目录
· 概况
· Hadoop
· 云计算
· 大数据
· 数据挖掘
· 手工搭建集群
· 引言
· 配置机器名
· 调整时间
· 创建用户
· 安装JDK
· 配置文件
· 启动与测试
· 原理
· Hadoop架构
· 性能调优
· 硬件选型
· 操作系统调优
· JVM调优
概况
Hadoop
1. ASF(Apache软件基金会)给出定义:Hadoop软件库是一个框架,允许在集群中使用简单的编程模型对大规模数据集进行分布式计算。
2. Hadoop生态圈

a) Hadoop Common:Hadoop体系最底层的模块(基础模块),为Hadoop各子项目提供系统配置工具Configuration、远程过程调用RPC、序列化机制和日志操作等。
b) HDFS:Hadoop Distributed File System是具有高度容错性的文件系统,适合部署在廉价机器上。HDFS提供高吞吐量的数据访问,非常适合大规模数据集上的应用。
c) YARN:Yet Another Resource Negotiator是统一资源管理和调度平台,解决了上一代Hadoop资源利用率低和不兼容异构计算框架等多种问题,提供资源隔离方案和双调度器的实现。
d) MapReduce:一种编程模型,利用函数式编程思想,将数据集处理过程分为Map和Reduce两个阶段,非常适合进行分布式计算。支持Java、C++、Python、PHP等多种语言。
e) Spark:加州伯克利大学AMP实验室开发的新一代计算框架,对迭代计算很有优势,比MapReduce性能提升明显。
f) HBase:来源于Google Bigtable论文,是一个分布式、面向列族的开源数据库。擅长大规模数据的随机、实时读写访问。
g) ZooKeeper:基于Fast Paxos算法,解决了分布式系统中的一致性问题,提供配置维护、命名服务、分布式同步、组服务等。
h) Hive:由Facebook开发,基于Hadoop的数据仓库工具,将结构化数据文件映射成一张表,提供SQL查询功能,并将SQL转换为MapReduce运行。学习成本低,大大降低了Hadoop的使用门槛。
i) Pig:与Hive类似,不提供SQL接口,而提供高层的、面向领域的抽象语言Pig Latin,并将Pig Latin转为MapReduce运行。与SQL相比,Pig Latin更灵活,但学习成本稍高。
j) Impala:由Cloudera开发,对存储在HDFS、HBase的海量数据提供交互式查询SQL接口。Impala未基于MapReduce,定位是OLAP,是Google新三架马车之一Dremel的开源实现,因此性能大幅领先于Hive。
k) Mahout:机器学习和数据挖掘库,利用MapReduce编程模型实现了k-means、Native Bayes、Collaborative Filtering等经典机器学习算法,并具有良好的扩展性。
l) Flume:由Cloudera提供的高可用、高可靠、分布式的海量日志采集、聚合和传输系统,支持在日志系统中定制各类数据发送方,用于收集数据;提供数据简单处理,并写到各种数据接受方(可定制)。
m) Sqoop:SQL to Hadoop的缩写,作用于在结构化的数据存储(关系数据库)与HDFS、Hive之间进行数据双向交换。导入、导出都由MapReduce计算框架实现并行化,非常高效。
n) Kafka:高吞吐量、高可用、分布式发布订阅消息系统,在大数据系统被广泛使用。如果把大数据平台比作一台计算机,那么Kafka消息中间件类似于前端总线,它连接平台各组件。
3. Hadoop三大厂商及其发行版
a) Cloudera:CDH,生产环境装机量最大版本。
b) Houtonworks:HDP。
c) MapR:MapR
云计算
1. NIST(美国国家标准技术研究院)给出定义:云计算是一种可以通过网络方便地接入共享资源池,按需获取计算资源(包括网络、服务器、存储、应用、服务等)的服务模型。共享资源池中的资源可以通过较少的管理代价和简单业务交互过程而快速部署和发布。
2. 云计算特点:
a) 按需提供服务:以服务的形式为用户提供应用程序、数据存储、基础设施等资源,并可根据用户需求自动分配资源,而不需要系统管理员干预。
b) 宽带网络访问:用户可以利用各种终端设备(如PC机、笔记本电脑、智能手机等)随时随地通过互联网访问云计算资源。
c) 资源池化:资源以共享资源池的方式统一管理。利用虚拟化技术,将资源分享给不同用户,资源的放置、管理与分配策略对用户透明。
d) 高可伸缩性:服务的规模可快速伸缩,以自动适应业务负载的动态变化。用户使用的资源同业务的需求相一致,避免因为服务器性能过载或冗余而导致的服务质量下降或资源浪费。
e) 可量化的服务:云计算中心都可以通过监控软件监控用户的使用情况,并根据资源的使用情况对外服务计费。
f) 大规模:承载云计算的集群一般都具有超大规模。
g) 服务极其廉价:“云”的特殊容错机制使得可以采用廉价节点构建;“云”的自动化管理使数据中心管理成本大幅降低;“云”的公用性和通用性使资源利用率大幅提升;“云”设施可建在电力丰富的地区,从而大幅降低能用成本。
3. 云计算服务类型
a) Iaas:Infrastructure as a Service,云计算架构最底层,利用虚拟化技术将硬件设备等基础资源封装成服务供用户使用,用户相当于在使用裸机。典型虚拟化产品VMware vShpere、微软Hyper-V、开源KVM、开源Xen、Amazon EC2/S3利用的是Xen技术;Docker。
b) PaaS:Platform as a Service,对资源更进一步抽象,提供用户应用程序的应用环境。例如Google App Engine。
c) SaaS:Software as a Service,将某些特定应用软件功能封装成服务。例如Salesforce CRM服务。
4. Hadoop与云计算:Hadoop拥有云计算PaaS层的所有特点。
a) HDFS抽象了所有硬件资源,使其对用户透明,并提供数据冗余、自动灾备、动态增加减少节点功能。
b) Hadoop提供Java、C++、Python等运行环境,参照MapReduce编程模型即可实现应用开发,用户无需考虑各节点之间配合。
大数据
1. 麦肯锡给出定义:大数据指所涉及的数据集规模已经超过了传统数据库软件获取、存储、管理和分析的能力。
2. IBM给出特点(3V)
a) 数据量(Volume):从TB级别转向PB级别,并不可避免转向ZB级别。随着可供企业使用的数据量不断增长,可处理、理解和分析的数据比例却不断下降。
b) 多样性(Variety):结构化、半结构化和非结构化数据。
c) 速度(Velocity):数据增长速率。
3. 大数据结构类型
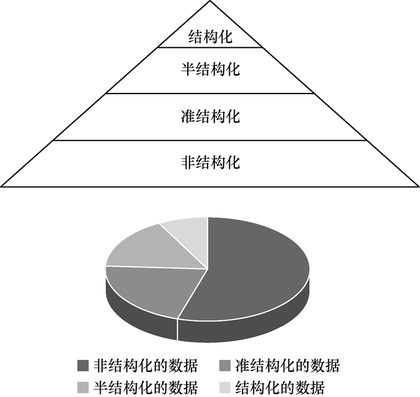
a) 结构化数据:包括预定义的数据类型、格式和结构的数据,例如关系数据库表数据。
b) 半结构化数据:具有可识别的模式并可以解析的文本数据文件,例如XML数据。
c) 非结构化数据:没有固定结构的数据,通常保存为不同的类型文件,例如文本文档、PDF、图像、视频。
4. 大数据变革:大数据变革和人类经历过的若干次变革最大不同在于发生得悄无声息,但确确实实改变了我们的生活;各行各业的先知先觉者已经从与数据共舞中尝到甜头,而越来越多的后来者和新进者都希望借助云计算和大数据这波浪潮去撬动原有市场格局或开辟新的商业领域。
数据挖掘
1. 简短定义:数据→知识。
2. 知识发现的过程由以下步骤迭代组成:
a) 数据清理:消除噪声。
b) 数据集成:多种数据源可以组合在一起。
c) 数据选择:从数据库中提取与分析任务相关的数据。
d) 数据变换:通过汇总或聚集操作,把数据变换和统一成适合挖掘的形式。
e) 数据挖掘:基本步骤,使用智能方法提取数据模式。
f) 模式评估:根据某种兴趣度度量,识别代表知识的真正有趣的模式。
g) 知识表示:使用可视化和知识表示技术,向用户提供挖掘的知识)。
3. 数据仓库定义:面向主题的、集成的、时变的、非易失的数据集合,支持管理者的决策过程。
手工搭建集群
引言
环境:
|
Role |
Host name |
|
Master |
centos1 |
|
Slave |
centos2 |
|
centos3 |
配置机器名
1. [Master、Slave]查看各机器的机器名。
hostname
2. [Master、Slave]将所有机器名配置到各机器中。
vi /etc/hosts
192.168.27.2 centos1 192.168.27.3 centos2 192.168.27.4 centos3
调整时间
3. [Master、Slave]保证各机器间时间差不超过2分钟。
date # 查看 date -s "2017-03-02 09:07:00" # 修改 ntpdate time.windows.com # 若连通互联网,可同步微软 clock -w # 写入BIOS
创建用户
4. [Master、Slave]创建hadoop用户。
# CentOS/RHEL
groupadd hadoop useradd -g hadoop -G root -d /home/hadoop hadoop passwd hadoop
# Ubuntu
sudo adduser hadoop
sudo usermod -aG adm,sudo,dip,plugdev,lpadmin hadoop
sudo groups hadoop
5. [Master、Slave]创建软件安装目录和数据目录。
mkdir /opt/app /opt/data chown hadoop:hadoop /opt/app /opt/data
6. [Master、Slave]登录hadoop用户,后续步骤均在该用户下执行。
su - hadoop # 注意有减号。有减号表示登录后使用hadoop用户的环境变量,否则不使用。
7. [Master]生成SSH公钥、私钥,复制公钥到各Slave。
ssh-keygen -t rsa # 生成 ssh-copy-id hadoop@centos1 # 复制方式1 ssh-copy-id hadoop@centos2 ssh-copy-id hadoop@centos3 cp id_rsa.pub authorized_keys # 复制方式2
scp authorized_keys hadoop@centos2:/home/hadoop/.ssh
scp authorized_keys hadoop@centos3:/home/hadoop/.ssh
chmod 700 /home/hadoop/.ssh # 各节点的.ssh目录权限必须是700,否则无法登录
安装JDK
8. [Master、Slave]安装JDK到/opt/app目录下。
tar zxvf jdk-8u121-linux-i586.tar.gz -C /opt/app
9. [Master、Slave]配置环境变量。
vi /etc/profile
export JAVA_HOME=/opt/app/jdk1.8.0_121 export CLASSPATH=. export PATH=$JAVA_HOME/bin:$PATH
source /etc/profile # 生效 env | grep JAVA_HOME # 验证
配置文件
10. [Master]注意:Hadoop临时目录应指向一个足够空间的磁盘,并且需要目录使用权限(各机器)。
tar zxvf hadoop-2.6.5.tar.gz -C /opt/app cd /opt/app/hadoop-2.6.5/etc/hadoop vi hadoop-env.sh
export JAVA_HOME=/opt/app/jdk1.8.0_121 export HADOOP_HOME=/opt/app/hadoop-2.6.5
vi core-site.xml
<property> <name>hadoop.tmp.dir</name> <value>/opt/data/hadoop.tmp.dir</value> </property> <property> <name>fs.default.name</name> <value>hdfs://centos1:9000</value> </property>
vi hdfs-site.xml
<property> <name>dfs.replication</name> <value>2</value> </property> <property> <name>dfs.name.dir</name> <value>/opt/data/dfs.name.dir</value> </property> <property> <name>dfs.data.dir</name> <value>/opt/data/dfs.data.dir</value> </property> <property> <name>dfs.permissions</name> <value>false</value> </property>
cp mapred-site.xml.template mapred-site.xml vi mapred-site.xml
<property> <name>mapreduce.framework.name</name> <value>yarn</value> </property>
vi yarn-site.xml
<property> <name>yarn.nodemanager.aux-services</name> <value>mapreduce_shuffle</value> </property> <property> <name>yarn.nodemanager.aux-services.mapreduce.shuffle.class</name> <value>org.apache.hadoop.mapred.ShuffleHandler</value> </property> <property> <name>yarn.resourcemanager.address</name> <value>centos1:8032</value> </property> <property> <name>yarn.resourcemanager.scheduler.address</name> <value>centos1:8030</value> </property> <property> <name>yarn.resourcemanager.resource-tracker.address</name> <value>centos1:8031</value> </property> <property> <name>yarn.resourcemanager.admin.address</name> <value>centos1:8033</value> </property> <property> <name>yarn.resourcemanager.webapp.address</name> <value>centos1:8088</value> </property> <!-- <property> <name>yarn.nodemanager.resource.memory-mb</name> <value>512</value> </property> <property> <name>yarn.nodemanager.resource.cpu-vcores</name> <value>2</value> </property> --> <property> <name>yarn.nodemanager.pmem-check-enabled</name> <value>false</value> </property> <property> <name>yarn.nodemanager.vmem-check-enabled</name> <value>false</value> </property>
vi slaves
centos2
centos3
11. [Master]从Master复制Hadoop目录到各Slave。
scp -r /opt/app/hadoop-2.6.5 hadoop@centos2:/opt/app scp -r /opt/app/hadoop-2.6.5 hadoop@centos3:/opt/app
启动与测试
12. [Master]配置Hadoop环境变量。
vi /home/hadoop/.bash_profile
export HADOOP_HOME=/opt/app/hadoop-2.6.5 export PATH=$PATH:$HADOOP_HOME/bin
source /home/hadoop/.bash_profile env | grep HADOOP_HOME
13. [Master]格式化HDFS,启动Hadoop。
hadoop namenode -format sbin/start-dfs.sh sbin/start-yarn.sh
14. [Master、Slave]检查守护进程。
jps
# Master守护进程
NameNode
SecondaryNameNode
ResourceManager
# Slave守护进程
DataNode
NodeManager
15. [Master]测试。
hadoop jar /opt/app/hadoop-2.6.5/share/hadoop/mapreduce/hadoop-mapreduce-examples-2.6.5.jar pi 2 100
16. 监控页面。
|
http://centos1:8088 |
YARN监控 |
|
http://centos1:50070 |
HDFS监控 |
Cloudera Manager
1. 主要功能:集群自动化安装部署、集群监控和集群运维。
2. 注意:免费但不开源(开源考虑Apache Ambari);CDH5无集群规模限制。
原理
Hadoop架构
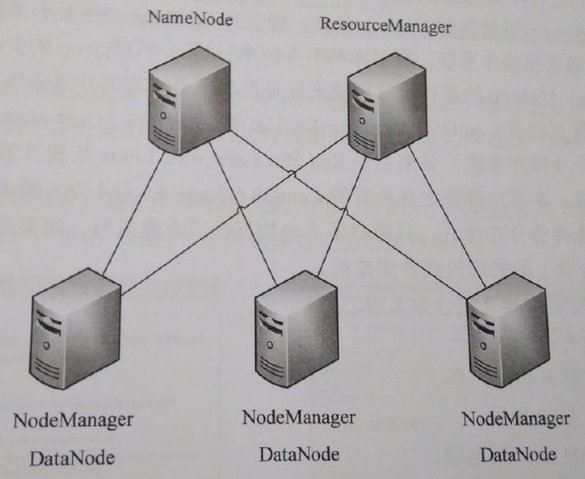
1. Hadoop集群:HDFS守护进程、YARN守护进程及运行这些守护进程的节点构成Hadoop集群。
2. 部署
a) 生产环境,为了性能和稳定性,建议NameNode和ResourceManager分开部署。
b) DataNode和NodeManager可部署在不同节点,但为了数据本地化,从而提高性能,NodeManager应部署在DataNode节点。

性能调优
硬件选型
1. 总体思路
a) 对集群整体规划时,常先根据存储空间估算集群大小,再在存储能力上估算计算资源。
b) Hadoop作业属于数据密集型非计算密集型(大量中间结果需磁盘和网络开销)。
2. NameNode内存估算
a) 原理:HDFS启动时,NameNode将元数据加载到内存,所以HDFS文件总数受限于NameNode内存容量。
b) 公式:一般,如果每个文件占用一个块,则100万个文件约占用300MB NameNode内存。
3. ResourceManager内存估算
a) 原理:ResourceManager默认保存最近100个作业的元数据,并且保存在内存。
4. 虚拟CPU数计算
a) 公式
虚拟CPU数 = CPU数 × 单CPU核数 × 单CPU核超线程数
b) 示例:双路六核CPU,HT(超线程)技术,虚拟CPU数=2×6×2=24。
5. 从节点内存估算
a) 公式:每个虚拟CPU分配4~8GB内存。
b) 示例:双路六核CPU,HT(超线程)技术,从节点内存至少96~192GB。
6. 从节点磁盘估算
a) 公式:根据每天集群处理的数据量估算;考虑副本数;至少为临时数据保留20%~30%空间。
b) 示例:如果每天数据量为1TB,副本数为3,则每天集群需3.6~9TB磁盘;如果有2台DataNode,则每天单DataNode需1.8~4.5GB磁盘。
7. 网络选型:千兆交换机,甚至万兆交换机。
8. 参考硬件
a) 中档配置
|
硬件 |
配置 |
|
CPU |
2×6 Core 2.9GHz / 15MB cache |
|
内存 |
128GB DDR3-1600 ECC |
|
磁盘控制器 |
SAS 6GB/s |
|
磁盘 |
12×3TB LFF SATA II 7200 RPM |
|
交换机 |
2×千兆交换机 |
b) 高档配置
|
硬件 |
配置 |
|
CPU |
2×6 Core 2.9GHz / 15MB cache |
|
内存 |
256GB DDR3-1600 ECC |
|
磁盘控制器 |
2×SAS 6GB/s |
|
磁盘 |
24×1TB SFF Nearline/MDL SAS 7200 RPM |
|
交换机 |
万兆交换机 |
操作系统调优
1. 禁用swap分区
a) swap分区:系统在物理内存不足时,把物理内存中一部分释放,以供当前运行程序使用。
b) vm.swappiness参数:范围0~100,值越高则系统内核越积极将应用程序数据交换到磁盘。
c) 调优:Hadoop守护进程数据交换到磁盘可能导致操作超时,修改/etc/sysctl.conf设置vm.swappiness为0。
2. 调整内存分配策略
a) CommitLimit是overcommit的阈值。CommitLimit=物理内存大小×vm.overcommit_ratio÷100+swap分区大小,vm.overcommit_ratio默认50。
b) vm.overcommit_memory参数
i) 0:Heuristic overcommit handling,默认值。允许overcommit,但过于明目张胆的overcommit会被拒绝。Heuristic的意思是“试探式的”,内核利用某种算法猜测你的内存申请是否合理,它认为不合理就会拒绝overcommit。
ii) 1:Always overcommit。允许overcommit,直至内存用完为止。
iii) 2:Don’t overcommit。不允许overcommit。
c) 调优:修改/etc/sysctl.conf设置vm.overcommit_memory为0,vm.overcommit_ratio为1,最后重启或刷新设置“sudo sysctl -p”生效。
3. 调整backlog上限
a) backlog:套接字监听队列,默认长度128。当一个请求尚未被处理或建立时,进入backlog,套接字服务器一次性处理backlog中所有请求。当服务器处理较慢,监听队列填满后,新请求被拒绝。
b) 调优:修改/etc/sysctl.conf设置net.core.somaxconn为32768,core-site.xml的“ipc.server.listen.queue.size”参数设置为32768,最后重启或刷新设置“sudo sysctl -p”生效。
4. 调整同时打开文件描述符上限
a) 文件描述符:当打开一个现有文件或创建一个新文件时,内核向进程返回一个文件描述符。
b) 调优:Hadoop作业可能同时打开多个文件。修改/etc/sysctl.conf设置fs.file-max为65535(系统级),同时修改/etc/security/limits.conf设置“hadoop hard nofile 65535”和“hadoop soft nofile 65535”(用户级,hadoop为用户名),最后重启或刷新设置“sudo sysctl -p”生效。
5. 禁用文件访问时间
a) 文件访问时间:如果开启记录文件访问时间,在每次读操作时,伴随一个写操作。
b) 调优:修改/etc/fstab,在需禁用的分区options字段后添加“noatime”,重启生效。
6. 禁用THP
a) Huge Pages:大小为2MB~1GB的内存页。
b) THP:Transparent Huge Pages,一个管理Huge Pages自动化的抽象层。
c) 调优:运行Hadoop作业时,THP会引起CPU占用率偏高,需禁用。
JVM调优
调优后效率提升约4%。
Hadoop参数调优
1. 总体原则(适用于许多分布式计算框架,如MapReduce、Spark)
a) 增大作业并行度,例如增大Map任务数。
b) 保证作业执行时有足够资源。
c) 满足前两条前提下,尽可能为Shuffle阶段提供资源。
2. core-site.xml
a) io.file.buffer.size
i. 默认值:4096
ii. 官方说明:The size of buffer for use in sequence files. The size of this buffer should probably be a multiple of hardware page size (4096 on Intel x86), and it determines how much data is buffered during read and write operations.
iii. 调优:设置为131072。
3. hdfs-site.xml
a) dfs.blocksize
i. 默认值:134217728
ii. 官方说明:The default block size for new files, in bytes. You can use the following suffix (case insensitive): k(kilo), m(mega), g(giga), t(tera), p(peta), e(exa) to specify the size (such as 128k, 512m, 1g, etc.), Or provide complete size in bytes (such as 134217728 for 128 MB).
iii. 调优:设置为128MB或256MB。
b) dfs.namenode.handler.count
i. 默认值:10
ii. 官方说明:The number of server threads for the namenode.
iii. 调优:设置为40。
c) dfs.datanode.max.transfer.threads
i. 默认值:40
ii. 官方说明:Specifies the maximum number of threads to use for transferring data in and out of the DN.
iii. 调优:当DataNode连接数超过该值,则拒绝连接。设置为65535。
d) dfs.datanode.balance.bandwidthPerSec
i. 默认值:1048576
ii. 官方说明:Specifies the maximum amount of bandwidth that each datanode can utilize for the balancing purpose in term of the number of bytes per second.
iii. 调优:设置为20971520,即20MB/s。
e) dfs.replication
i. 默认值:3
ii. 官方说明:Default block replication. The actual number of replications can be specified when the file is created. The default is used if replication is not specified in create time.
iii. 调优:当任务同时读取一个文件时,可能造成瓶颈,增大该值可有效缓解,但造成占用磁盘。可只修改Hadoop客户端,则影响从该客户端上传的文件副本数。
f) dfs.datanode.max.transfer.threads
i. 默认值:4096
ii. 官方说明:Specifies the maximum number of threads to use for transferring data in and out of the DN.
iii. 调优:设置为8192。
4. yarn-site.xml
a) yarn.nodemanager.resource.memory-mb
i. 默认值:8192
ii. 官方说明:Amount of physical memory, in MB, that can be allocated for containers.
iii. 调优:注意为操作系统和其他服务预留内存资源。
b) yarn.nodemanager.resource.cpu-vcores
i. 默认值:8
ii. 官方说明:Number of vcores that can be allocated for containers. This is used by the RM scheduler when allocating resources for containers. This is not used to limit the number of physical cores used by YARN containers.
iii. 调优:注意为操作系统和其他服务预留虚拟内存资源。虚拟CPU计算方法见操作系统调优。
c) yarn.scheduler.minimum-allocation-mb
i. 默认值:1024
ii. 官方说明:The minimum allocation for every container request at the RM, in MBs. Memory requests lower than this won't take effect, and the specified value will get allocated at minimum.
iii. 调优:无。
d) yarn.scheduler.maximum-allocation-mb
i. 默认值:8192
ii. 官方说明:The maximum allocation for every container request at the RM, in MBs. Memory requests higher than this won't take effect, and will get capped to this value.
iii. 调优:根据容器总量(即yarn.nodemanager.resource.memory-mb)设置,如果与之相等,则单任务内存资源使用不受限制。
e) yarn.scheduler.minimum-allocation-vcores
i. 默认值:1
ii. 官方说明:The minimum allocation for every container request at the RM, in terms of virtual CPU cores. Requests lower than this won't take effect, and the specified value will get allocated the minimum.
iii. 调优:无。
f) yarn.scheduler.maximum-allocation-vcores
i. 默认值:32
ii. 官方说明:The maximum allocation for every container request at the RM, in terms of virtual CPU cores. Requests higher than this won't take effect, and will get capped to this value.
iii. 调优:根据容器虚拟CPU总数(即yarn.nodemanager.resource.cpu-vcores)设置,如果与之相等,则单任务CPU资源使用不受限制。
5. mapred-site.xml
a) mapreduce.job.reduces
i. 默认值:1
ii. 官方说明:The default number of reduce tasks per job. Typically set to 99% of the cluster's reduce capacity, so that if a node fails the reduces can still be executed in a single wave. Ignored when mapreduce.jobtracker.address is "local".
iii. 调优:设置为0.95×NodeManager节点数或1.75×NodeManager节点数。
b) mapreduce.map.output.compress
i. 默认值:false
ii. 官方说明:Should the outputs of the maps be compressed before being sent across the network. Uses SequenceFile compression.
iii. 调优:设置为true。
c) mapreduce.map.output.compress.codec
i. 默认值:org.apache.hadoop.io.compress.DefaultCodec
ii. 官方说明:If the map outputs are compressed, how should they be compressed?
iii. 调优:设置为org.apache.hadoop.io.compress.SnappyCodec,由Google开源,CDH5已内置。
d) mapreduce.job.jvm.numtasks
i. 默认值:1
ii. 官方说明:How many tasks to run per jvm. If set to -1, there is no limit.
iii. 调优:设置为-1,即无JVM无限制次数重用。
e) mapreduce.map.speculative
i. 默认值:true
ii. 官方说明:If true, then multiple instances of some map tasks may be executed in parallel.
iii. 调优:保持默认值true,即开启推测机制有效放置因瓶颈而拖累整个作业。
f) mapreduce.reduce.speculative
i. 默认值:true
ii. 官方说明:If true, then multiple instances of some reduce tasks may be executed in parallel.
iii. 调优:保持默认值true,即开启推测机制有效放置因瓶颈而拖累整个作业。
g) mapreduce.cluster.local.dir
i. 默认值:${hadoop.tmp.dir}/mapred/local
ii. 官方说明:The local directory where MapReduce stores intermediate data files. May be a comma-separated list of directories on different devices in order to spread disk i/o. Directories that do not exist are ignored.
iii. 调优:设置多个磁盘,提供IO效率。
h) mapred.child.java.opts
i. 默认值:-Xmx200m
ii. 官方说明:Java opts for the task processes. The following symbol, if present, will be interpolated: @taskid@ is replaced by current TaskID. Any other occurrences of '@' will go unchanged. For example, to enable verbose gc logging to a file named for the taskid in /tmp and to set the heap maximum to be a gigabyte, pass a 'value' of: -Xmx1024m -verbose:gc -Xloggc:/tmp/@taskid@.gc Usage of -Djava.library.path can cause programs to no longer function if hadoop native libraries are used. These values should instead be set as part of LD_LIBRARY_PATH in the map / reduce JVM env using the mapreduce.map.env and mapreduce.reduce.env config settings.
iii. 调优:根据任务增大内存,并使用G1垃圾回收器。
i) mapreduce.map.java.opts
i. 默认值:空
ii. 调优:设置Map任务JVM参数,弥补mapred.child.java.opts粗粒度的不足。
j) mapreduce.reduce.java.opts
i. 默认值:空。
ii. 调优:设置Reduce任务JVM参数,弥补mapred.child.java.opts粗粒度的不足。
k) mapreduce.map.memory.mb
i. 默认值:1024
ii. 官方说明:The amount of memory to request from the scheduler for each map task.
iii. 调优:设置为-1,即从mapreduce.map.java.opts参数值继承。
l) mapreduce.reduce.memory.mb
i. 默认值:1024
ii. 官方说明:The amount of memory to request from the scheduler for each reduce task.
iii. 调优:设置为-1,即从mapreduce.reduce.java.opts参数值继承,一般要大于mapreduce.map.java.opts参数值。
m) mapreduce.map.cpu.vcores
i. 默认值:1
ii. 官方说明:The number of virtual cores to request from the scheduler for each map task.
iii. 调优:根据容器虚拟CPU数(即yarn.scheduler.maximum-allocation-vcores)设置,注意与mapreduce.map.memory.mb参数值保持线性比例。
n) mapreduce.reduce.cpu.vcores
i. 默认值:1
ii. 官方说明:The number of virtual cores to request from the scheduler for each reduce task.
iii. 调优:根据容器虚拟CPU数(即yarn.scheduler.maximum-allocation-vcores)设置,注意与mapreduce.reduce.memory.mb参数值保持线性比例。
o) yarn.app.mapreduce.am.resource.cpu-vcores
i. 默认值:1
ii. 官方说明:The number of virtual CPU cores the MR AppMaster needs.
iii. 调优:适当增大。
p) yarn.app.mapreduce.am.resource.mb
i. 默认值:1536
ii. 官方说明:The amount of memory the MR AppMaster needs.
iii. 调优:适当增大。
q) mapreduce.task.io.sort.mb
i. 默认值:100
ii. 官方说明:The total amount of buffer memory to use while sorting files, in megabytes. By default, gives each merge stream 1MB, which should minimize seeks.
iii. 调优:适当增大Map任务环形缓冲区大小。
r) mapreduce.reduce.shuffle.parallelcopies
i. 默认值:5
ii. 官方说明:The default number of parallel transfers run by reduce during the copy(shuffle) phase.
iii. 调优:适当调高,但过大将导致大量数据同时网络传输,引起IO压力,建议设置为4×lgn,n为集群规模。
作者:netoxi
出处:http://www.cnblogs.com/netoxi
本文版权归作者和博客园共有,欢迎转载,未经同意须保留此段声明,且在文章页面明显位置给出原文连接。欢迎指正与交流。