数可以实现文件的拷贝,copyfile()函数的声明如下:
copyfile(src,dst)
文件的剪切可以使用move()函数模拟,该函数声明如下:
move(src,dst)
#shutil模块实现文件的拷贝、移动
import shutil
shutil.copyfile('hello.txt','hello2.txt')
shutil.move('hello.txt','../')
shutil.move('hello2.txt','hello3.txt')
~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~
os模块的函数rename()可以对文件或目录进行重命名。
#修改文件名
import os
li=os.listdir(".")
print(li)
if "hello.txt" in li:
os.rename('hello.txt','hi.txt')
elif 'hi.txt' in li:
os.rename('hi.txt','hello.txt')
#修改文件后缀(即扩展名)
import os
files=os.listdir('.')
for filename in files:
pos=filename.find('.')
if filename[pos+1:]=='html':
newname=filename[:pos+1]+"htm"
os.rename(filename,newname)
#修改文件后缀(即扩展名)--简化版
import os
files=os.listdir('.')
for filename in files:
li=os.path.splitext(filename)
if li[1]==".html":
newname=li[0]+".htm"
os.rename(filename,newname)
~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~
#文件的查找
import re
f1=open('hello.txt','r')
count=0
for s in f1.readlines():
li=re.findall('hello',s)
if len(li)>0:
count+=li.count("hello")
print("查找到"+str(count)+"个hello")
f1.close()
#文件内容的替换
f1=open('hello.txt','r')
f2=open('hello2.txt','w')
for s in f1.readlines():
f2.write(s.replace("hello",'hi'))
f1.close()
f2.close()
~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~
python提供了模块difflib用于实现对序列、文件的比较。如果要比较2个文件,列出2个文件的异同,可以使用difflib模块的SequenceMatcher类实现。其中get_opcodes()可以返回2个序列的比较结果。调用get_opcodes之前,需要先生成1个SequenceMatcher对象。
#文件比较
import difflib
f1=open('hello.txt','r')
f2=open('hi.txt','r')
src=f1.read()
dst=f2.read()
print(src)
print(dst)
s=difflib.SequenceMatcher(lambda x:x=="",src,dst)
for tag,i1,i2,j1,j2 in s.get_opcodes():
print("%ssrc[%d:%d]=%sdst[%d:%d]=%s"%(tag,i1,i2,src[i1:i2],j1,j2,dst[j1:j2]))
~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~
python标准库ConfigParser模块用于解析配置文件。ConfigParser模块类可读取ini文件的内容
ODBC.ini
[ODBC 32 bit Data Sources]
MS Access Database=Microsoft Access Driver(*.mdb)(32)
Excel Files=Microsoft Excel Driver(*.xls)(32)
dBASE Files=Microsoft dBase Driver(*.dbf)(32)
[MSAccessDatabase]
Driver32=C:\WINDOWS\system32\odbcjt32.dll
[ExcelFiles]
Driver32=C:\WINDOWS\system32\odbcjt32.dll
[dBASEFiles]
Driver32=C:\WINDOWS\system32\odbcjt32.dll
#读取配置文件
import configparser
config=configparser.ConfigParser()
config.read("ODBC.ini")
sections=config.sections()#返回所有配置块的标题
print("配置块:",sections)
o=config.options("ODBC 32 bit Data Sources")#返回所有配置项的标题
print("配置项:",o)
v=config.items("ODBC 32 bit Data Sources")
print("内容:",v)
#根据配置块和配置项返回内容
access=config.get("ODBC 32 bit Data Sources","Ms Access Database")
print(access)
excel=config.get("ODBC 32 bit Data Sources","Excel Files")
print(excel)
dBASE=config.get("ODBC 32 bit Data Sources","dBASE Files")
2、配置文件写入
#写入配置文件
import configparser
config=configparser.ConfigParser()
config.add_section("ODBC Driver Count")#添加新配置块
config.set("ODBC Driver Count","count",2)#添加新的配置项
f=open("ODBC.ini",'a+')
config.write(f)
f.close()
config.read("ODBC.ini")
3、修改配置文件
#修改配置文件
import configparser
config=configparser.ConfigParser()
config.read("ODBC.ini")
config.set("ODBC Driver Count","count",3)#修改配置项
f=open("ODBC.ini","r+")
config.write(f)
f.close()
4、删除配置块和配置项
#删除配置块和配置项
import configparser
config=configparser.ConfigParser()
config.read("ODBC.ini")
config.remove_option("ODBC Driver Count","count")#删除配置项
config.remove_section("ODBC Driver Count")#删除配置块
f=open("ODBC.ini","w+")
config.write(f)
f.close()
目录的基本操作
os模块提供了针对目录进行操作的函数
|
函数 |
说明 |
|
mkdir(path[,mode=0777]) |
创建path指定的1个目录(一次只能创建一个目录) |
|
makedirs(name,mode=511) |
创建多级目录,name表示为 "path1/path2/..."(一次可以创建多个目录) |
|
rmdir(path) |
删除path指定的目录(一次只能删除一个) |
|
removedirs(path) |
删除path指定的多级目录(一次可以删除多个目录) |
|
listdir(path) |
返回path指定目录下所有的文件名 |
|
getcwd() |
返回当前的工作目录 |
|
chdir(path) |
将当前目录改变为path指定的目录 |
|
walk(top,topdown=True,onerror=None |
遍历目录树 |
import os
os.mkdir("hello")
os.rmdir("hello")
os.makedirs("hello/world")
os.removedirs("hello/world")
目录的遍历有3种实现方法--递归函数、os.path.walk()、os.walk()
#1、递归遍历目录
import os
def visitDir(path):
li=os.listdir(path)
for p in li:
pathname=os.path.join(path,p)
if not os.path.isfile(pathname):
visitDir(pathname)
else:
print(pathname)
if__name__=="__main__":
path=r"/Users/liudebin/资料"
visitDir(path)
#2、os.path.walk()
import os,os.path
def visitDir(arg,dirname,names):
for filepath in names:
print(os.path.join(dirname,filepath))
if__name__=="__main__":
path=r"/Users/liudebin"
os.path.walk(path,visitDir,())
#3、os.walk
def visitDir(path):
for root,dirs,files in os.walk(path):
for filepath in files:
print(os.path.join(root,filepath))
if__name__=="__main__":
path=r"/Users/liudebin"
visitDir(path)
注意:os.path.walk()与os.walk()产生的文件名列表并不相同:
os.path.walk()产生目录树下的目录路径和文件路径,而os.walk()只产生文件路径
文件和流
python隐藏了流的机制,在python的模块中找不到类似Stream类,python把文件的处理和流关联在一起,流对象实现了File类的所有方法。sys模块提供了3种基本的流对象---stdin、stdout、stderr。流对象可以使用File类的属性和方法,流对象的处理和文件的处理方式相同。
1、stdin
importsys
sys.stdin=open('ODBC.ini','r')
for line in sys.stdin.readlines():
print(line)
2、stdout
importsys
sys.stdout=open(r'ODBC.ini','a')
print("goodbye")
sys.stdout.close()
3、stderr
import sys,time
sys.stderr=open('record.log','a')
f=open(r"./hello.txt","r")
t=time.strftime("%Y-%m-%d%X",time.localtime())
context=f.read()
if context:
sys.stderr.write(t+""+context)
else:
raise Exception(t+"异常信息")
python模拟Java输入、输出流
#文件输入流
def fileInputStream(filename):
try:
f=open(filename)
for line in f:
for byte in line:
yield byte
except StopIteration:
f.close()
return
#文件输出流
def fileOutputStream(inputStream,filename):
try:
f=open(filename,'w')
while True:
byte=inputStream.next()
f.write(byte)
except StopIteration:
f.close()
return
if__name__=="__main__":
fileOutputStream(fileInputStream('hello.txt'),'hello2.txt')
示例:
#文件属性浏览
def showFileProperties(path):
"""显示文件的属性,包括路径、大小、创建日期,最后修改时间,最后访问时间"""
import time,os
for root,dirs,files in os.walk(path,True):
print("位置:"+root)
for filename in files:
stats=os.stat(os.path.join(root,filename))
info="文件名:"+filename+""
info+="大小:"+("%dM"%(stats[-4]/1024/1024))+""
t=time.strftime("%Y-%m-%d%X",time.localtime(stats[-1]))
info+="创建时间:"+t+""
t=time.strftime("%Y-%m-%d%X",time.localtime(stats[-2]))
info+="最后修改时间:"+t+""
t=time.strftime("%Y-%m-%d%X",time.localtime(stats[-3]))
info+="最后访问时间:"+t+""
print(info)
if __name__=="__main__":
path=r"/Users/liudebin/Downloads/第一二期/第二期"
showFileProperties(path)
注意:os.stat()的参数必须是路径
~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~
URL的解析
Python中用来对URL字符串进行解析的模块是urlparse。该模块主要的方法有urlparse、urljoin、urlsplit和urlunsplit等
在Python语言中,urlparse对于URL的定义采用的六元组,如下所示:
scheme://netloc/path;parameters?query#fragment
urlparse方法返回对象的属性
可以使用PyChecker和PyLine检查源代码。
使用Distutils可以让开发者轻松地用Python编写安装脚本。
日志记录可以使用标准库中的logging模块,基本用法很简单:
import logging
logging.basicConfig(level=logging.INFO,filename='mylog.log')
logging.info("Starting program")
logging.info("Trying to divide 1 by 0")
~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~
测试
在Python中代码测试包含两种类型:unittest和doctest
unittest模块:用来写PyUnit的测试代码。支持对软件代码的自动化测试。
doctest模块:可以直接在代码的注释中写测试用例。此模块将测试用例内置在了函数的文档字符串,从而达到了文档和测试代码的统一。
TDD(测试驱动开发):基本思想是测试先行,在开发具体的功能代码之前,需要先编写此功能的测试代码。只有通过了测试的代码,才能够加入到代码仓库中。
#encoding=utf-8
importunittest
importstring
class StringReplaceTestCase1(unittest.TestCase):
"""测试空字符串替换"""
def runTest(self):
src="HELLO"
exp="HELLO"
result=string.replace(src,"","")
self.assertEqual(exp,result)
srtc=StringReplaceTestCase1()
srtc.runTest()
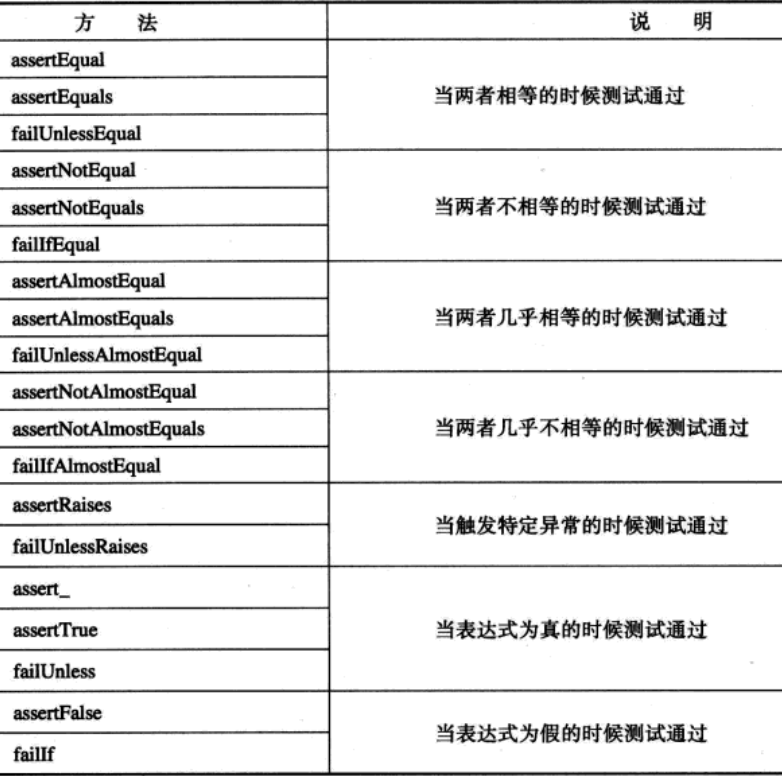
在python语言中,可以用内置的assert语句来实现测试用例运行时候的断言。
unittest模块中的测试方法