redis干啥的,一般人都知道,但很多人只知道是个缓存数据库,其它的就不知道了,本猿无能亦是如此,然知耻而后勇,我们该理一理这里边的一些逻辑,看看redis究竟是怎么一回事儿,能干啥,怎么做的,这样才能心中有数,用到的时候或者进行技术选型的时候胸有成竹心里不慌,这是一个技术人员应有的自我修养。就从最基本的数据类型开始吧!
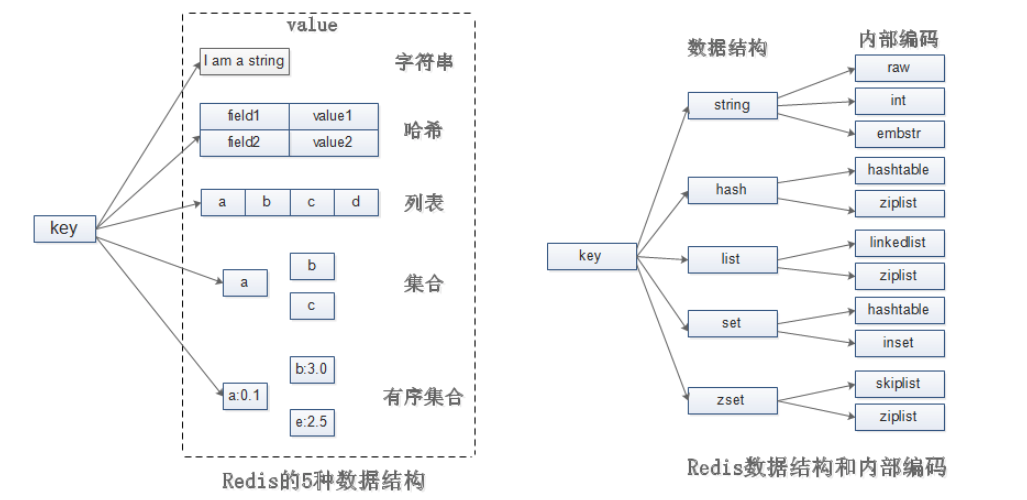
有5种数据类型:string、hash、list、set跟sortedset
但这些只是redis对外的数据结构,实际上每种数据结构都有自己底层的内部编码实现,而且是多种实现,这样redis会在何时的场景选择合适的内部编码。
----------------------------------------------------------------------------------------------------
1、string
java中string底层是一个char[],那redis中是不是也是一个char[]呢?

上图是http://doc.redisfans.com/中的命令列表,如果string的底层是一个char[]的话,那么append操作就要进行扩容,strlen操作就要遍历或者把长度存起来(类似于ArrayList的size),那么整体来说,string应该就是一个char[]的封装。实际的确是类似的。源码解析:http://www.cnblogs.com/huangxincheng/p/4968085.html
内部编码:
int: 8个字节的长整型
embstr: 小于等于39个字节的字符串
raw: 大于39个字节的字符串
redis会根据当前值的类型和长度决定使用哪种内部编码实现。
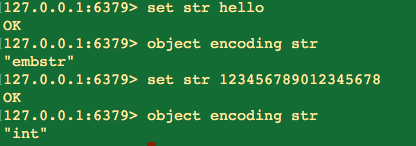
可以看到,在value为纯数字的情况下int可存放的范围是非常广的,千万亿级别的都没问题;而如果是非数字字符,那么直接就是embstr,如果字符长度大于39,那就是raw了。这个raw是个动态字符串,其实就是我们上边说的char[]的封装。
string类型适合用来存储数字或者字符串;对象序列化为字符串后也可以用来存储对象。
注意:字符串最大可存储512M,由于key也是字符串,所以key最大值也是512M。redis的其它数据类型均没有限制对象大小,也就是理论上只要小于物理内存即可;
跟java类比,java中integer最大值2^32=2147483647,这也是数组的最大长度,超过长度编译会报错;,2^32个byte是4G,一个char占2字节,那么java中char[]若按内编码计算,则最大占内存为8G;C语言中char占1个字节,最大512M,那么char[]长度应为integer最大值的1/8也就是2^29(倒着推的,没看源码,可能有误)。
常用操作:
存取跟批量存取:get,set,mget,mset,setnx,setex,getbit,setbit
对字符串的追加,截取:append,getrange,setrange
对数字的加减:incr,incrby,decr,decrby,incrbyfloat
2、hash
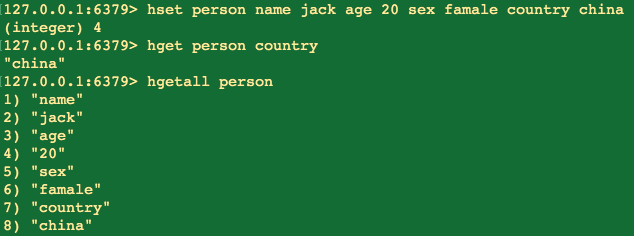
hash适合用来存储对象:
内部编码有2种:
ziplist:压缩列表,有点类似于数组(但不是),内存连续,而且压缩了前驱后驱指针;当hash类型元素个数小于hash-max-zip-entries配置(默认512),同时所有值都小于hash-max-ziplist-value(默认64)时,使用ziplist作为哈希的内部实现。
hashtable:哈希表,不多解释,数组加链表结构。
假设值都满足条件,那么元素个数在512之前都是ziplist实现,查找效率其实是不高的,不过由于内存连续,可以根据结构找到下个元素,遍历起来也还凑合;如果一定要给一个使用ziplist的理由,应该就是redis实在是想尽量省一点内存吧;
两个条件,一旦有一个不达标,就会转为hashtable,数组加链表增删很容易,但略费内存;
当一个hash的编码由ziplist变成hashtable后,即使再替换掉所有值,它也一直会是hashtable类型,变不回来了。
string跟hash哪个更适合存储对象这个问题,可参照http://www.jfinal.com/share/460
同时存取100w条数据,两者耗时接近,string存取快,时间在110-120s,但占用内存比hash多20%左右;hash占用内存少,但耗时在120-140s左右,耗时比string多20%;究其原因,应该是string除了记录数据还要记录对象类型信息,因此消耗空间多,而hash因为要组装对象数据,耗时略长;
常用操作:
存取:hset,hget,hmset,hmget,hgetall,hsetnx
判断是否存在:hexists
3、list
redis的list是简单的字符串列表,按照插入顺序排列;可存放(2^32-1)个元素。
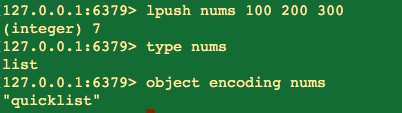
内部编码2种:
ziplist: 跟hash类似,也是两个参数配置,只是名字hash改为了list;
linkedlist:当不满足配置时会转换成linkedlist,顾名思义双向链表,转换会同样跟hash一样,不可逆。
list中保存了head,tail节点以及长度值len,也就是操作头尾以及查看list元素个数,时间复杂度为O(1),恒定的;
ps:redis3.1以及之前的版本,list的操作是以上所述;从redis3.2开始,做了优化,引入了quicklist,以上两个配置作废,默认使用quicklist;官方的对quicklist的解释是a doubly linked list of ziplists,也就是一个由ziplist组成的双向链表。
quicklist方面的解释:http://blog.csdn.net/men_wen/article/details/70229375
list常用的方法:
压入弹出:LPOP,LPUSH,RPOP,RPUSH。从名字看出四个分别是从左边弹出,压入,从右边弹出,压入。也就是两端开口的一个队列。
长度,取值等:llen,lindex,ltrim(删除不在区间的元素)
4、set
redis的set是string类型的无序集合,成员不能重复,底层实现主要是哈希表,最大长度(2^32-1)。
长度限制跟list相同,除了支持增删改查还支持集合交集,并集,补集;
内部编码2种:
intset:当集合中元素都是整数而且元素个上诉小于set-max-intset-entries(默认512)时,redis会选用intset作为集合内部实现;
hashtable:不满足上述情况则采用hashtable,跟hash的情况相比,就是val是null而已,只存了key。

这里要注意的是此处的set跟java中的set略有区别,这里set中的元素都是字符串,而java存放的是对象,这点不太一样;
常用操作,sadd,spop,srem
sadd:添加,sadd fruits pear apple banana tomato grape orange
spop:移除并返回集合中一个随机元素
srem:移除集合中一个或多个元素
5、zset
zset存放的是一个数值跟一个字符串,成员不重复,最大长度跟set一样;
其实我们已经发现,redis的数据类型跟我们直观上认识的java并不一致!
内部编码2种:
ziplist:一样的配置,只是名字改成了zset,默认值128,对value的闲置改成了默认64字节;
skiplist:跳跃表,ziplist条件不满足的时候,使用跳跃表作为内部实现;
默认按key升序排列:
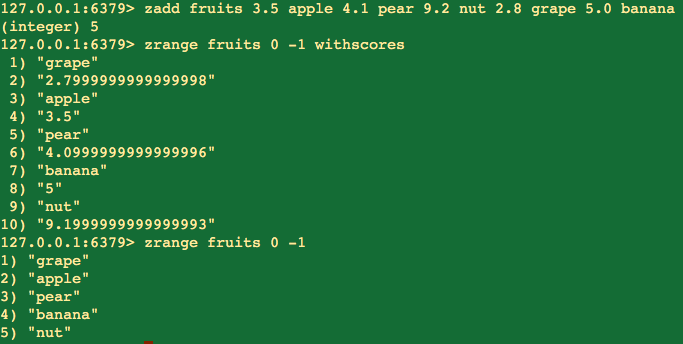
可以看到排列顺序为升序,而且小数有变化
常用操作:
添加删除:zadd,zrem
获取区间数据:zrange,获取排名:zrank,返回值:zscore,值递增:zincrby
集合间操作,子交并补:zunionstore,zinterstore
zset的使用场景:由于支持排序,以及集合的相关操作,所以在关注列表,共同关注人等操作上比较适用。
-------------------------------------
学习redis随手笔记