转:https://www.cnblogs.com/lz3018/p/5932198.html
通用数据结构
可以简单的按照速度将通用数据结构划分为:数组和链表(最慢),树(较快),哈希表(最快)。增、删、改、查是四大常见操作,不过其实可以浓缩为两个操作:增和查。删除操作和和修改操作都是建立在查找操作上的,所以完美的数据结构应该是具有较高的插入效率和查找效率。
通用数据结构关系
可以根据下图选择合适的通用数据结构:
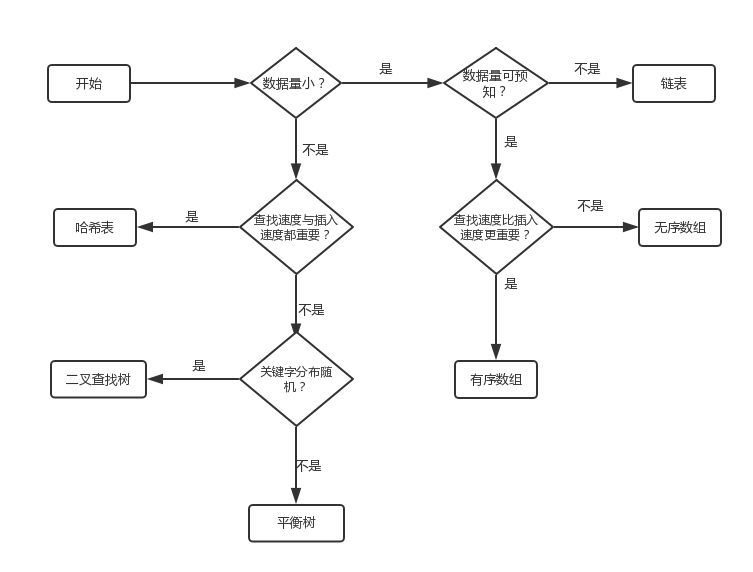
数组
使用场景
数组在以下三个情形下很有用:
1)数据量较小。
2)数据规模已知。
3)随机访问,修改元素值。
如果插入速度很重要,选择无序数组。如果查找速度很重要,选择有序数组,并使用二分查找。
缺点
1)需要预先知道数据规模
2)插入效率低,因为需要移动大量元素。
链表
解决的问题
链表的出现解决了数组的两个问题:
1)需要预先知道数据规模
2)插入效率低
使用场景
1)数据量较小
2)不需要预先知道数据规模
3)适应于频繁的插入操作
缺点
1)有序数组可以通过二分查找方法具有很高的查找效率(O(log n)),而链表只能使用顺序查找,效率低下(O(n))。
二叉查找树
解决的问题
1)有序数组具有较高的查找效率(O(log n)),而链表具有较高的插入效率(头插法,O(1)),结合这两种数据结构,创建一种貌似完美的数据结构,也就是二叉查找树。
使用场景
1)数据是随机分布的
2)数据量较大
3)频繁的查找和插入操作(可以提供O(log n)级的查找、插入和删除操作)
缺点
1)如果处理的数据是有序的(升序/降序),那么构造的二叉查找树就会只有左子树(或右子树),也就是退化为链表,查找效率低下(O(log n))。
平衡树
解决的问题
1)针对二叉查找树可能会退化为链表的情况,提出了平衡树,平衡树要求任意节点的左右两个子树的高度差不超过1,避免退化为链表的情况。
使用场景
1)无论数据分布是否随机都可以提供O(log n)级别的查找、插入和删除效率
2)数据量较大
缺点
1)平衡树的实现过于复杂。
哈希表
解决的问题
同平衡树一样,哈希表也不要求数据分布是否随机,不过哈希表的实现比平衡树要简单得多。
使用场景
1)不需要对最大最小值存取。
2)无论数据分布是否随机,理想情况下(无冲突)可以提供O(1)级别的插入、查找和删除效率。
3)数据量较大
缺点
1)由于是基于数组的,数组(哈希表)创建后难以扩展,使用开放地址法的哈希表在基本被填满时,性能下降的非常严重。
2)不能对最大最小值存取。
通用数据存储结构
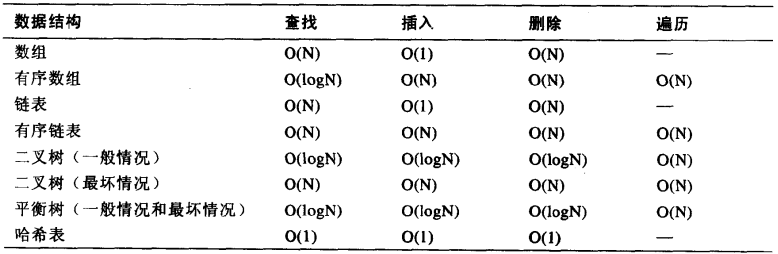
专用数据结构
栈
顺序栈
优点
1)在输入数据量可预知的情形下,可以使用数组实现栈,并且数组实现的栈效率更高,出栈和入栈操作都在数组末尾完成。
缺点
1)如果对数组大小创建不当,可能会产生栈溢出的情况
链栈
优点
1)不会发生栈溢出的情况
2)输入数据量未知时,使用链栈。通过头插法实现入栈操作,头删法实现出栈操作。出栈和入栈均是O(1)。
缺点
1)由于入栈时,首先要创建插入的节点,要向操作系统申请内存,所以链栈没有顺序栈效率高。
队列
如果数据量已知就使用数组实现队列,未知的话就使用链表实现队列。出队和入队均是O(1)。