先明确几个概念
基础概念部分
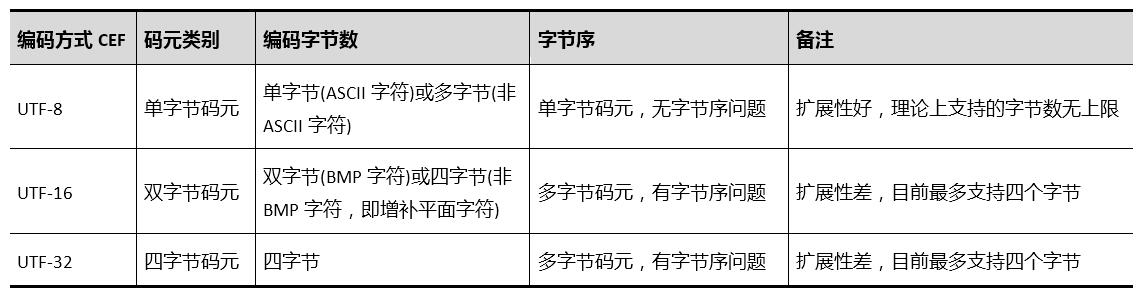
1.字符编码方式CEF(Character Encoding Form)
对符号进行编码,便于处理与显示
常用的编码方式有
GB2312(汉字国标码 2字节)
ASCII (标准交换字符 1字节)
UNICODE(统一码, 4字节;现常用2字节编码方式,即使用第0组第0面(BMP字符),不包含扩充字符)

2.码点(Code Point)
二维表中行与列相交的点,称之为码点,也称之为码位(Code position);每个码点分配一个唯一的编号,称之为码点值或码点编号,除开某些特殊区域(比如代理区、专用区)的非字符码点和保留码点,每个码点唯一对应于一个字符。
3.码元(Code Unit)
在计算机存储和网络传输时,码点值(即字符编号)被映射到一个或多个码元。
码元可理解为字符编码方式CEF对码点值进行编码处理时作为一个整体来看待的最小基本单元(基本单位)。
最常用的码元是8位(1字节)的单字节码元,另外还有16位(2字节)和32位(4字节)两种多字节码元,分别相当于C++中的无符号整型BYTE、WORD、DWORD
用代码表示如下:
typedef unsigned char BYTE; //1个字节
typedef unsigned short WORD; //2个字节
typedef unsigned long DWORD; //4个字节
4.编码字符集和字符集编码
Unicode是编码字符集,而UTF-8、UTF-16、UTF-32是字符集编码
通俗来说Unicode是给字符编了序号,而这些序号具体怎么传输和表示则是不同UTF来决定。
UTF编码方式
UNICODE编码下,这三种码元对应不同的三种UTF编码方式(即Unicode码转换格式Unicode Transformation Format,或称通用字符集转换格式UCS Transformation Format):
- UTF-8(8-bit Unicode/UCS Transformation Format),
- UTF-16(16-bit Unicode/UCS Transformation Format),
- UTF-32(32-bit Unicode/UCS Transformation Format);
下面分别介绍这三种编码方式
UTF-8
UTF-8是一种变长字节编码方式。对于某一个字符的UTF-8编码,如果只有一个字节则其最高二进制位为0;如果是多字节,其第一个字节从最高位开始,连续的二进制位值为1的个数决定了其编码的位数,其余各字节均以10开头。UTF-8最多可用到6个字节。
如表:
1字节 0xxxxxxx
2字节 110xxxxx 10xxxxxx
3字节 1110xxxx 10xxxxxx 10xxxxxx
4字节 11110xxx 10xxxxxx 10xxxxxx 10xxxxxx
5字节 111110xx 10xxxxxx 10xxxxxx 10xxxxxx 10xxxxxx
6字节 1111110x 10xxxxxx 10xxxxxx 10xxxxxx 10xxxxxx 10xxxxxx
以"汉"字为例
Unicode字符编码值 0x6C49
对应十进制为23383
对应二进制为110 1100 0100 1001
那么利用UTF-8的编码规则 一个16位Unicode编码至少需要用三个字节(24位)来表示
则第一个字节的前三位应为111
而后两个字节分别可以包含Unicode编码的6位,共12位
所以第一个字节应包含第13-16位,共4位
第一个字节为 0xE6 11100110
第二个字节为 0xB1 10110001
第三个字节为 0x89 10001001
将Unicode字符编码与UTF-8进行对比 可以较好理解上述规则
Unicode码: 110 110001 001001
UTF-8 码: 11100 110 10 110001 10 001001
UTF-16码
相对简单
直接为Unicode编码值0x6C49
UTF-32码
在UTF-16上进一步扩充即可得到
UTF-32编码值为0x00006C49
下图为其他示例字符图,读者利用上述可以进行验证。
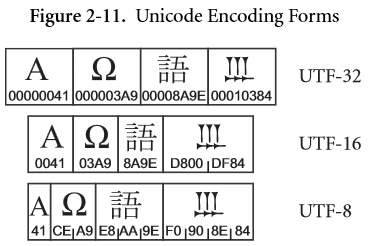
最后是多字节码元的UTF-16、UTF-32不同之处