大家都知道,我们借助python+selenium来驱动chrome等浏览器时,需要有chromedriver的支持。近来,chrome浏览器的主版本号基本保持每月一更新的频次。当我们的chromedriver版本如果落后chrome主版本超过1,则chromedriver会提示版本不兼容,大概显示信息如下:“selenium.common.exceptions.SessionNotCreatedException: Message: session not created: This version of ChromeDriver only supports Chrome version 80”。
解决此问题有两个方法,先来说说治标的方法:早期的chromedriver并不严格校验chrome浏览器的版本,而且面对最新的chrome,它依然够用,毕竟大多数时候我们常用的chrome的api功能都没变过。所以,我们可以使用旧版本chromedriver来规避这个问题,比如ChromeDriver 2.35.528161就不存在这个问题;
接下来小爬重点说说相对治本的方法:我们在脚本中分别获取chromedriver和chrome的版本号,比较其主版本号的差异,触发条件后,自动在chromedriver mirror上下载与chrome相对应版本的chromedriver,解压,替换原chrome driver文件,一气呵成。
chrome的版本,我们一般通过浏览器地址栏输入“chrome://settings/help”来查看:
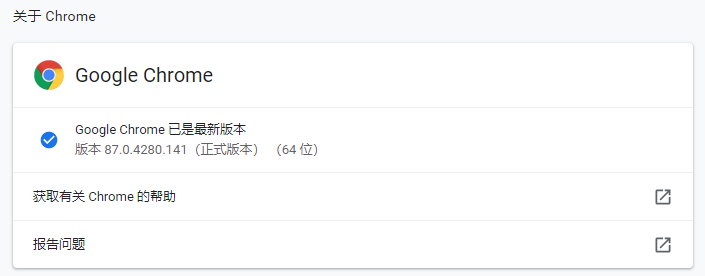
也可以右键chrome.exe文件来查看版本号:
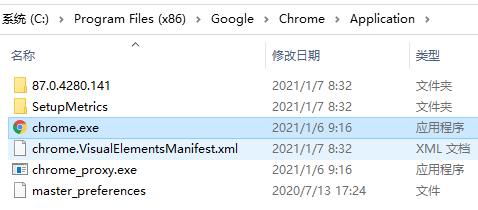

在python的世界里,我们可以这样去读取一个文件(如chrome)的“属性-详细信息-产品版本信息”(需要提前安装pywin32模块),返回值是一个版本号的字符串:“87.0.4280.141”:
from win32com.client import Dispatch allInfo=Dispatch("Scripting.FileSystemObject") version = allInfo.GetFileVersion(r"C:Program Files (x86)GoogleChromeApplicationchrome.exe")
我们也可以通过注册表的方式来获取chrome的版本号:
import winreg def get_Chrome_version(): key = winreg.OpenKey(winreg.HKEY_CURRENT_USER, r'SoftwareGoogleChromeBLBeacon') version, types = winreg.QueryValueEx(key, 'version') return version
接下来,我们在cmd或者powershell里,CD到chromedriver所在目录,可以这样得到版本号:.chromedriver.exe --V ,返回结果大概这样:“ChromeDriver 2.35.528161 (5b82f2d2aae0ca24b877009200ced9065a772e73)”,该字符串按照空格符进行分段,第二段就是我们要的版本信息了。那么在python的世界里,我们又该如何去跟终端交互拿到这个chromedriver版本号呢,其实很简单:
import os def get_version(): '''查询系统内的Chromedriver版本''' outstd2 = os.popen('chromedriver --version').read() return outstd2.split(' ')[1]
有了这些手段,我们还需要定义个方法来自动下载”ChromeDriver Mirror (taobao.org)“上的chromedriver:

下载路径(URL)诸如:“https://cdn.npm.taobao.org/dist/chromedriver/80.0.3987.16/chromedriver_win32.zip”,这用requests库就可以轻松实现这一需求:
import requests def download_driver(download_url): '''下载文件''' file = requests.get(download_url) with open("chromedriver.zip", 'wb') as zip_file: # 保存文件到脚本所在目录 zip_file.write(file.content) print('下载成功')
你也可以指定完整路径,让下载的chromedriver.zip文件放到指定目录。
紧接着,小爬再定义个方法来自动解压zip文件,拿到里面的chromedriver.exe文件,自动覆盖旧版本chrome driver:
import zipfile def unzip_driver(path): '''解压Chromedriver压缩包到指定目录''' f = zipfile.ZipFile("chromedriver.zip",'r') for file in f.namelist(): f.extract(file, path)
小爬将这些功能做成一个py文件,可以import到我们的任何其他相关项目中,完整的示例代码如下:
import requests,winreg,zipfile,re,os url='http://npm.taobao.org/mirrors/chromedriver/' # chromedriver download link
def get_Chrome_version(): key = winreg.OpenKey(winreg.HKEY_CURRENT_USER, r'SoftwareGoogleChromeBLBeacon') version, types = winreg.QueryValueEx(key, 'version') return version def get_latest_version(url): '''查询最新的Chromedriver版本''' rep = requests.get(url).text time_list = [] # 用来存放版本时间 time_version_dict = {} # 用来存放版本与时间对应关系 result = re.compile(r'd.*?/</a>.*?Z').findall(rep) # 匹配文件夹(版本号)和时间 for i in result: time = i[-24:-1] # 提取时间 version = re.compile(r'.*?/').findall(i)[0] # 提取版本号 time_version_dict[time] = version # 构建时间和版本号的对应关系,形成字典 time_list.append(time) # 形成时间列表 latest_version = time_version_dict[max(time_list)][:-1] # 用最大(新)时间去字典中获取最新的版本号 return latest_version
def get_server_chrome_versions(): '''return all versions list''' versionList=[] url="http://npm.taobao.org/mirrors/chromedriver/" rep = requests.get(url).text result = re.compile(r'd.*?/</a>.*?Z').findall(rep) for i in result: # 提取时间 version = re.compile(r'.*?/').findall(i)[0] # 提取版本号 versionList.append(version[:-1]) # 将所有版本存入列表 return versionList def download_driver(download_url): '''下载文件''' file = requests.get(download_url) with open("chromedriver.zip", 'wb') as zip_file: # 保存文件到脚本所在目录 zip_file.write(file.content) print('下载成功') def get_version(): '''查询系统内的Chromedriver版本''' outstd2 = os.popen('chromedriver --version').read() return outstd2.split(' ')[1] def unzip_driver(path): '''解压Chromedriver压缩包到指定目录''' f = zipfile.ZipFile("chromedriver.zip",'r') for file in f.namelist(): f.extract(file, path) def check_update_chromedriver(): chromeVersion=get_Chrome_version() chrome_main_version=int(chromeVersion.split(".")[0]) # chrome主版本号 driverVersion=get_version() driver_main_version=int(driverVersion.split(".")[0]) # chromedriver主版本号 download_url="" if driver_main_version!=chrome_main_version: print("chromedriver版本与chrome浏览器不兼容,更新中>>>") versionList=get_server_chrome_versions() if chromeVersion in versionList: download_url=f"{url}{chromeVersion}/chromedriver_win32.zip" else: for version in versionList: if version.startswith(str(chrome_main_version)): download_url=f"{url}{version}/chromedriver_win32.zip" break if download_url=="": print("暂无法找到与chrome兼容的chromedriver版本,请在http://npm.taobao.org/mirrors/chromedriver/ 核实。") download_driver(download_url=download_url) path = get_path() unzip_driver(path) os.remove("chromedriver.zip") print('更新后的Chromedriver版本为:', get_version()) else: print("chromedriver版本与chrome浏览器相兼容,无需更新chromedriver版本!") if __name__=="__main__": check_update_chromedriver()
有了这套方法,任由你的本地chrome如何更新,我们的项目中的chromedriver总能自动更新,兼容浏览器的版本,可谓是一劳永逸了~~有这类困扰的童鞋,赶紧用上面的方法动手试试吧!