假定:输入是由一个随机过程产生的[0, 1)区间上均匀分布的实数。将区间[0, 1)划分为n个大小相等的子区间(桶),每桶大小1/n:[0, 1/n), [1/n, 2/n), [2/n, 3/n),…,[k/n, (k+1)/n ),…将n个输入元素分配到这些桶中,对桶中元素进行排序,然后依次连接桶输入0 ≤A[1..n] <1辅助数组B[0..n-1]是一指针数组,指向桶(链表)。
算法思想
平均情况下桶排序以线性时间运行。像基数排序一样,桶排序也对输入作了某种假设, 因而运行得很快。具体来说,基数排序假设输入是由一个小范围内的整数构成,而桶排序则 假设输入由一个随机过程产生,该过程将元素一致地分布在区间[0,1)上。
桶排序的思想就是把区间[0,1)划分成n个相同大小的子区间,或称桶,然后将n个输入数分布到各个桶中去。因为输入数均匀分布在[0,1)上,所以一般不会有很多数落在一个桶中的情况。为得到结果,先对各个桶中的数进行排序,然后按次序把各桶中的元素列出来即可。
在桶排序算法的代码中,假设输入是含n个元素的数组A,且每个元素满足0≤ A[i]<1。另外还需要一个辅助数组B[O..n-1]来存放链表实现的桶,并假设可以用某种机制来维护这些表。
桶排序的算法如下(伪代码表示),其中floor(x)是地板函数,表示不超过x的最大整数。
procedure Bin_Sort(var A:List); 桶排序算法begin
n:=length(A);
for i:=1 to n do
将A[i]插到表B[floor(n*A[i])]中;
for i:=0 to n-1 do
用插入排序对表B[i]进行排序;
将表B[0],B[1],...,B[n-1]按顺序合并;
end;
右图演示了桶排序作用于有10个数的输入数组上的操作过程。(a)输入数组A[1..10]。(b)在该算法的第5行后的有序表(桶)数组B[0..9]。桶i中存放了区间[i/10,(i+1)/10]上的值。排序输出由表B[O]、B[1]、...、B[9]的按序并置构成。
要说明这个算法能正确地工作,看两个元素A[i]和A[j]。如果它们落在同一个桶中,则它们在输出序列中有着正确的相对次序,因为它们所在的桶是采用插入排序的。现假设它们落到不同的桶中,设分别为B[i']和B[j']。不失一般性,假设i' i'=floor(n*A[i])≥floor(n*A[j])=j' 得矛盾 (因为i' 现在来分析算法的运行时间。除第5行外,所有各行在最坏情况的时间都是O(n)。第5行中检查所有桶的时间是O(n)。分析中唯一有趣的部分就在于第5行中插人排序所花的时间。
为分析插人排序的时间代价,设ni为表示桶B[i]中元素个数的随机变量。因为插入排序以二次时间运行,故为排序桶B[i]中元素的期望时间为E[O(ni2)]=O(E[ni2]),对各个桶中的所有元素排序的总期望时间为:O(n)。 (1) 为了求这个和式,要确定每个随机变量ni的分布。我们共有n个元素,n个桶。某个元素落到桶B[i]的概率为l/n,因为每个桶对应于区间[0,1)的l/n。这种情况与投球的例子很类似:有n个球 (元素)和n个盒子 (桶),每次投球都是独立的,且以概率p=1/n落到任一桶中。这样,ni=k的概率就服从二项分布B(k;n,p),其期望值为E[ni]=np=1,方差V[ni]=np(1-p)=1-1/n。对任意随机变量X,有右图所示表达式。
(2)将这个界用到(1)式上,得出桶排序中的插人排序的期望运行时间为O(n)。因而,整个桶排序的期望运行时间就是线性的。
时间空间代价分析
桶排序利用函数的映射关系,减少了几乎所有的比较工作。实际上,桶排序的f(k)值的计算,其作用就相当于快排中划分,已经把大量数据分割成了基本有序的数据块(桶)。然后只需要对桶中的少量数据做先进的比较排序即可。
对N个关键字进行桶排序的时间复杂度分为两个部分:
(1) 循环计算每个关键字的桶映射函数,这个时间复杂度是O(N)。
(2) 利用先进的比较排序算法对每个桶内的所有数据进行排序,其时间复杂度为 ∑ O(Ni*logNi) 。其中Ni 为第i个桶的数据量。
很显然,第(2)部分是桶排序性能好坏的决定因素。尽量减少桶内数据的数量是提高效率的唯一办法(因为基于比较排序的最好平均时间复杂度只能达到O(N*logN)了)。因此,我们需要尽量做到下面两点:
(1) 映射函数f(k)能够将N个数据平均的分配到M个桶中,这样每个桶就有[N/M]个数据量。
(2) 尽量的增大桶的数量。极限情况下每个桶只能得到一个数据,这样就完全避开了桶内数据的“比较”排序操作。 当然,做到这一点很不容易,数据量巨大的情况下,f(k)函数会使得桶集合的数量巨大,空间浪费严重。这就是一个时间代价和空间代价的权衡问题了。
对于N个待排数据,M个桶,平均每个桶[N/M]个数据的桶排序平均时间复杂度为:
O(N)+O(M*(N/M)*log(N/M))=O(N+N*(logN-logM))=O(N+N*logN-N*logM)
当N=M时,即极限情况下每个桶只有一个数据时。桶排序的最好效率能够达到O(N)。
总结: 桶排序的平均时间复杂度为线性的O(N+C),其中C=N*(logN-logM)。如果相对于同样的N,桶数量M越大,其效率越高,最好的时间复杂度达到O(N)。当然桶排序的空间复杂度为O(N+M),如果输入数据非常庞大,而桶的数量也非常多,则空间代价无疑是昂贵的。此外,桶排序是稳定的。
创建一个工程
声名如下
#include<iomanip>
#include<stdlib.h>
#include<time.h>
using namespace std;
//欲桶排序的数组长度
const int SIZE=12;
void bucketSort(int []);
void distributeElements(int [],int [][SIZE],int);
void collectElements(int [],int [][SIZE]);
int numberOfDigits(int [],int);
void zeroBucket(int [][SIZE]);
// 桶排序算法
void bucketSort(int a[])
{int totalDigits,bucket[10][SIZE]={0};
totalDigits=numberOfDigits(a,SIZE);
for(int i=1;i<=totalDigits;++i) {
distributeElements(a,bucket,i);
collectElements(a,bucket);
//将桶数组初始化为0
if(i!=totalDigits) zeroBucket(bucket);
for(int j=0;j<SIZE;++j)
cout<<setw(3)<<a[j];
cout<<endl;}
}
//确定单下标数组的最大数的位数
int numberOfDigits(int b[],int arraySize)
{ int largest=b[0],digits=0;
for(int i=1;i<arraySize;++i)
if(b[i]>largest)
largest=b[i];
while(largest!=0) {
++digits;
largest/=10;}
return digits;
}
// 将单下标数组的每个值放到桶数组的行中
void distributeElements(int a[],int buckets[][SIZE],int digit)
{int divisor=10,bucketNumber,elementNumber;
for(int i=1;i<digit;++i)
divisor*=10;
for(int k=0;k<SIZE;++k) {
bucketNumber=(a[k]%divisor-a[k]%(divisor/10))/(divisor/10);
elementNumber=++buckets[bucketNumber][0];
buckets[bucketNumber][elementNumber]=a[k];}
}
//将桶数组的值复制回原数组
void collectElements(int a[],int buckets[][SIZE])
{int subscript=0;
for(int i=0;i<10;++i)
for(int j=1;j<=buckets[i][0];++j)
a[subscript++]=buckets[i][j];
}
//将桶数组初始化为0
void zeroBucket(int buckets[][SIZE])
{for(int i=0;i<10;++i)
for(int j=0;j<SIZE;++j)
buckets[i][j]=0;}
调用如下
void main()
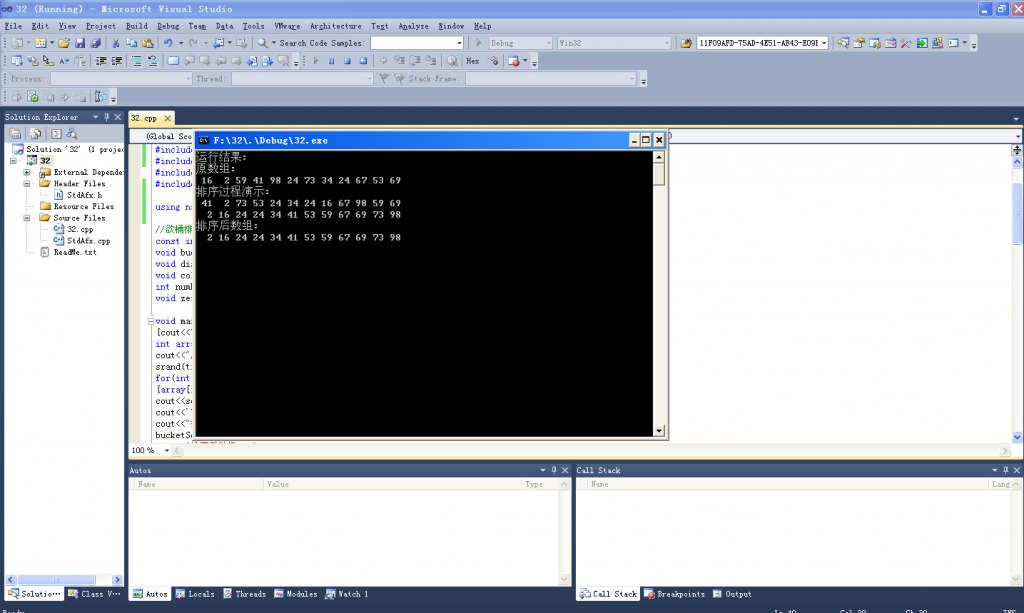
{cout<<"运行结果:\n";
int array[SIZE];
cout<<"原数组:\n";
srand(time(0));
for(int i=0;i<SIZE;++i)
{array[i]=rand()%100;
cout<<setw(3)<<array[i];}
cout<<'\n';
cout<<"排序过程演示:\n";
bucketSort(array);
cout<<"排序后数组:\n";
for(int j=0;j<SIZE;++j)
cout<<setw(3)<<array[j];
cout<<endl;cin.get();
}运行如下
代码下载
http://download.csdn.net/detail/yincheng01/4790020