常用策略有“求留余数法”和“一致性HASH算法”
redis存储的是key,value键值对
一、求留余数法
使用HASH表数据长度对HASHCODE求余数,余数作为索引,使用该余数,直接设置或访问缓存。
计算key的HashCode
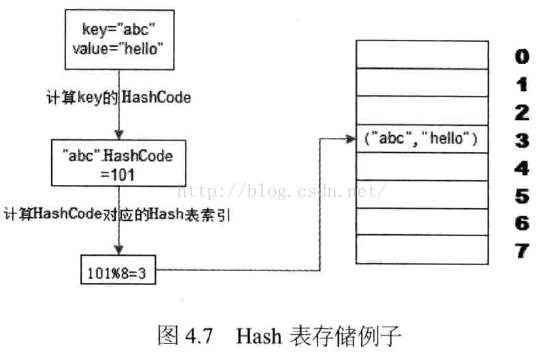
缺点:增加服务器,由于除数不一样了,之前缓存的数据都没办法访问了,即不支持热部署【扩展】
二、一致性HASH算法
一致性HASH算法通过一个叫做一致性HASH环的数据结构,实现KEY到缓存服务器的HASH映射。
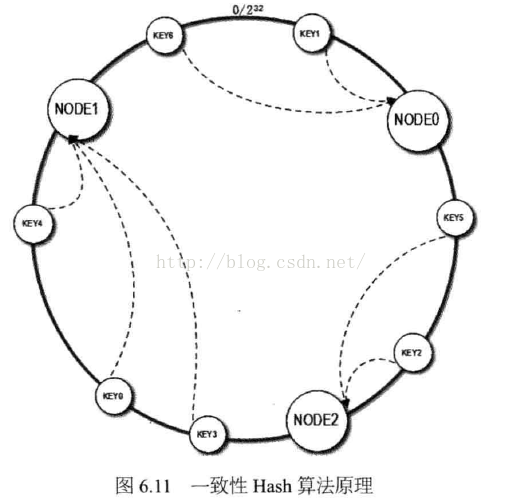
算法过程如下:
先构造一个0到232的整数环,然后将服务器节点的Hash值,放在该环上(可以理解为将你的ip做hash,将ip的HashCode放在环上)。然后根据需要缓存的数据的Key,计算Key的HashCode,然后在环上,顺时针查找距离这个Key的Hash值最近的缓存服务器的节点,然后将Value,存储到该服务器节点上。
这是当缓存服务器集群需要扩容的时候,只需要将新加入的节点的HashCode,放入一致性Hash环中,由于Key是顺时针查找距离最近的节点,因此,新加入的节点只影响整个环中的一小段。
请参见上图,如果我们新加入的服务器节点Node3,在Node1和Node2之间,如下图:
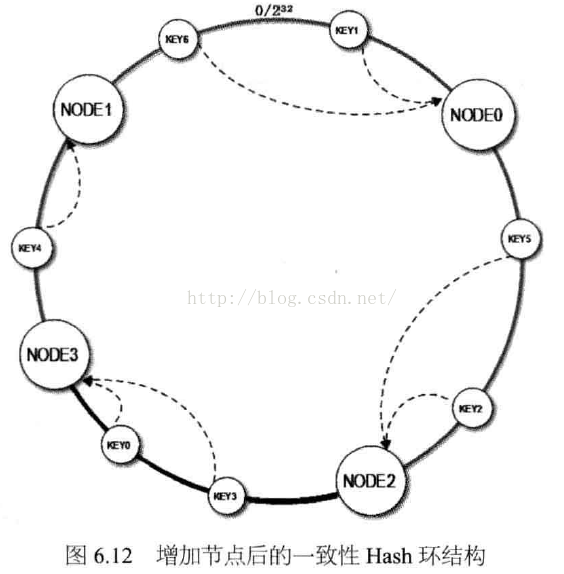
那么受影响的区域,只是Node2到Node3之间(顺时针)的缓存,此区间的缓存数据,加入节点之前是缓存在Node1上的,现在需要重新缓存到Node3上面。
具体应用中,这个长度为232的整数环,通常使用二叉查找树实现,Hash查找过程实际上是在二叉树中查找不小于查找树的最小值。当然,这个二叉树的最右边的叶子节点和最左边的叶子节点相连接,构成环。
通过上面的一致性Hash算法,就解决了分布式缓存集群中扩容的问题。然而上面的方法,仍然有问题。我们已经说过,上面的架构,只影响了Node2到Node3之间的区域(顺时针),那么Node3,也只是分摊了Node1节点的压力,而Node0和Node2的访问压力,并没有变化。也就是说:我们加入了硬件投入,却起到了很小的效果。
一致性Hash算法的进化版
所以说,我们还需要对上面的做法,进行改进。
上述问题是,一致性Hash算法带来的负载均衡不均衡。我们可以通过增加虚拟层来实现。
我们将每台缓存服务器,虚拟为一组虚拟缓存服务器,将虚拟服务器的Hash值,放置在Hash环上,Key在环上先找到虚拟服务器节点,再得到物理服务器的信息。
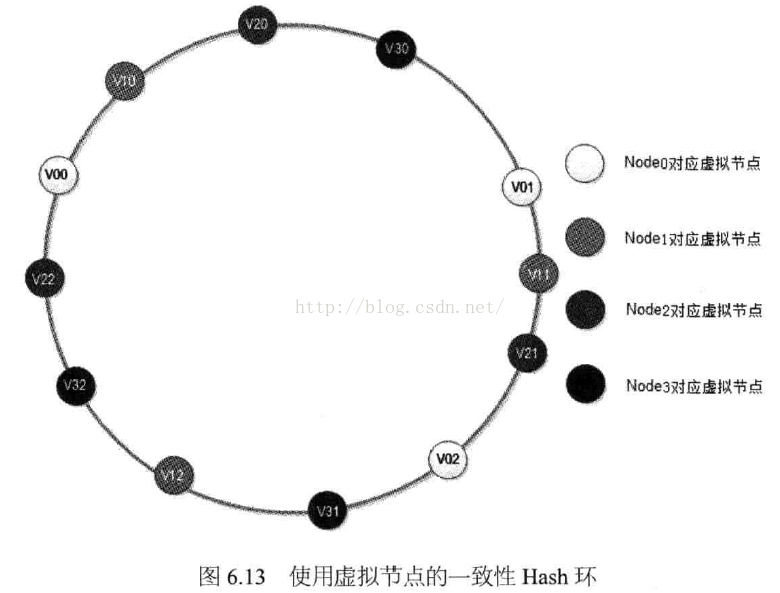
这样,一台服务器节点,被环中多个虚拟节点所代表,且多个节点均匀分配。很显然,每个物理节点对应的虚拟节点越多,各个物理节点之间的负载越均衡,新加入物理服务器对原有的物理服务器的影响越保持一致。