聚簇索引
数据和索引存储到一起,找到索引就获取到了数据。聚簇索引是唯一的,InnoDB一定会有一个聚簇索引来保存数据。非聚簇索引一定存储有聚簇索引的列值;
InnoDB聚簇索引选择顺序:
- 默认选择主键
- 没有主机,选择唯一的非空索引;
- 都没有,则隐式定义一个主键;
非聚簇索引
数据存储和索引分开,叶子节点存储对应的行,需要二次查找,通常称为[二级索引]或[辅助索引];
检索过程
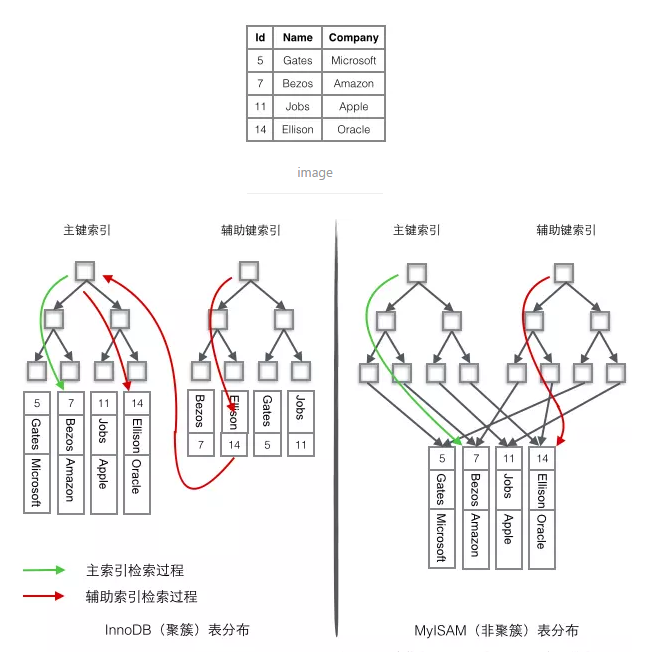
InnoDB:
1、通过id=7查询,直接可以取到数据;
2、如果通过name查询,需先找到id=14,然后再通过id查询;
MyISAM:
辅助索引可以通过辅助键直接找到数据地址,不用再访问主键;
聚集索引与非聚集索引的区别?
1、聚集索引(一般为主键)数据行的物理顺序和列值逻辑顺序相同,一个表只能拥有一个聚集索引,可以有多个非聚集索引;
2、使用非聚集索引查询,没有完整的数据还得进行二次查询,会影响查询性能;
3、聚集索引查询效率更高,但由于要移动对应数据的物理位置,写入性能并不高;
为什么在主键上创建聚集索引比创建非聚集索引要慢?
由于主键的唯一性约束,在插入数据时要保证不能重复。聚集索引由于索引叶节点就是数据页,要检查数据唯一性就得遍历所有数据节点。而非聚集索引上已经包含了主键值,所以查找主键唯一性就只需要遍历所有索引页就可以了。