1. 分析
(1)配置集群
(2)启动、测试集群增、删、查
(3)执行WordCount案例
2. 执行步骤
(1)配置集群
(a)配置:hadoop-env.sh
Linux系统中获取JDK的安装路径:
[atguigu@ hadoop101 ~]# echo $JAVA_HOME
/opt/module/jdk1.8.0_144
修改JAVA_HOME 路径:
在Hadoop的目录下,vim Hadoop-env.sh

export JAVA_HOME=/opt/module/jdk1.8.0_144

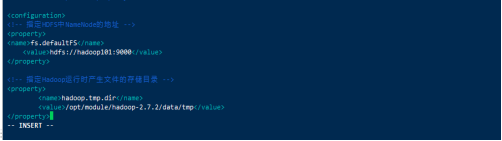
(b)配置:core-site.xml

<!-- 指定HDFS中NameNode的地址 -->
<property>
<name>fs.defaultFS</name>
<value>hdfs://hadoop101:9000</value>
</property>
<!-- 指定Hadoop运行时产生文件的存储目录 -->
<property>
<name>hadoop.tmp.dir</name>
<value>/opt/module/hadoop-2.7.2/data/tmp</value>
</property>
c)配置:hdfs-site.xml
<!-- 指定HDFS副本的数量 -->
<property>
<name>dfs.replication</name>
<value>1</value>
</property>
(2)启动集群
(a)格式化NameNode(第一次启动时格式化,以后就不要总格式化)
[atguigu@hadoop101 hadoop-2.7.2]$ bin/hdfs namenode -format
(b)启动NameNode
[atguigu@hadoop101 hadoop-2.7.2]$ sbin/hadoop-daemon.sh start namenode

(c)启动DataNode
[atguigu@hadoop101 hadoop-2.7.2]$ sbin/hadoop-daemon.sh start datanode

(3)查看集群
(a)查看是否启动成功
[atguigu@hadoop101 hadoop-2.7.2]$ jps
13586 NameNode
13668 DataNode
13786 Jps