一、双链表结构
最近总会抽出一些零碎的时间片段,尝试按照自己的想法自定一了一个双链表结构的集合。我发现,数组、单链表或者双链表,乃至其他结构,本质上就是一种思想,只要遵循结构的核心思想,实现方法会有很多种。数组和单链表就不多说了,前几篇也尝试自定义了,就双链表来说,就可以定义如下几种结构:
(1)头结点+...数据结点.....+尾结点
(2)头结点+...数据结点.....
(3)头结点+...数据结点.....头结点
(4)头结点+...数据结点.....+尾结点....头结点
(5)其他结构
本篇使用的是第(1)中结构,结构千千万,效率差异也很大,只要明白双链表的含义:
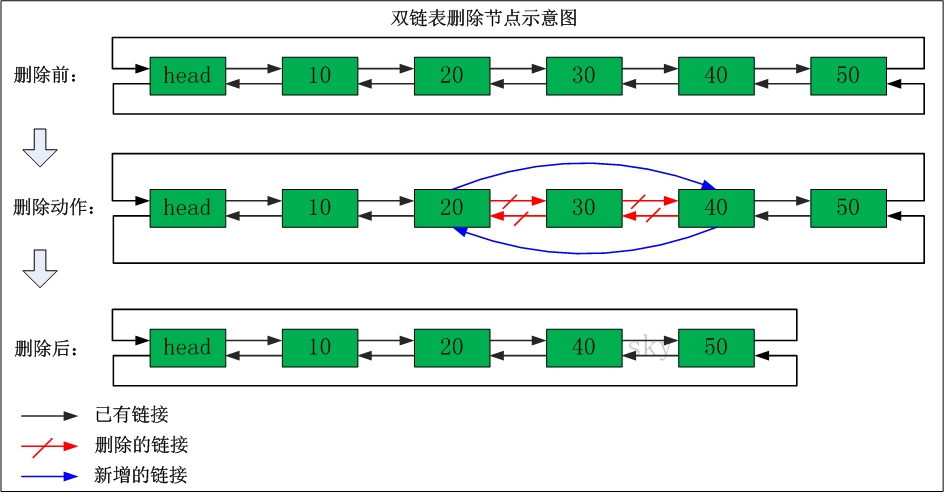
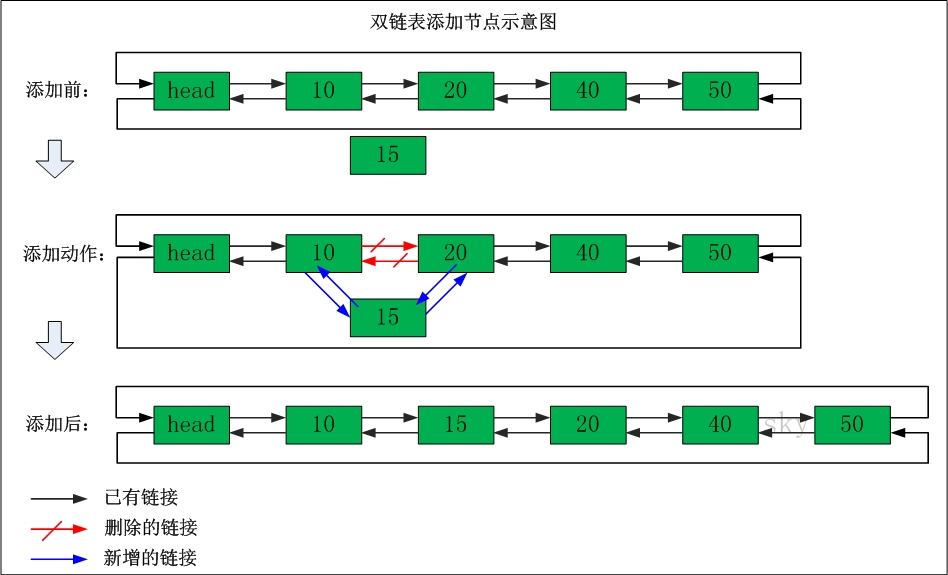
(从网上找到了几张图,也算很清晰,如下)
双链表结构:结构(3)

如何删除一个结点
如何新增一个结点
接下来,我就直接贴出双链表-结构(1)的源码了哈!
二、双链表:MyDoubleLinkedDefin源码
双链表类:MyDoubleLinkedDefin.java
1 package com.xfwl.algorithmAnalysis.linklsit; 2 /** 3 * 数据结构学习-双链表 4 * @function 自定义一个双链表 5 * @author 小风微凉 6 * @time 2018-5-14 下午1:11:11 7 */ 8 public class MyDoubleLinkedDefin<T> { 9 /** 10 * 当前双链表的头结点 11 */ 12 private Node head; 13 /** 14 * 当前双链表的尾部结点 15 */ 16 private Node bottom; 17 /** 18 * 当前链表的数据变化计数 19 */ 20 private int modCount; 21 /** 22 * 当前链表中的结点个数(排除首尾这2个结点) 23 */ 24 private int nodeCount; 25 /** 26 * 内置一个满足双链表的结点类 27 */ 28 private class Node<T>{ 29 /** 30 * 当前结点存放的数据域 31 */ 32 public T data; 33 /** 34 * 当前结点的前驱结点的引用域 35 */ 36 public Node<T> prev; 37 /** 38 * 当前结点的后驱结点的引用域 39 */ 40 public Node<T> next; 41 /** 42 * 结点构造器 43 */ 44 @SuppressWarnings("unchecked") 45 public Node(T data,Node prev,Node next){ 46 this.data=data; 47 this.prev=prev; 48 this.next=next; 49 } 50 } 51 /** 52 * 构造器 53 */ 54 @SuppressWarnings("unchecked") 55 public MyDoubleLinkedDefin(){ 56 //初始化计数 57 modCount=0; 58 nodeCount=0; 59 //初始化头结点和尾结点 60 head=new Node<T>(null,null,null); 61 bottom=new Node<T>(null,null,null); 62 //清空双链表的数据:重置头尾结点的关联关系 63 this.reset(); 64 System.out.println("头结点:"+head); 65 System.out.println("尾结点:"+bottom); 66 } 67 /** 68 * 重置双链表,重置头结点,尾结点 69 */ 70 @SuppressWarnings("unchecked") 71 private void reset(){ 72 //重置头结点 73 this.head.data=null; 74 this.head.prev=null; 75 this.head.next=bottom; 76 //重置尾结点 77 this.bottom.data=null; 78 this.bottom.next=null; 79 this.bottom.prev=head; 80 } 81 /** 82 * 向双链表中添加一个新的结点(追加到尾部) 83 * @param data 84 */ 85 public void add(T data){ 86 //判断当前数据的合法性 87 if(data==null){ 88 throw new IllegalArgumentException("添加的参数不合法!"); 89 } 90 //添加规则:添加当前结点到尾部结点的前驱结点 91 Node curNode=new Node(data,this.bottom.prev,this.bottom); 92 curNode.prev.next=curNode; 93 this.bottom.prev=curNode; 94 //计数++ 95 modCount++; 96 nodeCount++; 97 System.out.println("新加结点的前驱结点:"+curNode.prev); 98 System.out.println("新加结点的后驱结点:"+curNode.next); 99 } 100 /** 101 * 向双链表中的指定索引位置添加一个新的结点 102 * @param index 位置索引值 103 * @param data 结点数据域存储的值 104 * 分析说明: 105 * 链表和数组的结构明显存在差异,数组很容易根据索引下标的值找到指定位置的元素,但是链表却不可以, 106 * 结构使然,所以只能从头结点,或者尾部结点开始向下或向上找到指定位置的元素。 107 * 这里我提出一个想法,能不能在双链表中再维护一个数组,这个数组用于查找指定位置的元素,而链表结构用于 108 * 新增,删除,修改元素!不过这也存在一个很明显的弊端,那就是,为了保证数组和链表结构中得数据统一性,这有 109 * 增加了复杂度,降低了程序的运行效率。显然有点不合理! 110 */ 111 public void add(int index,T data){ 112 //检测位置索引的合法性:也可抽成公共一个方法 113 if(index<0 || index>= this.nodeCount){ 114 throw new IllegalArgumentException("位置索引值不在合理范围内!"); 115 } 116 //创建一个新结点 117 Node newNode=new Node(data,null,null); 118 //找到要插入位置的结点 119 Node tmpNode=this.findNode(index); 120 //开始移动 121 try{ 122 tmpNode.prev.next=newNode; 123 newNode.prev=newNode; 124 newNode.next=tmpNode; 125 tmpNode.prev=newNode; 126 }catch(Exception e){ 127 e.printStackTrace(); 128 throw e; 129 }finally{ 130 //计数++ 131 modCount++; 132 nodeCount++; 133 } 134 } 135 /** 136 * 从双链表中移除指定索引位置的结点 137 * @param index 索引位置 138 */ 139 public void remove(int index){ 140 //检测位置索引的合法性:也可抽成公共一个方法 141 if(index<0 || index>= this.nodeCount){ 142 throw new IllegalArgumentException("位置索引值不在合理范围内!"); 143 } 144 //找到指定位置的结点 145 Node<T> tmpNode=this.findNode(index); 146 //处理结点 147 tmpNode.prev.next=tmpNode.next; 148 tmpNode.next.prev=tmpNode.prev; 149 //计数++ 150 modCount--; 151 nodeCount--; 152 } 153 /** 154 * 获取当前链表的尺寸大小 155 * @return 156 */ 157 public int size(){ 158 return this.nodeCount; 159 } 160 /** 161 * 打印双链表 162 */ 163 public void print(){ 164 if(this.nodeCount==0){ 165 System.out.println("当前双链表没有任何数据!"); 166 }else{ 167 Node tmpNode=head; 168 int count=0; 169 System.out.println("**************开始打印***************************"); 170 while(tmpNode.next!=null){ 171 tmpNode=tmpNode.next; 172 if(count==this.nodeCount){//过滤尾结点 173 break; 174 } 175 System.out.println("索引值:"+count+",结点数据:"+tmpNode.data); 176 count++; 177 } 178 System.out.println("***************打印结束**************************"); 179 } 180 } 181 /** 182 * 找到双链表中指定位置的结点(先折半后再查找) 183 * @param index 指定的位置索引值 184 * @return 返回位置上的结点 185 */ 186 public Node<T> findNode(int index){ 187 //检测位置索引的合法性 188 if(index<0 || index>= this.nodeCount){ 189 throw new IllegalArgumentException("位置索引值不在合理范围内!"); 190 } 191 //取链表一半的数量(计算的是索引值范围) 192 int midCount=(this.nodeCount)/2; 193 //计数起点 194 int count=0; 195 //拿到第一个结点数据 196 Node tmp=head.next; 197 //如果在前一半范围:[0,midCount] 198 if(index>=0 && index<=midCount){ 199 while(index!=count){//要找的位置!=计数位置 一直累计叠加到相等位置 200 tmp=tmp.next; 201 count++; 202 } 203 }else if(index>midCount && index<this.nodeCount){//如果在后一半范围内:[midCount,this.nodeCount) 204 //计数起点调高 205 count=this.nodeCount-1; 206 //从尾结点向前推 207 tmp=bottom.prev; 208 while(index!=count){//要找的位置!=计数位置 一直累计叠加到相等位置 209 tmp=tmp.prev; 210 count--; 211 } 212 } 213 return tmp; 214 } 215 /** 216 * 找到双链表中的指定结点所在的位置 217 * @param node 要检索的结点对象 218 * @return 返回位置索引值 219 * 优化意见: 220 * 这里的实现方法很中规中矩,可以优先判断当前检索的结点是否是头尾结点,过滤常用的检索情况。 221 */ 222 public int findNodeIndex(Node node){ 223 int index=0; 224 //拿到头结点 225 Node tmp=head; 226 while(tmp.next!=null){ 227 tmp=tmp.next; 228 index++; 229 } 230 return index; 231 } 232 }
测试运行类:Test2.java
1 package com.xfwl.algorithmAnalysis.linklsit; 2 /** 3 * 双链表学习测试: 4 * @function 5 * @author 小风微凉 6 * @time 2018-5-17 下午7:06:16 7 */ 8 public class Test2 { 9 /** 10 * 开始测试 11 * @param args 12 */ 13 public static void main(String[] args) { 14 MyDoubleLinkedDefin<Object> myList=new MyDoubleLinkedDefin<>(); 15 //按照顺序加入结点 16 myList.add("第1个结点"); 17 myList.add("第2个结点"); 18 myList.add("第3个结点"); 19 myList.add("第4个结点"); 20 myList.add("第5个结点"); 21 myList.print(); 22 //在第三个索引值上插入一个结点 23 myList.add(4,"第6个结点"); 24 myList.print(); 25 //移除一个结点 26 System.out.println("--------remove测试---------"); 27 for(int i=0;i<6;i++){ 28 myList.remove(0); 29 myList.print(); 30 } 31 } 32 }
运行结果:
头结点:com.xfwl.algorithmAnalysis.linklsit.MyDoubleLinkedDefin$Node@6504e3b2 尾结点:com.xfwl.algorithmAnalysis.linklsit.MyDoubleLinkedDefin$Node@515f550a 新加结点的前驱结点:com.xfwl.algorithmAnalysis.linklsit.MyDoubleLinkedDefin$Node@6504e3b2 新加结点的后驱结点:com.xfwl.algorithmAnalysis.linklsit.MyDoubleLinkedDefin$Node@515f550a 新加结点的前驱结点:com.xfwl.algorithmAnalysis.linklsit.MyDoubleLinkedDefin$Node@626b2d4a 新加结点的后驱结点:com.xfwl.algorithmAnalysis.linklsit.MyDoubleLinkedDefin$Node@515f550a 新加结点的前驱结点:com.xfwl.algorithmAnalysis.linklsit.MyDoubleLinkedDefin$Node@5e91993f 新加结点的后驱结点:com.xfwl.algorithmAnalysis.linklsit.MyDoubleLinkedDefin$Node@515f550a 新加结点的前驱结点:com.xfwl.algorithmAnalysis.linklsit.MyDoubleLinkedDefin$Node@1c4af82c 新加结点的后驱结点:com.xfwl.algorithmAnalysis.linklsit.MyDoubleLinkedDefin$Node@515f550a 新加结点的前驱结点:com.xfwl.algorithmAnalysis.linklsit.MyDoubleLinkedDefin$Node@379619aa 新加结点的后驱结点:com.xfwl.algorithmAnalysis.linklsit.MyDoubleLinkedDefin$Node@515f550a **************开始打印*************************** 索引值:0,结点数据:第1个结点 索引值:1,结点数据:第2个结点 索引值:2,结点数据:第3个结点 索引值:3,结点数据:第4个结点 索引值:4,结点数据:第5个结点 ***************打印结束************************** **************开始打印*************************** 索引值:0,结点数据:第1个结点 索引值:1,结点数据:第2个结点 索引值:2,结点数据:第3个结点 索引值:3,结点数据:第4个结点 索引值:4,结点数据:第6个结点 索引值:5,结点数据:第5个结点 ***************打印结束************************** --------remove测试--------- **************开始打印*************************** 索引值:0,结点数据:第2个结点 索引值:1,结点数据:第3个结点 索引值:2,结点数据:第4个结点 索引值:3,结点数据:第6个结点 索引值:4,结点数据:第5个结点 ***************打印结束************************** **************开始打印*************************** 索引值:0,结点数据:第3个结点 索引值:1,结点数据:第4个结点 索引值:2,结点数据:第6个结点 索引值:3,结点数据:第5个结点 ***************打印结束************************** **************开始打印*************************** 索引值:0,结点数据:第4个结点 索引值:1,结点数据:第6个结点 索引值:2,结点数据:第5个结点 ***************打印结束************************** **************开始打印*************************** 索引值:0,结点数据:第6个结点 索引值:1,结点数据:第5个结点 ***************打印结束************************** **************开始打印*************************** 索引值:0,结点数据:第5个结点 ***************打印结束************************** 当前双链表没有任何数据!
自认为代码注释的还算仔细的哈,如有不足,不吝指正!