本人小硕一枚,方向是深度学习的目标检测,故想把从RCNN到Faster RCNN整个线串一下,理清里面的整个设计流程和创新思路,也算是对大神的创新思维进行学习。我会不定期改善博客里面可能存在的小错误,希望大家多多谅解支持啦。另外,在论文中已经讲到的点,如果不是特别重要的话,我不会再复述的啦,所以说各位看官先研读研读论文先,然后再看看我对这些论文的理解。对了,涉及到哪层是几乘几以及那层到底是多少这种细节,在这里不做太多讨论,除非涉及到核心思想,更多的细节将在我之后的博客——对Faster RCNN源码的解读中进行。
什么是object detection
object detection我的理解,就是在给定的图片中精确找到物体所在位置,并标注出物体的类别。object detection要解决的问题就是在哪里,是什么,具体在哪里这整个流程的问题。然而,这个问题可不是那么容易解决的,物体的尺寸变化范围很大,摆放物体的角度,姿态不定,而且可以出现在图片的任何地方,更何况物体还可以是多个类别。故用一般的方法是比较难处理的,这也是为什么在深度学习兴起之前,ILSVRC检测比赛检测那么沉寂的原因,大家都做的太差了嘛~~不过随着Hinton在2012年的比赛用CNN虐杀其他团队之后,深度学习以及深度卷积网络再一次进入人们视线,这种比较困难的问题也渐渐有思路了。在开始接触物体检测和深度学习时,我想凭借深度学习强大的拟合能力,给它啥它都能学,最开始的想法是,先训练出一个网络能分出是否是物体,即先不管是什么物体,只要bounding box 与ground truth 的IOU大于某个阈值,就认为是正样本,小于某个阈值为负样本,然后直接训练,然后直接给它ground truth,然后用当前框位置与ground truth的欧式距离作为loss,让它自己去学习什么是object以及object在哪里呢,也就是说把这个任务当成分类问题+回归问题来做??通过这个网络在一张大图sliding windows,就能确定存在物体的区域,再根据回归,来使得bounding box框得更准。不过实际上,想想就能知道,这种方法是开始没有任何限制地去学习,这样会导致任务复杂度非常高,网络会不收敛,而且在测试的时候会非常慢,因为不知道在哪里有什么东西,需要sliding windows并且需要不同尺度的缩放,另外并且在RCNN的论文中提到了不加限制直接当回归来做实际效果并不是特别好。我觉得不好的原因可能是学习的复杂度太高,这相当于在一开始就没有给任何限制,让网络自己去根据自己预测的和真实的框的距离差去学习,这样子的话,同一种物品在不同位置以不同的大小都可以认为是全新的一个训练样本,完全去拟合这样的任务显然是不太可能的。所以说,这种问题一定要先降低任务复杂度,然后再去学习降低复杂度的等价任务。当然这是我看了这么多优秀论文得出的马后炮式的结论,不过这也恰好说明了Ross Girshick大神科研出RCNN这种跨时代的东东时,思路到底有多么地超前。他为了降低检测任务的复杂度,把检测任务最直观的在哪里(回归问题),转化成先用传统方法先定候选框(通过边缘特征啊,轮廓特征啊什么的使得整个问题的复杂度降低,我不是全图搜索object,而是只在符合proposals算法的区域来搜索),然后在确定是什么(是背景还是是某种物体),然后根据这些已经判断是物体的区域(object score分数高于阈值)来进行回归(精确位置所在)。通过我以上的分析,我觉得检测最难做的是网络判断物体大致在哪里这个过程,而具体是什么,精确位置,当知道大致的位置后也就变得异常简单了。这个思路下来,也就是RCNN,Fast RCNN,Faster RCNN这一条线了。
RCNN 详解
说了这么多有关object detection的个人见解,我还是说说这个跨时代的RCNN吧,如果我写的不够详细的话,我相信大家在别的博客上也能看到RCNN的介绍。流程图大家应该都比较熟悉了,
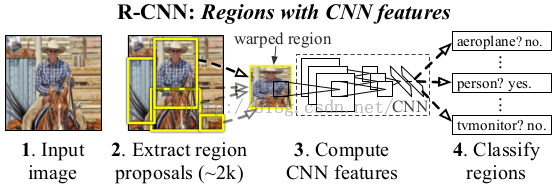
RCNN全程就是Regions with CNN features,从名字也可以看出,RCNN的检测算法是基于传统方法来找出一些可能是物体的区域,再把该区域的尺寸归一化成卷积网络输入的尺寸,最后判断该区域到底是不是物体,是哪个物体,以及对是物体的区域进行进一步回归的微微调整(与深度学习里的finetune去分开,我想表达的就只是对框的位置进行微微调整)学习,使得框的更加准确。这就是主要的思路,我去,直接说完了??还是再说一下具体细节吧,这样也好为下一章过渡一下,哈哈。
正如上面所说的,RCNN的核心思想就是把图片区域内容送给深度网络,然后提取出深度网络某层的特征,并用这个特征来判断是什么物体(文章把背景也当成一种类别,故如果是判断是不是20个物体时,实际上在实现是判断21个类。),最后再对是物体的区域进行微微调整。实际上文章内容也说过用我之前所说的方法(先学习分类器,然后sliding windows),不过论文用了更直观的方式来说明这样的消耗非常大。它说一个深度网络(alexNet)在conv5上的感受野是195×195,按照我的理解,就是195×195的区域经过五层卷积后,才变成一个点,所以想在conv5上有一个区域性的大小(7×7)则需要原图为227×227,这样的滑窗每次都要对这么大尺度的内容进行计算,消耗可想而知,故论文得下结论,不能用sliding windows的方式去做检测(消耗一次用的不恰当,望各位看官能说个更加准确的词)。不过论文也没有提为什么作者会使用先找可能区域,再进行判断这种方式,只是说他们根据09年的另一篇论文[1],而做的。这也算是大神们与常人不同的积累量吧。中间的深度网络通过ILSVRC分类问题来进行训练,即利用训练图片和训练的分类监督信号,来学习出这个网络,再根据这个网络提取的特征,来训练21个分类器和其相应的回归器,不过分类器和回归器可以放在网络中学习,这也是下面要讲的Fast RCNN的内容。
最后补充一下大牛们的针对rcnn的创新思路吧,从上面图片我们可以把RCNN看成四个部分,ss提proposals,深度网络提特征,训练分类器,训练对应回归器,这四个是相对独立的,每种算法都有它的缺陷,那么我们如何对它进行改进呢?如果让你现在对这个算法进行改进,该怎么改进呢??首先肯定能想到的是,如何让深度网络更好的训练,之前训练只用了分类信息,如果先利用ground truth信息把图片与object 无关的内容先cut掉,然后再把cut后的图片用于深度网络的训练,这样训练肯定会更好。这是第一种思路,另外如果把最后两个放在一起训练,并放入深度网络中,这就是joint learning,也就是Fast RCNN的内容,如果把ss也放入深度网络中,成为一个大的网络,则是Faster RCNN的内容。这也就是后面一系列论文的思路了。(这个如何创新的思维是从某某公司的深度学习讲座听到的,我只是深刻学习后地一名合格的搬运工,哈哈。)
SPP详解
SPP网络,我不得不要先说,这个方法的思想在Fast RCNN, Faster RCNN上都起了举足轻重的作用。SPP网络主要是解决深度网络固定输入层尺寸的这个限制,也从各个方面说明了不限制输入尺寸带来的好处。文章在一开始的时候就说明了目前深度网络存在的弊端:如果固定网络输入的话,要么选择crop策略,要么选择warp策略,crop就是从一个大图扣出网络输入大小的patch(比如227×227),而warp则是把一个bounding box的内容resize成227×227 。无论是那种策略,都能很明显看出有影响网络训练的不利因素,比如crop就有可能crop出object的一个部分,而无法准确训练出类别,而warp则会改变object的正常宽高比,使得训练效果变差。接着,分析了出深度网络需要固定输入尺寸的原因是因为有全链接层,不过在那个时候,还没有FCN的思想,那如何去做才能使得网络不受输入尺寸的限制呢?Kaiming He 大神就想出,用不同尺度的pooling 来pooling出固定尺度大小的feature map,这样就可以不受全链接层约束任意更改输入尺度了。下图就是SPP网络的核心思想:
通过对feature map进行相应尺度的pooling,使得能pooling出4×4, 2×2, 1×1的feature map,再将这些feature map concat成列向量与下一层全链接层相连。这样就消除了输入尺度不一致的影响。训练的时候就用常规方法训练,不过由于不受尺度的影响,可以进行多尺度训练,即先resize成几个固定的尺度,然后用SPP网络进行训练,学习。这里讲了这么多,实际上我想讲的是下面的 东西, SPP如何用在检测上面。论文中实际上我觉得最关键的地方是提出了一个如何将原图的某个region映射到conv5的一种机制,虽然,我并不是太认可这种映射机制,等下我也会说出我认为合理的映射方法。论文中是如何映射的,实际上我也是花了好久才明白。
首先,我想先说明函数这个东东,当然我不是通过严谨的定义来说明。什么是y=f(x),我认为只要输入x,有一组固定的操作f,然后产生一个对应的y,这样子就算是函数。根据输入有一个一一对应的输出,这就是函数。这样理解的话,卷积也是函数,pooling也是函数。当然我并不想说明函数是什么,什么是函数,实际上我想强调的是一一对应这样的关系。大家都知道,现在默许的无论是卷积还是pooling(无stride),都会加相应的pad,来使得卷积后的尺寸与卷积前相同,当然这种做法还个好处就是使得边缘不会只被卷积一次就消失了~这样子的话,实际上原图与卷积后的图就是一一对应的关系。原图的每一个点(包括边缘)都可以卷积得到一个新的点,这就是一一对应了。如下图所示(自己画得太丑):
绿色部分是图片,紫色部分是卷积核。
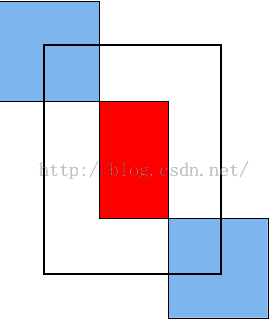
如上图可以看出,蓝色的区域是原图区域,而红色的区域是padding区域,紫色的是卷积核。卷积后得到的区域与原区域是一一对应的。而卷积或pooling增加stride的话就相当与原图先进行卷积或池化,再进行sampling,这还是能一一对应的,就这样原图的某个区域就可以通过除以网络的所有stride来映射到conv5后去区域。终于把这里讲出来了,大家如果直接按照函数的一一对应关系去理解,很容易理解为什么原图的区域除以所有的stride就是映射到conv5的区域。这样子就可以在原图上的一些操作放在conv5上进行,这样可以减小任务复杂度。不过,我并不是太认可这种映射机制,这种映射只能是点到点的关系,不过我觉得从原图的某个区域R映射到conv5的区域r,应该r对R敏感,换句话说,应该r感受野应该与R有交集。这样子的话,示意图如下:
其中蓝色的为conv的神经元感受野,红色的是原图的某个感兴趣区域,而黑色框我才认为是要映射到conv5的区域。
使用SPP进行检测,先用提候选proposals方法(selective search)选出候选框,不过不像RCNN把每个候选区域给深度网络提特征,而是整张图提一次特征,再把候选框映射到conv5上,因为候选框的大小尺度不同,映射到conv5后仍不同,所以需要再通过SPP层提取到相同维度的特征,再进行分类和回归,后面的思路和方法与RCNN一致。实际上这样子做的话就比原先的快很多了,因为之前RCNN也提出了这个原因就是深度网络所需要的感受野是非常大的,这样子的话需要每次将感兴趣区域放大到网络的尺度才能卷积到conv5层。这样计算量就会很大,而SPP只需要计算一次特征,剩下的只需要在conv5层上操作就可以了。当然即使是这么完美的算法,也是有它的瑕疵的,可能Kaiming He大神太投入 SPP的功效了,使得整个流程框架并没有变得更加完美。首先在训练方面,SPP没有发挥出它的优势,依旧用了传统的训练方法,这使得计算量依旧很大,而且分类和bounding box的回归问题也可以联合学习,使得整体框架更加完美。这些Kaiming He都给忽略了,这样也就有了第二篇神作 Fast RCNN。


Fast RCNN
在我上帝视角(看完整个线)看来,Fast RCNN提出新的东西并不是太多,往往都是别人忽略的东西,实际上也算是对SPP上的捡漏。当然大神能够找到漏可以捡,所以说这并不是贬义,只是我感觉对这篇论文客观的评价。首先fast rcnn说无论是训练还是测试都比RCNN 和SPP快很多倍。其次,自己提出了一个特殊的层RoI,这个实际上是SPP的变种,SPP是pooling成多个固定尺度,而RoI只pooling到一个固定的尺度(6×6)。网络结构与之前的深度分类网络(alex)结构类似,不过把pooling5层换成了RoI层,并把最后一层的Softmax换成两个,一个是对区域的分类Softmax(包括背景),另一个是对bounding box的微调。这个网络有两个输入,一个是整张图片,另一个是候选proposals算法产生的可能proposals的坐标。训练的时候,它指出了SPP训练的不足之处,并提出新的训练方式,就是把同张图片的prososals作为一批进行学习,而proposals的坐标直接映射到conv5层上,这样相当于一个batch一张图片的所以训练样本只卷积了一次。文章提出他们通过这样的训练方式或许存在不收敛的情况,不过实验发现,这种情况并没有发生。这样加快了训练速度。另外,它同时利用了分类的监督信息和回归的监督信息,使得网络训练的更加鲁棒,而且效果更好。值得注意的是,他在回归问题上并没有用很常见的2范数作为回归,而是使用所谓的鲁棒L1范数作为损失函数(可能在其他地方很常见,不过我是第一次见)。实际训练时,一个batch训练两张图片,每张图片训练64个RoIs(Region of Interest),前向反向计算就不说了,如果把pooling的反向计算理解了,这个roi应该不会太难。这篇论文提到了一个让人引发遐想的地方就是它将比较大的全链接层用SVD分解了一下使得检测的时候更加迅速。虽然是别人的工作,但是引过来恰到好处。最后作者写了个类似讨论的板块,并从实验角度说明了多任务对训练是否有帮助?尺度不变性如何实现?是单尺度学习还是多尺度学习?(注意,这里的尺度是对整张图片的resize尺度)得到的结论是多尺度学习能提高一点点map,不过计算量成倍的增加了,故单尺度训练的效果更好。最后在SVM和Softmax的对比实验中说明,SVM的优势并不明显,故直接用Softmax将整个网络整合训练更好。
Faster RCNN详解
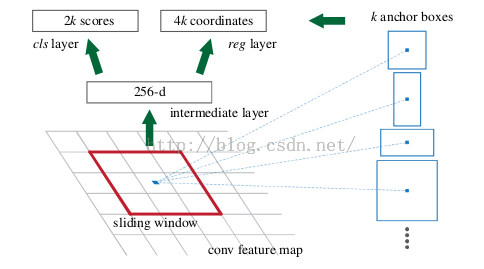
就像之前在RCNN章节提到的创新思路所说,Faster RCNN 将selective search这样的算法整合到深度网络中,这样不光解决了selective search这样的算法是cpu实现,速度慢的问题,而且与深度网络相结合,共享前面的卷积计算,这样做计算效率更高。而其他部分则与Fast RCNN差异不大。故这里主要讲些Region Proposal Networks的设计和训练思路。
上图是RPN的网络流程图,即也是利用了SPP的映射机制,从conv5上进行滑窗来替代从原图滑窗。不过,要如何训练出一个网络来替代selective search相类似的功能呢??实际上思路很简单,就是先通过SPP根据一一对应的点从conv5映射回原图,根据设计不同的固定初始尺度训练一个网络,就是给它大小不同(但设计固定)的region图,然后根据与ground truth的覆盖率给它正负标签,让它学习里面是否有object即可。这就又变成我介绍RCNN之前提出的方法,训练出一个能检测物体的网络,然后对整张图片进行滑窗判断,不过这样子的话由于无法判断region的尺度和scale ratio,故需要多次放缩,这样子测试,估计判断一张图片是否有物体就需要n久。如何降低这一部分的复杂度??要知道我们只需要找出大致的地方,无论是精确定位位置还是尺寸,后面的工作都可以完成,这样子的话,与其说用小网络,简单的学习(这样子估计和蒙差不多了,反正有无物体也就50%的概率),还不如用深的网络,固定尺度变化,固定scale ratio变化,固定采样方式(反正后面的工作能进行调整,更何况它本身就可以对box的位置进行调整)这样子来降低任务复杂度呢。这里有个很不错的地方就是在前面可以共享卷积计算结果,这也算是用深度网络的另一个原因吧。而这三个固定,我估计也就是为什么文章叫这些proposal为anchor的原因了。这个网络的结果就是卷积层的每个点都有有关于k个achor boxes的输出,包括是不是物体,调整box相应的位置。这相当于给了比较死的初始位置(三个固定),然后来大致判断是否是物体以及所对应的位置,这样子的话RPN所要做的也就完成了,这个网络也就完成了它应该完成的使命,剩下的交给其他部分完成就好了。
以上就是我对object detection的RCNN,Fast RCNN, Faster RCNN的整个理解,写的比较仓促,而且是读完整条线的论文才决定写这篇博客的,故有很多是回忆的,却又懒得再向文章确认,不过之后的博客会边读边写。
我这也是第一次写博客,如果有理解不对的地方或者逻辑上有不对的地方,请大家指出来,纠正我的错误。