0303-利用手写数字问题引入深度神经网络
pytorch完整教程目录:https://www.cnblogs.com/nickchen121/p/14662511.html
一、引言
为什么要添加这一篇文章呢?上一篇文章我们已经马马虎虎的利用了深度学习的神经网络架构,但只是一层的,大家一定很好去理解他。但是如果我们直接使用torch实现一个多层网络架构的模型,那么对于很多同学来说,一定是迷迷糊糊,心里面草泥马飞过的。
为此,我们通过手写数字这个问题来引入深度神经网络模型的架构,并且在未来利用torch实现手写数字问题的时候穿插对torch基本语法的介绍,让大家能够在应用实践中学习torch的一些枯燥乏味的基本语法。
二、手写数字问题介绍
2.1 MNIST数据集介绍
在MNIST数据集中总共有7000张图片,10个类别,训练集和测试集的比例分别为6000和1000。
由于图片是灰度图片,每张图片的矩阵表示是[28, 28, 1],但在接下来的操作中会对每张图片进行扁平化处理,即每张图片的表示将为[784]
2.2 输入
对于输入,由于对图片做了扁平化处理,输入的x将为一个[b,784]的矩阵,其中b表示图片的张数。
2.3 输出
由于此次任务是分类任务,假设我们使用离散值去表示结果,比如1-2为“飞机”,2-3为“狗”,3-4为“猫”,这样看起来貌似没有问题,但是1-2,2-3,3-4之间是有一个顺序的,这样会让我们构建的模型认为我们的结果是有先后顺序的,因此我们不能和线性回归一样使用一个离散值去表示结果。
在这里,推荐使用一个机器学习中常用的独热编码(one-hot)作为分类的结果。具体是什么意思呢?假设我们的数据总共有三个分类——狗、猫、虎,那么狗可以表示为[1,0,0];猫表示为[0,1,0];虎表示为[0,0,1],这样表示的话,我们就很好的解释了离散值带来的顺序问题。
独热编码虽然很好,但是我们可以看到独热编码中非0即1,这样有时候不利于后期我们进行其他的处理,因此我们还可以对结果进行归一化处理,即对于上述这个例子,我们对结果归一化,也就是模型预测的结果可能是[0.1,0.2,0.7],从上面可以发现,归一化就是把分类结果变成和为1,且每个值在0-1之间。针对[0.1,0.2,0.7],我们可以理所应当的认为预测结果是“虎”,同时我们可以得出预测结果是猫和狗的概率,通过这种概率我们可以进行一定的误差计算。
三、回归和分类模型的区别
在上一篇文章中,我们介绍了回归模型无非就是找到一个函数(f=wx+b),通过梯度下降算法得到位置变量w和b的值,进而通过输入一个x,得到一个预测值(hat{y})。
但是分类模型和回归模型区别还是有的,因为通过回归模型,我们可以看到回归模型能够很好的预测离散值的结果,针对结果为非离散值的分类问题,就有点捉襟见肘了。
为此,我们在回归模型的基础上做一点小小的改动,由于我们上面说到手写数字识别的数据是一个矩阵,由此我们可以让回归模型的函数变成如下函数(f=relu(X@W+B)quad ext{其中@表示矩阵乘法})。很多同学可能对relu有很大的好奇,这是什么呢?relu其实是一个激活函数,类似于sgn函数、sigimoid函数,他们的作用就是针对(X@W+B)的结果,做一个激活处理,无论这个结果值多大或者多小,都将压缩在0-1之间,这样我们就可以实现上一节输出内容讲到的那种处理。
如果分类模型得到一个矩阵,我们只要对它做一个argmax处理,即求出矩阵中最大元素的索引既可以得出这个模型对输入的预测结果。
四、深度模型隐藏层的来源
4.1 激活函数深度讲解
在此,我再强调一遍,pytorch教程的分享,默认你拥有了我前几章讲过的许多基础,如果你有哪些内容听不明白,请去补基础。
上面说到了分类模型无非就是在回归模型上使用了一个激活函数而已,但是为什么要加这个激活函数呢?激活函数有什么作用呢?现在我给大家稍微解惑。
在这里我们继续回到回归模型的构造,我们可以发现回归模型的构造是通过一个线性函数构造出来的,如果你有一个较好的数学底子,可以发现无论多少个线性函数无论怎么叠加,叠加的结果始终都是另外一个线性函数。
对于图片分类这个问题,如果单纯的使用线性函数(f=X@W+B)去解决,那是是非常困难,甚至是很难做到的。为此科学家们想到了使用非线性函数去解决这个问题,那么问题来了,该使用哪个非线性函数呢?为此,有人发明了一个办法,对,就是激活函数,在线性函数上面套一个激活函数(也可以称作非线性因子),因此这个线性函数因为这个激活函数的作用,变成了一个非线性的函数(f=relu(X@W+B))。
那么通过这个非线性函数就可以去解决分类问题了吗?可以想象,可能还是不够,因为只是添加一个线性因子的非线性函数还是太简单。
注:在这里讲解为什么非线性函数就可以解决分类问题。以二维空间举例,首先,我们要明白两个知识点,无论什么线性函数在二维空间都是一条直线,而非线性函数可以拟合二维空间中的任何一种状态。也就是针对分类问题,大多数情况分类问题的数据集在二维空间的分布都不是线性的,因此我们添加非线性因子让线性函数变成非线性的,进而更好的去拟合分类问题中的数据集在二维空间中的分布情况。
4.2 隐藏层
上面说到添加一个激活函数的非线性函数(f=relu(X@W+B))还是太简单,为此科学家们又一次秃了头,想到了一个更好的办法,那就是一个非线性因子不够,那么我在多套一个非线性因子,在我的多次套娃之下,一定会有一个较好的结果。也因此,就出现了隐藏层。
现在我们假设深度模型没有隐藏层,那么模型也就是(out=relu(X@W+B)),输入一个x,直接给出一个结果,但是我们说到,一个激活函数可能不够,那么我们再添加一个激活函数。
那么模型将会变成(out = relu(relu(X@W+B))),这个模型我们可以看做两部分,第一部分是(relu(X@W+B)),第二部分是(relu(第一部分)),第一部分就是隐藏层(h_1),第二部分就是隐藏层(h_2)。也就是说第一部分的输出结果只是第二部分的输入,而第二部分的输出结果才是真正的结果。
4.3 隐藏层带来的问题
对于一个深度模型,隐藏层可能有数十层、上百层,甚至上千层,隐藏层的层数也正是深度学习中深度的来源。那么问题自然而然也就来了,上一个隐藏层是下一个隐藏层的输入,那么这个输入已经被激活函数激活过,也就是上一个隐藏层的输出是一个值,那么这个值到底代表什么意思呢?
目前,深度模型还无法给这个值表示什么意义做出合理的解释,但是我们可以把这个值抽象成一个特征,只不过这个特征是计算机模型能够认知的,可惜我们无法和模型进行交流。也因此,在一些需要对特征描述较为详细的项目中,这个模型可能并不能很好的实现特征描述的功能。
简单点说,隐藏层就是模型抽象出了原有输入的一个个人类看不懂的特征。就好比我们总是会把很帅的男人看作是有德,而你们总看不到有德的帅。
五、深度模型的流程
5.1 多个隐藏层的分类模型举例
在这里,我们举出一个实例,让大家很好的去了解如何通过隐藏层去实现类别分类。
- 输入(X_{[1,784]}),
- 假设第一层隐藏层的参数为({W_1}_{[784, 512]}, {B_1}_{[1,512]});假设第二层隐藏层的参数为({W_2}_{[521,256]}, {B_2}_{[1,256]});假设第三层隐藏层的参数为({W_3}_{[256,10]}, {B_3}_{[1,10]})
- (X)通过第一层隐藏层(h_1 = relue(X@W_1+B_1)),那么(h_1)的输出将是({h_1}_{[1,512]})
- 第一层隐藏层的输出通过第二层隐藏层(h_2=relu(h_1@W_2+B_2)),那么(h_2)的输出将是({h_2}_{[1,256]})
- 第二层隐藏层的输出通过第三层隐藏层(h_3 = relu(h_2@W_3+B_3)),那么(h_3)的输出将是({h_3}_{[1,10]})
相信看到第5步时你已经明白了为什么步骤2要设置如此的隐藏层参数,对的,目的就是为了让最后一层隐藏层的结果为([1,10]),因为我们是10分类,那么对于其中的512和256这两个值,我们能不能变化,其实是没啥问题的,但是为了更好的利用gpu的性能,推荐一般设置成2的幂方。
5.2 损失计算
通过上述流程,我们现在已经可以通过输入得到一个预测结果,并且结果也正好是一个类似于独热编码的矩阵,那么我们该如何计算预测结果和真实结果的损失呢?
方法很简单,使用我们中学就学过的一个知识点——欧式距离,假设如果结果是二分类,预测结果为[0.2,0.8],真实结果为[0,1],其中两者的欧式距离便是损失,学过线性代数的你,相信清楚,十分类亦是如此。
5.3 优化模型参数—反向传播算法
损失得到了,那么优化模型参数就很简单了,反向传播即可。在这里,都力求简单化,我给出一个反向传播的小实例,不严谨但容易理解。
假设我们有如下一个模型结构:
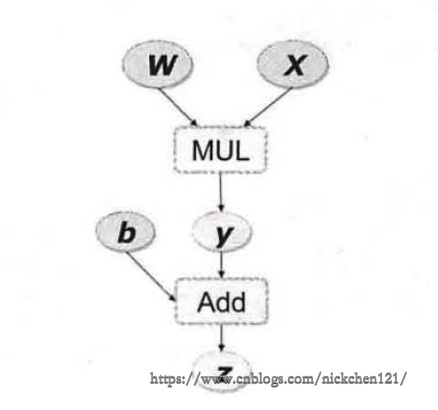
其中mul为乘法,add为加法,w和x是第一层隐藏层参数,y和b是第二程隐藏层参数,z是结果。从上图可以看出该模型的数学表示为:
如果z已知,我们可以:
- 求出(frac{partial{z}}{partial{y}}=1, frac{partial{z}}{partial{b}}=1)更新y和b的值
- 再通过求出(frac{partial{z}}{partial{w}}=frac{partial{z}}{partial{y}}frac{partial{y}}{partial{w}}=1*x,frac{partial{z}}{partial{x}}=frac{partial{z}}{partial{y}}frac{partial{z}}{partial{x}}=1*w)更新w和x的值。
这就是所谓的反向传播,只不过实际比这更复杂。
六、总结
这篇文章通过手写数字问题的引入,算是对深度网络模型做了一个简单的介绍。
接下来也将通过torch解决手写数字问题,两者映照,将会让你更加了解torch实现一个深度模型解决实际问题的流程。