目录
· 分布式一致性理论
· 一致性级别
· 集中式系统
· 分布式系统
· ACID特性
· CAP理论
· BASE理论
· 一致性协议
· 命令
· Java API
· Curator
· 数据发布/订阅
· 配置管理
· 命名服务
· 集群管理
· Master选举
· 分布式锁
· 分布式队列
· Hadoop
· HBase
· Kafka
ZooKeeper安装
|
ID |
Host Name |
|
1 |
centos1 |
|
2 |
centos2 |
1. 配置机器名。
vi /etc/hosts
192.168.0.220 centos1
192.168.0.221 centos2
2. 安装JDK并配置环境变量(JAVA_HOME、CLASSPATH、PATH)。
3. 配置文件。
tar zxvf zookeeper-3.4.8.tar.gz -C /opt/app/ cd /opt/app/zookeeper-3.4.8/ mkdir data/ logs/ vi conf/zoo.cfg # 集群每台机器的zoo.cfg配置必须一致。
tickTime=2000 dataDir=/opt/app/zookeeper-3.4.8/data/ dataLogDir=/opt/app/zookeeper-3.4.8/data_logs/ clientPort=2181 initLimit=5 syncLimit=2 server.1=centos1:2888:3888 # 每台机器都要感知集群的机器组成,配置格式为“server.id=host:port:port”。id范围1~255。 server.2=centos2:2888:3888
# 在dataDir目录创建myid文件。根据zoo.cfg配置,id应与机器对应。如centos1的id为1,centos2的id为2. echo 1 > data/myid echo 2 > data/myid
4. 启动、关闭。
bin/zkServer.sh start bin/zkServer.sh stop bin/zkServer.sh status
5. 验证。
bin/zkCli.sh -server centos1:2181
[zk: centos1:2181(CONNECTED) 0] ls / [zookeeper] [zk: centos1:2181(CONNECTED) 1] create /helloworld 123 Created /helloworld [zk: centos1:2181(CONNECTED) 2] ls / [helloworld, zookeeper] [zk: centos1:2181(CONNECTED) 3] quit Quitting...
bin/zkCli.sh -server centos2:2181
[zk: centos2:2181(CONNECTED) 0] ls / [helloworld, zookeeper] [zk: centos2:2181(CONNECTED) 1] get /helloworld 123 cZxid = 0x100000008 ctime = Sat Jun 18 16:10:12 CST 2016 mZxid = 0x100000008 mtime = Sat Jun 18 16:10:12 CST 2016 pZxid = 0x100000008 cversion = 0 dataVersion = 0 aclVersion = 0 ephemeralOwner = 0x0 dataLength = 3 numChildren = 0 [zk: centos2:2181(CONNECTED) 2] quit Quitting...
分布式一致性理论
一致性级别
1. 强一致性:写入与读出数据一致。用户体验好,但对系统影响较大。
2. 弱一致性:写入后不承诺立即可以读到,也不承诺多久之后达到一致,但会尽可能保证到某个时间级别(比如秒级)后数据一致。细分:
a) 会话一致性:只保证同一个客户端会话中写入与读出数据一致,其他会话无法保证。
b) 用户一致性:只保证同一个用户中写入与读出数据一致,其他用户无法保证。
c) 最终一致性:保证在一定时间内,达到数据一致性。业界比较推崇的大型分布式系统数据一致性。
集中式系统
1. 特点:部署结构简单。
2. 问题:有明显的单点问题。
分布式系统
1. 定义:分布式系统是一个硬件或软件组件分布在不同的网络计算机上,彼此之间仅仅通过消息传递进行通信和协调的系统(摘自《分布式系统概念与设计》)。
2. 特点。
a) 分布性:多台计算机在空间上随意分布,并且分布情况随时变动。
b) 对等性:无主/从之分,既无控制整个系统的主机,也无被控制的从机。
c) 并发性:例如多个节点并发操作一些共享资源,诸如数据库或分布式存储。
d) 缺乏全局时钟:空间上随意分布的多个进程,由于缺乏全局时钟序列控制,很难定义谁先执行谁后执行
e) 故障总是会发生。
3. 副本(Replica):分布式系统对数据和服务提供的一种冗余方式。目的是为了提高数据的可靠性和服务的可用性。
4. 并发:如果逻辑控制流在时间上重叠,那么它们就是并发的。
5. 问题。
a) 通信异常:网络光纤、路由器或DNS等硬件设备或系统导致网络不可用;网络正常时通信延时大于单机,通常单机内存访问延时时纳秒数量级(约10ns),网络通信延时在0.1~1ms左右(105~106倍于内存访问)。
b) 网络分区:俗称“脑裂”。原书解释有问题,摘一段来自网络的解释:“Imagine that you have 10-node cluster and for some reason the network is divided into two in a way that 4 servers cannot see the other 6. As a result you ended up having two separate clusters; 4-node cluster and 6-node cluster. Members in each sub-cluster are thinking that the other nodes are dead even though they are not. This situation is called Network Partitioning (aka Split-Brain Syndrome).”。每个节点的加入与退出可看作特殊的网络分区。
c) 三态:三态即成功、失败和超时。由于网络不可靠,可能会出现超时。超时的两种情况:1)请求(消息)并未被成功地发送到接收方;2)请求(消息)成功地被接收方接收后进行了处理,但反馈响应给发送方时消息丢失。
d) 节点故障:每个节点每时每刻都可能出现故障。
ACID特性
1. 事务(Transaction):由一系列对系统中数据进行访问与更新的操作所组成的一个程序执行逻辑单元(Unit),狭义上的事务特指数据库事务。
2. 原子性(Atomicity):
a) 事务中各项操作只允许全部成功执行或全部执行失败。
b) 任何一项操作失败都将导致事务失败,同时其他已执行的操作将被撤销。
3. 一致性(Consistency):如果数据库发生故障,事务尚未完成被迫中断,事务中已执行的写操作不应该写入数据库。
4. 隔离性(Isolation):
a) 一个事务的执行不能被其他事务干扰。
b) Read Uncommitted、Read Committed、Repeatable Read、Serializable4个隔离级别,隔离性依次增高,并发性依次降低。
c) 4个隔离级别解决的隔离问题。
|
级别 问题 |
脏读 |
重复读 |
幻读 |
|
Read Uncommitted |
有 |
有 |
有 |
|
Read Committed |
无 |
有 |
有 |
|
Repeatable Read |
无 |
无 |
有 |
|
Serializable |
无 |
无 |
无 |
5. 持久性(Durability):一旦事务执行成功,对数据库的修改必须永久保存。
CAP理论
1. 内容:一个分布式系统不可能同时满足一致性(Consistency)、可用性(Availability)和分区容错性(Partion tolerance)这三个基本需求,最多只能同时满足其中两项。
2. 一致性:多个副本之间保持一致的特性。
3. 可用性:系统提供的服务必须一直处于可用状态,对于用户的每个操作请求总是能在有限时间内返回结果。“有限时间内”是系统设计之初设定好的运行指标,通常不同系统会有很大不同。
4. 分区容错性:遇到任何网络分区故障时,仍然能提供一致性和可用性的服务。
5. 权衡(摘自网络):
a) 对于多数大型互联网应用的场景,主机众多、部署分散,而且现在的集群规模越来越大,所以节点故障、网络故障是常态,而且要保证服务可用性达到N个9,即保证P和A,舍弃C(退而求其次保证最终一致性)。虽然某些地方会影响客户体验,但没达到造成用户流程的严重程度。
b) 对于涉及到钱财这样不能有一丝让步的场景,C必须保证。网络发生故障宁可停止服务,这是保证CA,舍弃P。貌似这几年国内银行业发生了不下10起事故,但影响面不大,报到也不多,广大群众知道的少。还有一种是保证CP,舍弃A。例如网络故障事只读不写。
BASE理论
1. BASE是Basically Available(基本可用)、Soft state(软状态)和Eventually consistency(最终一致性)的简写。
2. BASE核心思想:即使无法做到强一致性(Strong consistency),但可根据应用的自身业务特点,采用适当方式达到最终一致性(Eventually consistency)。
3. BASE是对CAP中一致性和可用性权衡的结果,来源于对大规模互联网系统分布式时间总结。
4. 基本可用:不可预知故障时,允许损失部分可用性。比如响应时间的损失、功能的损失。
5. 软状态:允许系统中的数据存在中间状态,并认为该状态不会影响系统整体可用性,即允许不同节点的数据副本同步存在延时。
6. 最终一致性:所有数据副本,在经过一段时间同步后,最终能达到一个一致性状态。
一致性协议
1. 最著名的一致性协议和算法:二阶段提交协议(2PC/Two-Phase Commit)、三阶段提交协议(3PC/Three-Phase Commit)和Paxos算法。
2. 绝大多数关系数据库采用2PC协议完成分布式事务。
ZooKeeper概况
1. ZooKeeper是一个分布式数据一致性解决方案,是Google Chubby(论文)的开源实现。
2. ZooKeeper采用ZAB(ZooKeeper Atomic Broadcast)一致性协议。
3. ZooKeeper保证如下分布式一致性特性。
a) 顺序一致性:同一客户端发起的请求,最终会严格按发起顺序应用到ZooKeeper中。
b) 原子性:所有请求的处理结果在整个集群所有机器上的应用情况是一致的。
c) 单一视图(Single System Image):客户端连接ZooKeeper任意一个服务器,看到的数据模型都是一致的。
d) 可靠性:应用了客户端请求之后,引起的数据变更被永久保存。
e) 实时性:仅保证在一定时间后,最终一致性。
4. ZooKeeper的设计目标。
a) 简单的数据模型:提供树形结构的命令空间,树上的数据节点称为ZNode。
b) 可以构建集群。
c) 顺序访问:客户端每个更新请求,都会分配一个全局唯一的递增编号,这个编号反应了所有操作的先后顺序。
d) 高性能:全局数据存储在内存,尤其适用于读为主的应用场景。
5. 集群角色。
a) 没有Master/Slave,而引入三种角色。
b) Leader:为客户端提供读、写服务。通过Leader选举过程产生。
c) Follower:为客户端提供读、写服务,如果是写请求则转发给Leader。参与Leader选举过程。
d) Observer:与Follower相同,唯一区别是不参加Leader选举过程。
6. 数据节点ZNode。
a) 分为持久节点和临时节点(Ephemeral Node),临时节点在客户端会话失效后被移除,而持久节点在执行移除操作后才被移除。
b) 顺序节点(Sequence Node),被创建时ZooKeeper自动在其节点名后追加一个整型数字(唯一命名)。
7. 版本:每个ZNode都有一个Stat数据结构,包含version(当前ZNode的版本)、cversion(当前ZNode子节点的版本)和aversion(当前ZNode的ACL版本)。
8. Watcher。
a) 允许客户端在指定节点上注册一些Watcher,在这些特定事件触发时,ZooKeeper将事件通知到注册的客户端上。
b) 即Publish/Subscribe(发布/订阅)。
9. ACL(Access Control Lists)。
a) ZooKeeper采用ACL策略进行权限控制,类似UNIX文件系统权限控制。
b) CREATE:创建子节点权限。
c) READ:获取节点数据和子节点列表的权限。
d) WRITE:更新节点数据的权限。
e) DELETE:删除子节点的权限。
f) ADMIN设置节点ACL的权限。
10. 集群组成。
a) “过半存货即可用”指如果ZooKeeper集群要对外可用,必须要有过半的机器正常工作并且彼此之间正常通信。即如果搭建一个允许F台机器宕机的集群,则要部署2xF+1台服务器。
b) 6台机器的集群可用性上并不比5台机器的集群高,所以产生了“官方推荐服务器数为奇数”的说法。
c) 需澄清:任意服务器数的ZooKeeper集群都能部署且正常运行。
ZooKeeper API
命令
1. 创建节点:create [-s] [-e] path data [acl],-s顺序节点,-e临时节点。
2. 列出子节点:ls path [watch]。
3. 获取节点:get path [watch]。
4. 更新节点:set path data [version]。
5. 删除节点:delete path [version]。
6. 删除节点及其子节点:rmr path。
7. 举例。
[zk: localhost:2181(CONNECTED) 0] create /test A Created /test [zk: localhost:2181(CONNECTED) 1] create /test/mynode B Created /test/mynode [zk: localhost:2181(CONNECTED) 2] create -s /test/snode 0 Created /test/snode0000000001 [zk: localhost:2181(CONNECTED) 3] create -s /test/snode 0 Created /test/snode0000000002 [zk: localhost:2181(CONNECTED) 4] create -s /test/snode 0 Created /test/snode0000000003 [zk: localhost:2181(CONNECTED) 5] ls /test [snode0000000002, mynode, snode0000000001, snode0000000003] [zk: localhost:2181(CONNECTED) 6] get /test/mynode B cZxid = 0x200000029 ctime = Sun Jun 19 00:04:05 CST 2016 mZxid = 0x200000029 mtime = Sun Jun 19 00:04:05 CST 2016 pZxid = 0x200000029 cversion = 0 dataVersion = 0 aclVersion = 0 ephemeralOwner = 0x0 dataLength = 1 numChildren = 0 [zk: localhost:2181(CONNECTED) 7] set /test/mynode C cZxid = 0x200000029 ctime = Sun Jun 19 00:04:05 CST 2016 mZxid = 0x20000002d mtime = Sun Jun 19 00:05:34 CST 2016 pZxid = 0x200000029 cversion = 0 dataVersion = 1 aclVersion = 0 ephemeralOwner = 0x0 dataLength = 1 numChildren = 0 [zk: localhost:2181(CONNECTED) 8] delete /test/mynode [zk: localhost:2181(CONNECTED) 9] ls /test [snode0000000002, snode0000000001, snode0000000003]
Java API
待补充。
Curator
1. Curator是Netflix开源的一套ZooKeeper客户端框架,解决了很多ZooKeeper客户端非常底层的细节开发工作(如连接重连、反复注册Watcher、NodeExistsException异常等),是全世界最广泛的ZooKeeper客户端之一。
2. Curator的API最大亮点在于遵循了Fluent设计风格。
3. Maven依赖配置。
<dependency> <groupId>org.apache.curator</groupId> <artifactId>curator-framework</artifactId> <version>2.10.0</version> </dependency> <dependency> <groupId>org.apache.curator</groupId> <artifactId>curator-recipes</artifactId> <version>2.10.0</version> </dependency>
ZooKeeper应用场景
数据发布/订阅
ZooKeeper采用推拉结合的“发布/订阅”方式:客户端向服务器注册关注的节点,节点的数据变化时,服务器向客户端发送Watcher事件通知,客户端收到通知后主动到服务器获取最新数据。
配置管理
1. 全局配置信息通常具备3个特性:
a) 数据量比较小;
b) 运行时数据内容动态变化;
c) 集群中个机器共享,配置一致。
2. 例如机器列表信息、运行时的开关配置、数据库配置信息等。
3. 实现原理:“发布/订阅”(Watcher)。
4. 以数据库切换举例。
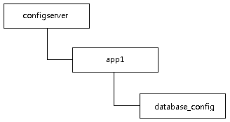
a) 配置存储:管理员创建ZNode存储配置。
1 import org.apache.curator.RetryPolicy; 2 import org.apache.curator.framework.CuratorFramework; 3 import org.apache.curator.framework.CuratorFrameworkFactory; 4 import org.apache.curator.retry.ExponentialBackoffRetry; 5 import org.apache.curator.utils.CloseableUtils; 6 7 public class CreateConfig { 8 9 public static void main(String[] args) throws Exception { 10 String path = "/configserver/app1/database_config"; 11 String config = "jdbc.driver=com.mysql.jdbc.Driver " 12 + "jdbc.url=jdbc:mysql://centos1:3306/test?useUnicode=true&characterEncoding=utf8 " 13 + "jdbc.username=test " 14 + "jdbc.password=test "; 15 16 RetryPolicy retryPolicy = new ExponentialBackoffRetry(1000, 3); 17 CuratorFramework client = null; 18 try { 19 client = CuratorFrameworkFactory.builder() 20 .connectString("centos1:2181,centos2:2181") 21 .sessionTimeoutMs(5000) 22 .retryPolicy(retryPolicy) 23 .build(); // Fluent 24 client.start(); 25 client.create() 26 .creatingParentContainersIfNeeded() 27 .forPath(path, config.getBytes()); 28 } finally { 29 CloseableUtils.closeQuietly(client); 30 } 31 } 32 33 }
b) 配置获取:集群机各机器启动时获取配置,并注册该ZNode数据变更的Watcher。
1 import org.apache.curator.RetryPolicy; 2 import org.apache.curator.framework.CuratorFramework; 3 import org.apache.curator.framework.CuratorFrameworkFactory; 4 import org.apache.curator.framework.recipes.cache.NodeCache; 5 import org.apache.curator.framework.recipes.cache.NodeCacheListener; 6 import org.apache.curator.retry.ExponentialBackoffRetry; 7 import org.apache.curator.utils.CloseableUtils; 8 9 public class RunServer { 10 11 public static void main(String[] args) throws Exception { 12 String path = "/configserver/app1/database_config"; 13 14 RetryPolicy retryPolicy = new ExponentialBackoffRetry(1000, 3); 15 CuratorFramework client = null; 16 NodeCache nodeCache = null; 17 try { 18 client = CuratorFrameworkFactory.builder() 19 .connectString("centos1:2181,centos2:2181") 20 .sessionTimeoutMs(5000) 21 .retryPolicy(retryPolicy) 22 .build(); 23 client.start(); 24 byte[] data = client.getData() 25 .forPath(path); 26 System.out.println("Get config when server starting."); 27 System.out.println(new String(data)); 28 29 // Register watcher 30 nodeCache = new NodeCache(client, path, false); 31 nodeCache.start(true); 32 final NodeCache nc = nodeCache; 33 nodeCache.getListenable().addListener(new NodeCacheListener() { 34 35 @Override 36 public void nodeChanged() throws Exception { 37 System.out.println("Get config when changed."); 38 System.out.println(new String(nc.getCurrentData().getData())); 39 } 40 41 }); 42 43 Thread.sleep(Long.MAX_VALUE); 44 45 } finally { 46 CloseableUtils.closeQuietly(nodeCache); 47 CloseableUtils.closeQuietly(client); 48 } 49 } 50 51 }
c) 配置变更:管理员修改ZNode的数据(配置)。
1 import org.apache.curator.RetryPolicy; 2 import org.apache.curator.framework.CuratorFramework; 3 import org.apache.curator.framework.CuratorFrameworkFactory; 4 import org.apache.curator.retry.ExponentialBackoffRetry; 5 import org.apache.curator.utils.CloseableUtils; 6 7 public class UpdateConfig { 8 9 public static void main(String[] args) throws Exception { 10 String path = "/configserver/app1/database_config"; 11 String config = "jdbc.driver=com.mysql.jdbc.Driver " 12 + "jdbc.url=jdbc:mysql://centos2:3306/test?useUnicode=true&characterEncoding=utf8 " 13 + "jdbc.username=foo " 14 + "jdbc.password=foo "; 15 16 RetryPolicy retryPolicy = new ExponentialBackoffRetry(1000, 3); 17 CuratorFramework client = null; 18 try { 19 client = CuratorFrameworkFactory.builder() 20 .connectString("centos1:2181,centos2:2181") 21 .sessionTimeoutMs(5000) 22 .retryPolicy(retryPolicy) 23 .build(); // Fluent 24 client.start(); 25 client.setData() 26 .forPath(path, config.getBytes()); 27 } finally { 28 CloseableUtils.closeQuietly(client); 29 } 30 } 31 32 }
命名服务
1. 分布式系统中,被命名的实体通常是集群中的机器、提供的服务地址或远程对象等。
2. 广义上命名服务的资源定位不一定是实体资源,比如分布式全局唯一ID。
3. 以数据库主键(分布式全局唯一ID的一种)举例。

a) 可使用UUID,但UUID的缺点:长度过长;字面上看不出含义。
b) 实现原理:顺序节点。
c) 代码。
1 import org.apache.curator.RetryPolicy; 2 import org.apache.curator.framework.CuratorFramework; 3 import org.apache.curator.framework.CuratorFrameworkFactory; 4 import org.apache.curator.retry.ExponentialBackoffRetry; 5 import org.apache.curator.utils.CloseableUtils; 6 import org.apache.zookeeper.CreateMode; 7 8 public class GenerateId { 9 10 public static void main(String[] args) throws Exception { 11 for (int index = 0; index < 10; index++) { 12 // type1-job-0000000000 13 System.out.println(generate("type1")); 14 } 15 for (int index = 0; index < 5; index++) { 16 // type2-job-0000000000 17 System.out.println(generate("type2")); 18 } 19 } 20 21 private static String generate(String type) throws Exception { 22 String path = "/generateid/" + type + "/job-"; 23 24 RetryPolicy retryPolicy = new ExponentialBackoffRetry(1000, 3); 25 CuratorFramework client = null; 26 try { 27 client = CuratorFrameworkFactory.builder() 28 .connectString("centos1:2181,centos2:2181") 29 .sessionTimeoutMs(5000) 30 .retryPolicy(retryPolicy) 31 .build(); 32 client.start(); 33 path = client.create() 34 .creatingParentContainersIfNeeded() 35 .withMode(CreateMode.PERSISTENT_SEQUENTIAL) 36 .forPath(path); 37 return type + '-' + path.substring(path.lastIndexOf('/') + 1); 38 } finally { 39 CloseableUtils.closeQuietly(client); 40 } 41 } 42 43 }
集群管理
1. 集群机器监控。
a) 实现过程:监控系统在/cluster_server节点上注册Watcher监听,添加机器时,由机器在/cluster_server节点下创建一个临时节点/cluster_server/[host_name],并定时写入运行状态信息。
b) 既能实时获取机器的上/下线情况,又能获取机器的运行信息。
c) 适合大规模分布式系统监控。
2. 分布式日志收集。
a) 日志系统包含日志源机器和收集器机器,由于硬件问题、扩容、机房迁移或网络问题等原因,他们都在变更。
b) 实现过程。
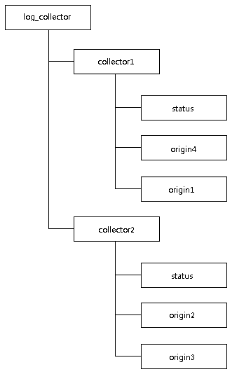
i. 注册收集器机器:收集器机器启动时创建一个持久节点/log_collector/[collector_hostname],再创建一个临时节点/log_collector/[collector_hostname]/status,写入运行状态信息。
ii. 任务分发:日志系统将全部日志源机器分为若干组,分别在相应的收集器机器创建的节点/log_collector/[collector_hostname]下创建持久节点/log_collector/[collector_hostname]/[origin_hostname],而收集器机器获取/log_collector/[collector_hostname]的子节点来得到日志源机器列表,同时Watcher监听/log_collector/[collector_hostname]的子节点变化。
iii. 动态分配:日志系统始终Watcher监听/log_collector下的全部子节点,当有新收集器机器加入时,则将负载高的任务重新分配给新收集器机器;当有收集器机器退出时,则将其下的日志源机器重新分配给其他收集器机器。
Master选举
1. Master用来协调集群中其他系统单元,具有对分布式系统状态变更的决定权。例如读写分离场景中,客户端写请求是由Master处理的。
2. 实现原理:利用ZooKeeper强一致性,保证在分布式高并发情况下节点创建一定全局唯一,即保证客户端无法重复创建一个已存在的ZNode。
3. 实现过程:选举时,集群中各机器同时创建临时节点/master_election,并写入机器信息,创建成功的机器成为Master,创建失败的机器Watcher监控节点/master_election开始等待,一旦该节点被移除则重新选举。
4. Curator封装了Master选举功能。
1 import org.apache.curator.RetryPolicy; 2 import org.apache.curator.framework.CuratorFramework; 3 import org.apache.curator.framework.CuratorFrameworkFactory; 4 import org.apache.curator.framework.recipes.leader.LeaderSelector; 5 import org.apache.curator.framework.recipes.leader.LeaderSelectorListenerAdapter; 6 import org.apache.curator.retry.ExponentialBackoffRetry; 7 import org.apache.curator.utils.CloseableUtils; 8 9 public class MasterElection { 10 11 public static void main(String[] args) throws Exception { 12 String path = "/master_election"; 13 14 RetryPolicy retryPolicy = new ExponentialBackoffRetry(1000, 3); 15 CuratorFramework client = null; 16 LeaderSelector selector = null; 17 try { 18 client = CuratorFrameworkFactory.builder() 19 .connectString("centos1:2181,centos2:2181") 20 .sessionTimeoutMs(5000) 21 .retryPolicy(retryPolicy) 22 .build(); 23 client.start(); 24 selector = new LeaderSelector(client, path, new LeaderSelectorListenerAdapter() { 25 26 @Override 27 public void takeLeadership(CuratorFramework client) throws Exception { 28 long threadId = Thread.currentThread().getId(); 29 System.out.println("Thread" + threadId + " is master."); 30 Thread.sleep(3000); 31 System.out.println("Thread" + threadId + " has been down."); 32 System.exit(0); 33 } 34 35 }); 36 selector.autoRequeue(); 37 selector.start(); 38 Thread.sleep(Long.MAX_VALUE); 39 40 } catch (InterruptedException e) { 41 e.printStackTrace(); 42 43 } finally { 44 CloseableUtils.closeQuietly(selector); 45 CloseableUtils.closeQuietly(client); 46 } 47 } 48 49 }
分布式锁
1. 分布式锁是控制分布式系统之间同步访问共享资源的一种方式。
2. 分布式锁分为排它锁(Exclusive Lock,简称X锁,又称写锁、独占锁)和共享锁(Shared Lock,简称S锁,又称读锁)。
a) 排它锁类似JDK的synchronized和ReentrantLock。
b) 共享锁类似JDK的ReadWriteLock中的读锁。
3. 排它锁实现过程:与Master选举类似。所有客户端同时创建临时节点/execlusive_lock,创建成功的客户端获取了锁,创建失败的客户端Watcher监听节点/execlusive_lock开始等待,一旦该节点被移除(即排它锁已释放)则重复该过程。
4. 共享锁实现过程:
a) 创建持久节点/shared_lock。
b) 所有客户端根据需要的锁类型(R/W)创建临时顺序节点/shared_lock/[hostname-R/W-],如/shared_lock/[host1-R-0000000000]、/shared_lock/host1-W-0000000003。
c) 获取/shared_lock下的所有子节点。
d) 各客户端确定自己的节点顺序。
i. 当前客户端需要R锁时,如果无比自己序号小的子节点或所有比自己序号小的子节点都是R锁,则获取R锁成功;如果比自己序号小的子节点有W锁,则Watcher监听该W锁节点并等待。
ii. 当前客户端需要W锁时,如果自己序号是最小的子节点,则获取W锁成功,否则Watcher监听比自己序号小的子节点中序号最大的节点并等待。
e) 各客户端收到Watcher通知后,则获取锁成功。
5. Curator封装了分布式锁功能。
分布式队列
1. 业界分布式队列产品大多是消息中间件(或称消息队列),ZooKeeper也可实现分布式队列功能。
2. 分布式队列分为FIFO和Barrier两种:
a) FIFO即常见的队列;
b) Barrier类似JDK的CyclicBarrier,等待的数量达到一定值时才执行。
3. FIFO实现过程(类似共享锁):
a) 创建持久节点/queue_fifo。
b) 所有客户端创建临时顺序节点/queue_fifo/[hostname-],如/queue_fifo/host1-0000000000。
c) 获取/ queue_fifo下的所有子节点。
d) 各客户端确定自己的节点顺序:如果自己序号是最小的子节点,则执行;否则Watcher监听比自己序号小的节点中序号最大的节点并等待。
e) 收到Watcher通知后,则执行。
4. Barrier实现过程:
a) 创建持久节点/queue_barrier。
b) 所有客户端创建临时节点/queue_barrier/[hostname],如/queue_fifo/host1。
c) 获取/ queue_fifo下的所有子节点。
d) 如果子节点数大于或等于某值,则执行;否则Watcher监听节点/queue_barrier并等待。
e) 收到Watcher通知后,重复步骤c。
Hadoop
1. HDFS的NameNode和YARN的ResourceManager都是基于ZooKeeper实现HA。
2. YARN的HA实现过程(类似Master选举):
a) 运行期间,多个ResourceManager并存,但只有一个为Active状态,其他为Standby状态。
b) 当Active状态的节点无法工作时,Standby状态的节点竞争选举产生新的Active节点。
c) 假设ResourceManager1“假死”,可能会导致ResourceManager2变为Active状态,当ResourceManager1恢复后,出现“脑裂”。通过ACL权限控制可以解决,即ResourceManager1恢复后发现ZNode不是自己创建,则自动切换为Standby状态。
HBase
与大部分分布式NoSQL数据库不同的是,HBase的数据写入是强一致性的,甚至索引列也是强一致性。
Kafka
Kafka主要用于实现低延时的发送和收集大量的事件和日志数据。大型互联网Web应用中,指网站的PV数和用户访问记录等。
作者:netoxi
出处:http://www.cnblogs.com/netoxi
本文版权归作者和博客园共有,欢迎转载,未经同意须保留此段声明,且在文章页面明显位置给出原文连接。欢迎指正与交流。