对redis了解比价浅,有错误之处请批评指正。
场景:某服务查询余额功能,根据用户id查询余额,如果该用户在缓存中有余额,则直接返回缓存数据,如果没有,则去数据库查询后返回并放入缓存;
黑客采用ddos攻击对网站进行饱和攻击,用uuid生成用户账号进行查询,由于随机的uuid不是系统用户,也就在缓存中无数据,导致每次查询都是访问数据库,直接占用了所有数据库连接;uuid不断变化,无法进行固定拦截;如果将系统用户全部取出进行比对,这个思路,我能想到的就是hashmap了,但hashmap默认加载因子是0.75,加上其数据所占的长度,空间利用率并不高,又因为数据量较大,会有查找较慢的问题;
那有没有什么办法既占内存少,速度又快呢?有,bloom过滤器!
什么是Bloom Filter
参照:
概括来说,就是一个数组跟一组函数,数组的长度跟函数的多少都要跟误判率一起经过算法确认,然后:
1、先让符合条件的数据进行填充,每条数据会被映射到数组的多个不同位置,将这些位置的数字由0改为1;
2、多次重复后,该数组某些地方为1,某些地方为0;
3、对于需要过滤的数据,用mightContain方法进行判断,如果该数据所映射到数组上的所有点均为1,则通过验证,否则不通过。
PS:Bloom Filter可以手动设置误判率,误判率必须大于0;
-------------------------------------------------------------------
Bloom Filter的实现,伟大的Google已经为我们准备好了,guava18以上版本包含此过滤器。
<dependency> <groupId>com.google.guava</groupId> <artifactId>guava</artifactId> <version>19.0</version> </dependency>
Bloom Filter测试代码:
@Test
public void bloomTest(){
final int num = 100000;
//初始化一个存储string数据的bloom过滤器,初始化大小10w
BloomFilter<String> bf = BloomFilter.create(Funnels.stringFunnel(Charsets.UTF_8),num,0.001);
Set<String> sets = new HashSet<>(num);
List<String> lists = new ArrayList<String>(num);
//向3个容器初始化10w随机唯一字符串
for(int i=0;i<num;i++){
String uuid = UUID.randomUUID().toString();
bf.put(uuid);
sets.add(uuid);
lists.add(uuid);
}
int wrong = 0;
int right = 0;
for(int i=0;i<10000;i++){
String test = i%100 == 0? lists.get(i/100):UUID.randomUUID().toString();
if(bf.mightContain(test)){
if(sets.contains(test)){
right ++;
}else{
wrong ++;
}
}
}
System.out.println("=============right================"+right);
System.out.println("=============wrong================"+wrong);
}
输出结果:
=============right================100
=============wrong================276
多运行几次,wrong的值大概在300左右变化,right一直为100。原因是对于的确在其中的数据,由于过滤器初始化的时候就采用的这些数据,所以对应的位置必定全部为1,不会误判;但对于新数据,不一定全部不是1,所以存在误判率;而误判率默认为3%,因此,1w条数据误判大概为300。我们调整误判率,代码改为:
BloomFilter<String> bf = BloomFilter.create(Funnels.stringFunnel(Charsets.UTF_8),num,0.001);
会发现wrong的数值在10上下波动,因为1w的千分之一正好是10。
-------------------------------------------------------------------
以下我们使用Bloom Filter拦截非法请求:
测试代码,模拟2000请求同时访问:
int num = 2000; //倒数计数器 CountDownLatch cdl = new CountDownLatch(num);
@Test
public void testConcurrent() throws InterruptedException {
System.out.println("执行开始啦");
long start = System.currentTimeMillis();
//真实数据
List<String> unames = dbService.getAllUsers();
for(int i=0;i<num;i++){
String username = null;
if(i%50==0){
username = unames.get((int)(Math.random()*unames.size()));
}else{
username = UUID.randomUUID().toString();
}
Thread t = new MyThread(username);
t.start();
cdl.countDown();
}
Thread.sleep(10000);
}
MyThread代码:
private class MyThread extends Thread{
private String name;
public MyThread(String name){
this.name = name;
}
@Override
public void run() {
try {
cdl.await();
} catch (InterruptedException e) {
e.printStackTrace();
}
dbService.getSumScore(name);
}
}
dbService.getSumScore(name)的代码如下:
//获取总成绩
public int getSumScore(String uname){
//不在用户列表,直接返回
if(!bloomFilter.mightContain(uname)){
System.out.println("================不在列表,直接返回=======================");
return 0;
}
//可能在用户列表,进行正常数据查询
int sumscore = 0;
ValueOperations<String, String> operations = redisTemplate.opsForValue();
String result = operations.get("uname");
if(result != null){//缓存已有数据
int order = count.incrementAndGet();
System.out.println(uname+"================获取数据来源:redis======================="+order);
return Integer.valueOf(result);
}else{//缓存无数据
Map m = jdbcTemplate.queryForMap("select sum(score) as sumscore from student where name=?",new Object[]{uname});
if(m != null){
int order = count.incrementAndGet();
System.out.println(uname+"================获取数据来源:database======================="+order);
if(null!=(m.get("sumscore"))){
sumscore = Integer.valueOf(m.get("sumscore")+"");
operations.set(uname,sumscore+"",1);
}
}
return sumscore;
}
}
当然,在service中过滤器是需要初始化的,初始化代码如下:
@PostConstruct
private void init(){
List<String> users = this.getAllUsers();
bloomFilter = BloomFilter.create(Funnels.stringFunnel(Charsets.UTF_8),users.size(),0.001);
for(String str:users){
bloomFilter.put(str);
}
}
输出结果:
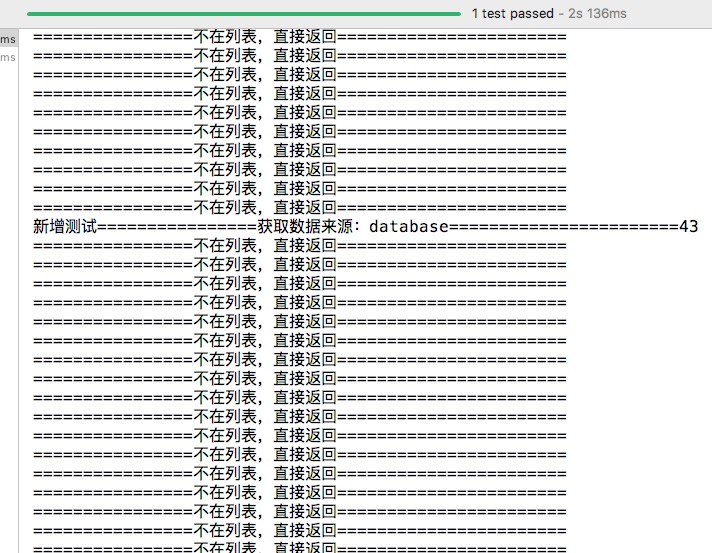
可以看到,大部分的请求都被拦截了。在生产系统中,如果将此功能提出,在访问我们的服务之前先预先对请求进行过滤,那么对于我们的某些接口便能提供很好的保护,有效降低系统被攻击所承受的压力。而且此方法对数据库跟缓存依赖非常小,不用担心对生产系统造成的破坏。