一、安装jieba库
:>pip install jieba #或者 pip3 install jieba
二、jieba库解析
jieba库主要提供提供分词功能,可以辅助自定义分词词典。
jieba库中包含的主要函数如下:
jieba.cut(s) 精确模式,返回一个可迭代的数据类型
jieba.cut(s,cut_all=True) 全模式,输出文本s中所有可能的单词
jieba.cut_for_search(s) 搜索引擎模式,适合搜索引擎建立索引的分词结果
jieba.lcut(s) 精确模式,返回一个列表类型,建议使用
jieba.lcut(s,cut_all=True) 全模式,返回一个列表类型,建议使用
jieba.lcut_for_search(s) 搜索引擎模式,返回一个列表类型,建议使用
jieba.add_word(w) 向分词词典中增加新词w
三、用jieba库统计文本的词频
《流浪地球》是刘慈欣的一部作品。该书讲述了庞大的地球逃脱计划,逃离太阳系,前往新家园。从网上获取该书的文本文件,保存于桌面上,命名为“流浪地球。”
现统计其文本中出现次数最多的是个词语,源代码如下:

import jieba
txt = open("C:\Users\Administrator\Desktop\流浪地球.txt", "r", encoding='utf-8').read()
words = jieba.lcut(txt)
counts = {}
for word in words:
if len(word) == 1: #排除单个字符的分词结果
continue
else:
counts[word] = counts.get(word,0) + 1
items = list(counts.items())
items.sort(key=lambda x:x[1], reverse=True)
for i in range(10):
word, count = items[i]
print ("{0:<10}{1:>5}".format(word, count))
运行程序后,输出结果如下:

故容易得知流浪地球中出现频次较高的词语
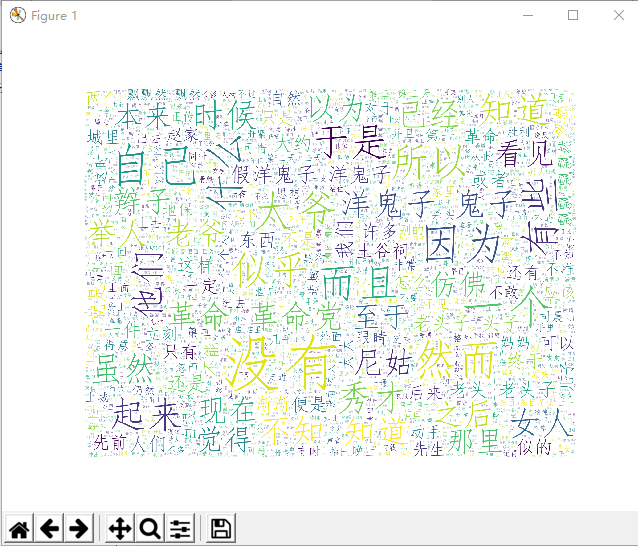
四、结合jieba库的词频统计制作词云图
1、准备工作:pip 安装 jieba , wordcloud ,matplotlib
2以阿Q正传为例:
源代码为:
from wordcloud import WordCloud
import matplotlib.pyplot as plt
import jieba
#生成词云
def create_word_cloud(filename):
text = open("{}.txt".format(filename)).read()
# 结巴分词
wordlist = jieba.cut(text, cut_all=True)
wl = " ".join(wordlist)
# 设置词云
wc = WordCloud(
# 设置背景颜色
background_color="white",
# 设置最大显示的词云数
max_words=2000,
# 这种字体都在电脑字体中,一般路径
font_path='C:WindowsFontssimfang.ttf',
height=1200,
width=1600,
# 设置字体最大值
max_font_size=200,
# 设置有多少种随机生成状态,即有多少种配色方案
random_state=100,
)
myword = wc.generate(wl) # 生成词云
# 展示词云图
plt.imshow(myword)
plt.axis("off")
plt.show()
wc.to_file('p.png') # 把词云保存下
if __name__ == '__main__':
create_word_cloud('C:\Users\Administrator\Desktop\阿Q正传')
运行程序后,输出结果如下: