爬虫大家或多或少的都应该接触过的,爬虫有风险,抓数需谨慎。
爬虫有的是抓请求,有的是抓网页再解析
本着研究学习的目的,记录一下在 .NET Core 下抓取数据的实际案例。爬虫代码一般具有时效性,当我们的目标发生改版升级,规则转换后我们写的爬虫代码就会失效,需要重新应对。抓取数据的主要思路就是去分析目标网站的页面逻辑,利用xpath、正则表达式等知识去解析网页拿到我们想要的数据。
本篇主要简单介绍三个组件的使用,HtmlAgilityPack、AngleSharp、PuppeteerSharp,前两个可以处理传统的页面,无法抓取单页应用,如果需要抓取单页应用可以使用PuppeteerSharp。
新建一个控制台项目,抓取几个站点的数据来试试,先做准备工作,添加一个IHotNews的接口。
using System.Collections.Generic; using System.Threading.Tasks; namespace SpiderDemo { public interface IHotNews { Task<IList<HotNews>> GetHotNewsAsync(); } }
HotNews模型,包含标题和链接
namespace SpiderDemo { public class HotNews { public string Title { get; set; } public string Url { get; set; } } }
最终我们通过依赖注入的方式,将抓取到的数据展示到控制台中。
HtmlAgilityPack:
https://html-agility-pack.net/
https://github.com/zzzprojects/html-agility-pack
在项目中安装HtmlAgilityPack组件
Install-Package HtmlAgilityPack
这里以博客园为抓取目标,我们抓取首页的文章标题和链接。
using HtmlAgilityPack; using System.Collections.Generic; using System.Linq; using System.Threading.Tasks; namespace SpiderDemo { public class HotNewsHtmlAgilityPack : IHotNews { public async Task<IList<HotNews>> GetHotNewsAsync() { var list = new List<HotNews>(); var web = new HtmlWeb(); var htmlDocument = await web.LoadFromWebAsync("https://www.cnblogs.com/"); var node = htmlDocument.DocumentNode.SelectNodes("//*[@id='post_list']/article/section/div/a").ToList(); foreach (var item in node) { list.Add(new HotNews { Title = item.InnerText, Url = item.GetAttributeValue("href", "") }); } return list; } } }
添加HotNewsHtmlAgilityPack.cs实现IHotNews接口,访问博客园网址,拿到HTML数据后,使用xpath语法解析HTML,这里主要是拿到a标签即可。
通过查看网页分析可以得到这个xpath://*[@id='post_list']/article/section/div/a。
然后在Program.cs中注入IHotNews,循环遍历看看效果。
using Microsoft.Extensions.DependencyInjection; using System; using System.Linq; using System.Threading.Tasks; namespace SpiderDemo { class Program { static async Task Main(string[] args) { IServiceCollection service = new ServiceCollection(); service.AddSingleton<IHotNews, HotNewsHtmlAgilityPack>(); var provider = service.BuildServiceProvider().GetRequiredService<IHotNews>(); var list = await provider.GetHotNewsAsync(); if (list.Any()) { Console.WriteLine($"一共{list.Count}条数据"); foreach (var item in list) { Console.WriteLine($"{item.Title} {item.Url}"); } } else { Console.WriteLine("无数据"); } } } }
Anglesharp
https://anglesharp.github.io/
https://github.com/AngleSharp/AngleSharp
在项目中安装AngleSharp组件
Install-Package AngleSharp
同样的,新建一个HotNewsAngleSharp.cs也实现IHotNews接口,这次使用AngleSharp抓取。
using AngleSharp; using System.Collections.Generic; using System.Threading.Tasks; namespace SpiderDemo { public class HotNewsAngleSharp : IHotNews { public async Task<IList<HotNews>> GetHotNewsAsync() { var list = new List<HotNews>(); var config = Configuration.Default.WithDefaultLoader(); var address = "https://www.cnblogs.com"; var context = BrowsingContext.New(config); var document = await context.OpenAsync(address); var cellSelector = "article.post-item"; var cells = document.QuerySelectorAll(cellSelector); foreach (var item in cells) { var a = item.QuerySelector("section>div>a"); list.Add(new HotNews { Title = a.TextContent, Url = a.GetAttribute("href") }); } return list; } } }
AngleSharp解析数据和HtmlAgilityPack的方式有所不同,AngleSharp可以利用css规则去获取数据,用起来也是挺方便的
在Program.cs中注入IHotNews,循环遍历看看效果。
using Microsoft.Extensions.DependencyInjection; using System; using System.Linq; using System.Threading.Tasks; namespace SpiderDemo { class Program { static async Task Main(string[] args) { IServiceCollection service = new ServiceCollection(); service.AddSingleton<IHotNews, HotNewsAngleSharp>(); var provider = service.BuildServiceProvider().GetRequiredService<IHotNews>(); var list = await provider.GetHotNewsAsync(); if (list.Any()) { Console.WriteLine($"一共{list.Count}条数据"); foreach (var item in list) { Console.WriteLine($"{item.Title} {item.Url}"); } } else { Console.WriteLine("无数据"); } } } }
PuppeteerSharp
https://www.puppeteersharp.com/
https://github.com/hardkoded/puppeteer-sharp
PuppeteerSharp是基于Puppeteer的,Puppeteer 是一个Google 开源的NodeJS 库,它提供了一个高级API 来通过DevTools协议控制Chromium 浏览器。Puppeteer 默认以无头(Headless) 模式运行,但是可以通过修改配置运行“有头”模式。
PuppeteerSharp可以干很多事情,不光可以用来抓取单页应用,还可以用来生成页面PDF或者图片,可以做自动化测试等。
在项目中安装PuppeteerSharp组件
Install-Package PuppeteerSharp
使用PuppeteerSharp第一次会帮我们在项目根目录中下载浏览器执行程序,这个取决于当前网速的快慢,建议手动下载后放在指定位置即可。
using PuppeteerSharp; using System.Threading.Tasks; namespace SpiderDemo { class Program { static async Task Main(string[] args) { // 下载浏览器执行程序 await new BrowserFetcher().DownloadAsync(BrowserFetcher.DefaultRevision); // 创建一个浏览器执行实例 using var browser = await Puppeteer.LaunchAsync(new LaunchOptions { Headless = true, Args = new string[] { "--no-sandbox" } }); // 打开一个页面 using var page = await browser.NewPageAsync(); // 设置页面大小 await page.SetViewportAsync(new ViewPortOptions { Width = 1920, Height = 1080 }); } } }
上面这段代码是初始化PuppeteerSharp必要的代码,可以根据实际开发需要进行修改,下面以"https://juejin.im"为例,演示几个常用操作。
获取单页面的HTML
var url = "https://juejin.im"; await page.GoToAsync(url, WaitUntilNavigation.Networkidle0); var content = await page.GetContentAsync(); Console.WriteLine(content);
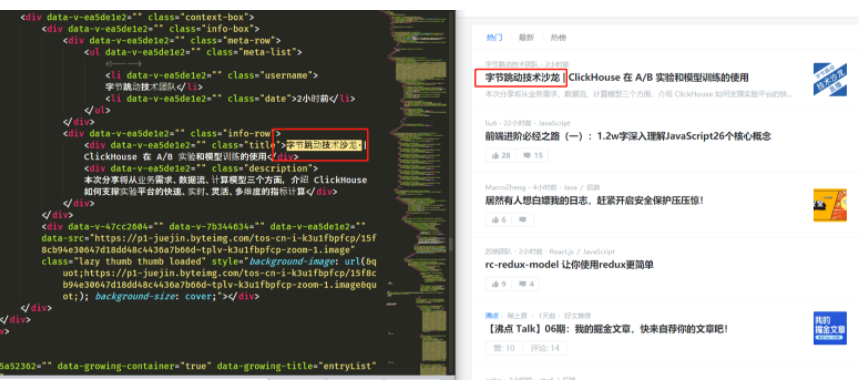
可以看到页面上的HTML全部被获取到了,这时候就可以利用规则解析HTML,拿到我们想要的数据了。
保存为图片
var url = "https://juejin.im/"; await page.GoToAsync(url, WaitUntilNavigation.Networkidle0); await page.ScreenshotAsync("juejin.png");
保存为PDF
var url = "https://juejin.im/"; await page.GoToAsync(url, WaitUntilNavigation.Networkidle0); await page.PdfAsync("juejin.pdf");
PuppeteerSharp的功能还有很多,比如页面注入HTML、执行JS代码等,使用的时候可以参考官网示例。
最后使用HtmlAgilityPack获取博客园的标题内容
List<BlogInfo> blog = new List<BlogInfo>();
HtmlWeb web = new HtmlWeb();
HtmlNodeCollection node;
for (int i = 0; i < 10; i++)
{
node = web.Load($"https://www.cnblogs.com/#p{i}").DocumentNode.SelectNodes("//a[@class='post-item-title']");
foreach (var item in node)
{
blog.Add(new BlogInfo
{
Title = item.InnerText,
Content = web.Load(item.GetAttributeValue("href", "")).DocumentNode.SelectSingleNode("//div[@id='cnblogs_post_body']").InnerHtml
});
}
}
xpath参考https://www.cnblogs.com/cplemom/p/13388613.html
推荐其他几个爬虫类库
https://www.cnblogs.com/cang12138/p/7464226.html
https://www.cnblogs.com/cang12138/p/7486003.html
https://www.cnblogs.com/EminemJK/p/8920364.html
https://github.com/AngleSharp/AngleSharp
https://github.com/TsingJyujing/DataSpider
https://github.com/sjdirect/abot
https://github.com/zzzprojects/html-agility-pack
爬虫29问
1、爬虫很简单吗?
如果只是抓取几个普通的网页,爬虫确实很简单。在网络上,我们经常可以看到,30分钟入门python爬虫这样的教程。如果目标网站有反爬,或是需要抓取海量数据,那这就不是一件简单的事了。本书就从爬虫常见问题,爬虫技巧,以及反爬虫,海量爬取等方面,来讲一下如何应对各种各样的爬虫状况。
2、POST和GET有什么区别?
从本质上,没有什么区别,都是http协议中的Method方法。只是POST在上传数据时,使用了Body。同样的,http协议中可以使用PUT,HEAD等方法,也可以自造协议如ABCD,只要服务器支持即可。
3、静态网页和动态网页抓取有什么区别?
很久以前,大家会将html后缀的网页叫静态网页,asp,php,jsp这类后缀的网页叫动态网页。但这种分法其实不科学,因为伪静态技术是可以让网页后缀任意显示的。我们可以查看服务器端返回的header信息,查看服务器软件是Apache还是IIS,由这个信息判断,当然,这个信息其实很多情况下也是可以更改的。
从爬虫角度,没有所谓的动态和静态。网页在服务器端生成,通过网络传送到客户端,如果是在浏览器,浏览器渲染页面并再加载网页相关的css,js及图片等资源。现在,人们更多的将通过js加载数据的网页称为动态网页。
4、请求抓取一个网页,需要注意哪些事情?
一般需要注意User-Agent以及Cookie,User-Agent代表浏览器类型,很多网站针对不同的浏览器使用不同的显示输出方式,Cookie携带了一些登录信息,如果登录成功一个网站,在下次请求中不使用Cookie,就会提示你没有登录了。在请求时,还需要注意请求的编码和返回代码的编码,如果选错编码,看到的可能就是乱码。
5、如何学习http协议
极力推荐大家使用fiddler软件来分析http请求。这个工具自带很多功能,方便查看请求的所有细节,还可以伪造请求,进行调试,统计等功能。
6、防盗链是怎么回事
在服务器上可以设置或是检测请求Header看的Referer参数,如果为空,或是非本站域名,则不显示数据。最常见的是图片显示禁止盗链或是不显示。只需要在抓取时设置Referer即可。
7、网站数据没列表的怎么抓取?
如果网站是通过搜索获取的,则可以使用各种各样的搜索词来搜索,比如常见的文字,字母以及数字的组合,作为搜索条件搜索。
如果返回结果的内容是有数字id的,可以通过穷举的方式进行爬取。
8、Silverlight类型的网站如何抓取:
可以打开Silverlight网站的页面,查看源代码,寻找xap的文字,看到类似<param name="Source" value="xxx/abc.xap" />的文字,然后下载xap文件,解压后就可以看到很多dll文件,使用ilspy反编译即可看到网站的调用过程。
9、类似12306类型的验证码怎么办?
穷举所有图片样本,只要量够大,再结合人工标识,就可处理。
10、被封IP怎么办?
被封IP后可以做以下调整:
1)减少请求频率
2)更换User-Agent,可以试一下用百度等搜索引擎的
3)更换IP,可以adsl拨号,也可以代理服务
11、爬取海量的数据需注意什么?
比如一天抓取1000万,就要分解到每秒,每机器,带宽等方面,要使用分布式集群来抓取,可以使用redis这样的列队存储任务。
12、返回的数据是加密的,怎么解密?
如果是网页源代码中加密,而页面上正常显示,这就是数据通过JavaScript渲染了,这时,可以通过浏览器的开发者工具,调试代码,查看数据处理过程。如果不想深入研究,直接上PhantomJS或其它浏览器,操作网页元素获取数据。13、爬取中出现有验证码怎么办?
普通的验证码,比如纯字母或数字,不相互粘连,使用字库或二值化,很容易处理。现在的验证码都是比较高级的,比如复杂的字符,拖动,点击等,需要接入打码平台进行人工打码。
14、手机app数据要如何抓取
可以在手机上设置http代理,看看有无数据经过http协议传送。如果没有,那抓取难度会提高不少,有人通过反编译或是群控点击来抓取,但成本较高。很多小型的app,基本没有安全意识,很多是直接调用的api,得到的是非常干净的json数据。
15、如何上传文件至网站?
上传文件需要使用POST方法并设置Content-Type为multipart/form-data,发送的格式如下:
POST http://www.example.com HTTP/1.1
Content-Type:multipart/form-data; boundary=----WebKitFormBoundaryA
------WebKitFormBoundaryA
Content-Disposition: form-data; name="text"
title
------WebKitFormBoundaryA
Content-Disposition: form-data; name="file"; filename="chrome.png"
Content-Type: image/png
二进制文件内容 ...
------WebKitFormBoundaryA--
以上部分为发送格式,其中WebKitFormBoundaryA是可以使用任意内容的,只要按这种格式即可。常见的Content-Type还有application/x-www-form-urlencoded ,application/json,text/xml。
16、翻页限制怎么处理?
多级分类数据很多是有翻页限制,分类只显示前多少页。对于此情况,可以使用这类网站的筛选功能,比如按时间先后,大小,排序来扩大页面内容。如果有子分类,就不断的获取子分类。如果有多个选项,可以使用排列组合的方式,尽可能多的获取。
17、海量网址如何重复排重?
数据量不大的情况下,可以对网址进行md5一下,然后使用hash进行对比。如果是海量网址排重,可以使用布隆排重算法BloomFilter。
18、如何提高爬取速度
1)使用gzip/deflate压缩,一般能压缩到原大小的20%左右。一般服务器不会为你发送压缩数据,需要传送Accept-encoding的header。
2)使用链接池,C#请求时需要将keep-alive设置为true。
3)设置超时,要对一直无响应的请求果断关闭。
19、要抓取包含特定关键词的网页
使用站内搜索,搜索引擎site,全部下载
20、CSS/HTML混淆干扰限制的数据获取
常见的此类反爬方式有
1)使用图片替换部分文字
2)使用自定义字体
3)伪元素隐藏
4)元素position位置偏
其中,第一种情况,可以找图片对应的文字,找到所有后进行替换。第二种可以找到ttf字体文件地址后下载再找其中编码和文字的对应关系并替换。第三种,找class对应的文本内容进行替换。第四种就涉及到计算了,如果嫌麻烦,也可以截图识别。
21、数据抓取过程中发现电信劫持,导致数据错误怎么办?
电话投诉电信运营商,可以打电话或是工信部投诉。
有时电脑中病毒也会有这类劫持,这就属于黑产方面的了。
22、关于eval(function(p,a,c,k,e,d)加密的问题
这是一个很经典的数据加密方式,网上已经有在线加密解密的方法。在本地运行时,需要使用JS引擎执行js获得结果。
23、PKI证书的验证的网站如何处理?
PKI证书一般是在登录时,会去特定地址请求并上传证书进行验证,验证过后生成带参网址返回网站并生成cookie从而完成身份验证。也有通过插件实现验证的,比如吉大正元。
24、HtmlAgilityPack解析网页需注意什么
在很久以前版本中,HtmlAgilityPack存在溢出漏洞,即节点分析会陷入死循环。新版本解决了这个问题,请用最新版本。在使用HtmlAgilityPack 解析网页时,需要注意可能页面错误导致无法解析。可以使用替换等方法先对源代码进行处理,再进行解析。
25、除了fiddler有哪些数据包抓取工具呢?
1)Microsoft Network Monitor
2)Wireshark
3)Anyproxy
26、抓取的数据不全怎么办?
某些网站,会对外只显示部分数据,或是只针对部分用户显示全部数据,那这种情况下,就是考验观察力的能力了。比如很早以前同城网站的联系方式,只显示前7位号码,但是呢,在另外一个地方,显示了后四位,所以,只要都抓取一下加一块儿就可以了。还有部分网站,使用json调用api,一看就知道程序员用的是select * ,返回的数据中包含了所有有关和没关的数据,相当于明显的漏洞。有时也可以使用不全的数据,再去站内搜索,说不定也会有新的发现。
27、网站使用CDN反爬虫如何应对?
网站使用cdn技术可以提高访问速度和安全性,并能提供更高的反爬虫能力。不过部分网站会暴露真实服务器地址,同时没判断cdn来源,导致伪造的cdn服务器可以不断的抓取数据。同时大多数cdn服务器反爬虫没有做联动,导致cdn服务器越多,反而相当于提供了更多的代理服务器给爬虫使用。
28、使用Xpath获取网页元素时需要注意什么?
经过浏览器渲染,然后使用xpath提取Dom元素,再取值,是可以忽略渲染过程,并能实时获取最新数据的方法。在设置xpath提取规则时,善于使用绝对相对,contains,or,and等符号,可以尽快定位元素。如果最终元素符号是不定的,可以使用父级定位。尽可能使用@id这种唯一性标识。
29、遇到网站投毒怎么办?
遇到目标网站检测到了爬虫,给错数据的时候,因为无法直接判断出数据的准确性,所以只能是通过多次,或是多个形式的爬取,对最终的结果进行对比,如果多次都正确,则可以认为是正确的数据。类似的情况都可以使用这样的思路,比如使用下载软件下载资源,经常会有下载不了的情况,如果同时对一个资源搜索很多下载链接并同时进行下载,就可以很快筛选出可以下载的。