案例1:Python3爬虫代理池
1.找一个公开的代理ip网站
比如西刺免费代理IP
2.编写xpath进行筛选
//tr/td[2]/text()
//tr/td[3]/text()
//tr/td[6]/text()
3.编写代码
import requests
import os,time,random
from fake_useragent import UserAgent
from lxml import etree
class ProxySpider(object):
def __init__(self):
self.baseurl = 'https://www.xicidaili.com/nn/{}'
self.xpathip = '//tr/td[2]/text()'
self.xpathport = '//tr/td[3]/text()'
self.xpathhttps = '//tr/td[6]/text()'
self.ua = UserAgent()
def request_html(self,url):
try:
header = {'User-Agent':'Mozilla/4.0'}
html = requests.get(url=url, headers=header).text
return html
except Exception as e:
print(e)
return 'error'
def proxy_request_html(self,url,ip,isHttps):
time.sleep(random.randint(1,2))
proxy = {}
if isHttps is True:
proxy = {
'https': ip
}
else:
proxy = {
'http': ip
}
try:
header = {'User-Agent': self.ua.random}
html = requests.get(url=url,headers=header, proxies=proxy, timeout=8)
return True
except Exception as e:
print(ip,e)
return False
def get_html(self,url):
print(url)
html = self.request_html(url)
self.parse_html(html)
def parse_html(self,html):
item_ip = []
item_port = []
item_http = []
xpathobj = etree.HTML(html)
iplist = xpathobj.xpath(self.xpathip)
for ip in iplist:
item_ip.append(ip)
port_list = xpathobj.xpath(self.xpathport)
for port in port_list:
item_port.append(port)
httpsStrs = xpathobj.xpath(self.xpathhttps)
for is_https in httpsStrs:
item_http.append(is_https)
for li in range(0, len(item_ip),1):
test_ip = item_ip[li]+":"+item_port[li]
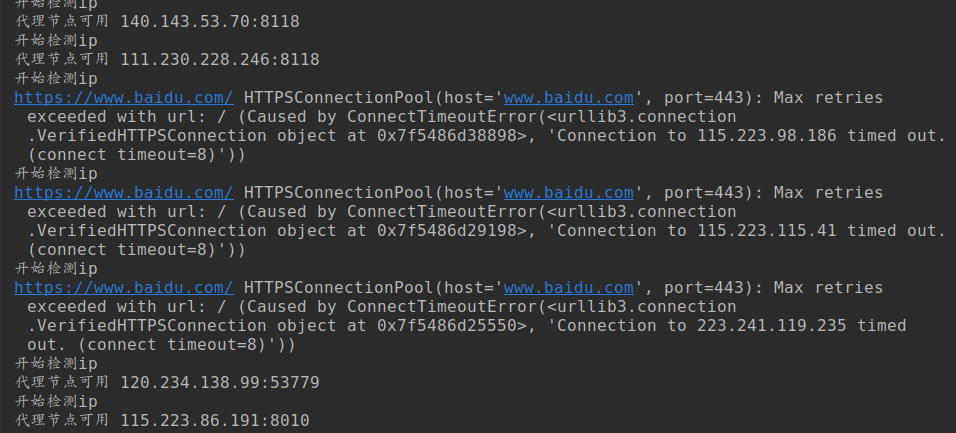
print('开始检测ip')
if item_http[li] == "HTTPS":
self.test_proxy(test_ip,True)
elif item_http[li] == "HTTP":
self.test_proxy(test_ip, False)
def test_proxy(self,proxy_address,isHttps):
ret = self.proxy_request_html('https://www.baidu.com/',proxy_address,isHttps)
if ret is True:
with open('proxy.log','a+') as f:
f.write(proxy_address+'
')
print('代理节点可用',proxy_address)
def run(self):
url = self.baseurl.format(1)
self.get_html(url)
if __name__ == '__main__':
spider = ProxySpider()
spider.run();
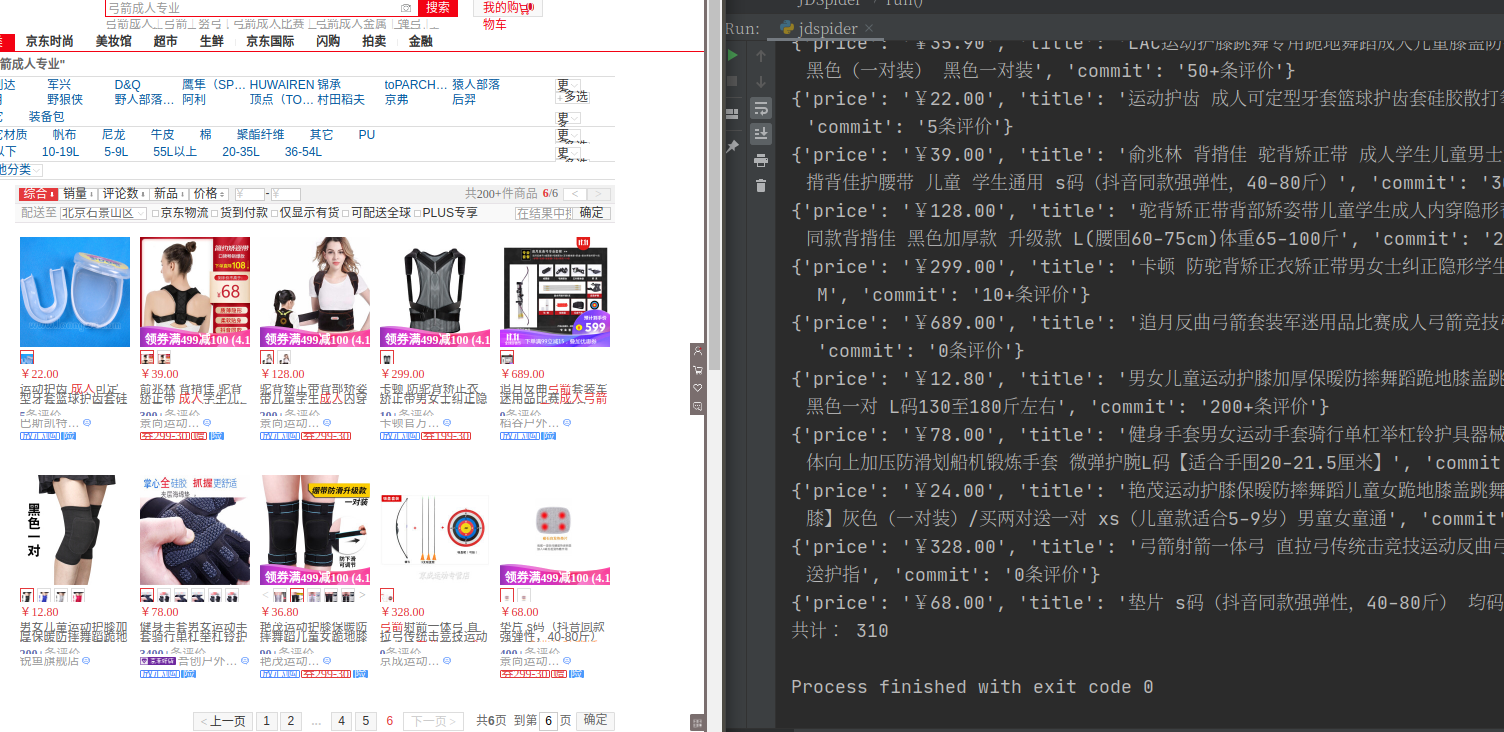
4.结果
可以看出,http的基本都是可以使用的,HTTPS的基本都不能使用
案例2:Python3爬虫-baidutieba-xpath
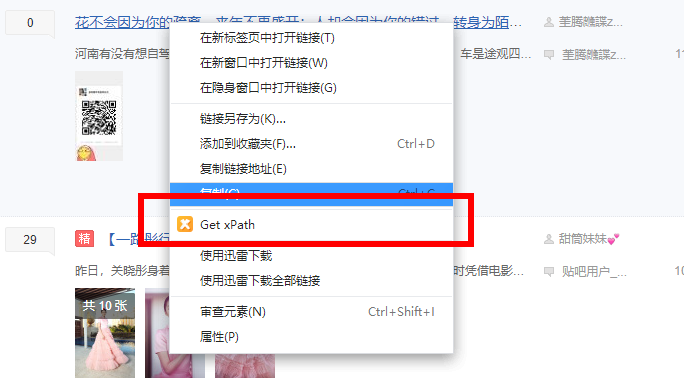
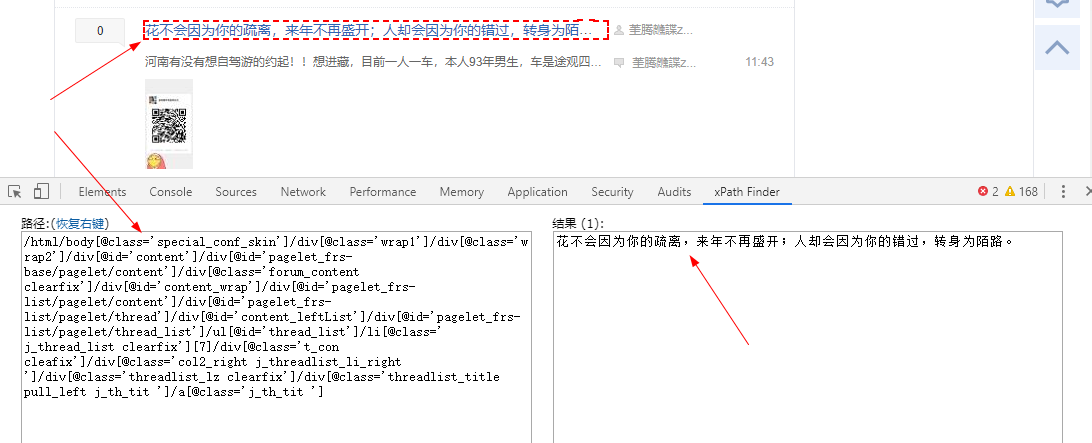
- 使用xpath插件,进行筛选
直接鼠标在想筛选的文字或者图片,右键,就有xpath,然后F12,修改修改就可以了
2.编写代码
Response Content
We can read the content of the server’s response. Consider the GitHub timeline again:
import requests
r = requests.get('https://api.github.com/events')
r.text
'[{"repository":{"open_issues":0,"url":"https://github.com/...
Requests will automatically decode content from the server. Most unicode charsets are seamlessly decoded.
When you make a request, Requests makes educated guesses about the encoding of the response based on the HTTP headers. The text encoding guessed by Requests is used when you access r.text. You can find out what encoding Requests is using, and change it, using the r.encodingproperty:
r.encoding
'utf-8'r.encoding = 'ISO-8859-1'
If you change the encoding, Requests will use the new value of r.encoding whenever you call r.text. You might want to do this in any situation where you can apply special logic to work out what the encoding of the content will be. For example, HTML and XML have the ability to specify their encoding in their body. In situations like this, you should use r.content to find the encoding, and then set r.encoding. This will let you use r.text with the correct encoding.
Requests will also use custom encodings in the event that you need them. If you have created your own encoding and registered it with the codecs module, you can simply use the codec name as the value of r.encoding and Requests will handle the decoding for you.
Binary Response Content
You can also access the response body as bytes, for non-text requests:
r.content
b'[{"repository":{"open_issues":0,"url":"https://github.com/...
The gzip and deflate transfer-encodings are automatically decoded for you.
For example, to create an image from binary data returned by a request, you can use the following code:
from PIL import Image
from io import BytesIO
i = Image.open(BytesIO(r.content))
JSON Response Content
There’s also a builtin JSON decoder, in case you’re dealing with JSON data:
import requests
r = requests.get('https://api.github.com/events')
r.json()
[{'repository': {'open_issues': 0, 'url': 'https://github.com/...
In case the JSON decoding fails, r.json() raises an exception. For example, if the response gets a 204 (No Content), or if the response contains invalid JSON, attempting r.json() raises ValueError: No JSON object could be decoded.
It should be noted that the success of the call to r.json() does not indicate the success of the response. Some servers may return a JSON object in a failed response (e.g. error details with HTTP 500). Such JSON will be decoded and returned. To check that a request is successful, user.raise_for_status() or check r.status_code is what you expect.
Raw Response Content
In the rare case that you’d like to get the raw socket response from the server, you can access r.raw. If you want to do this, make sure you set stream=True in your initial request. Once you do, you can do this:
r = requests.get('https://api.github.com/events', stream=True)
r.raw
<urllib3.response.HTTPResponse object at 0x101194810>
r.raw.read(10)
'x1fx8bx08x00x00x00x00x00x00x03'
In general, however, you should use a pattern like this to save what is being streamed to a file:
with open(filename, 'wb') as fd:
for chunk in r.iter_content(chunk_size=128):
fd.write(chunk)
Using Response.iter_content will handle a lot of what you would otherwise have to handle when using Response.raw directly. When streaming a download, the above is the preferred and recommended way to retrieve the content. Note that chunk_size can be freely adjusted to a number that may better fit your use cases.
from lxml import etree
import re,time,os,random
import requests
from urllib import parse
from fake_useragent import UserAgent
class BaiduTiebaSpider(object):
def __init__(self):
self.baseurl = r'http://tieba.baidu.com/f?kw={}&pn={}'
self.title_baseurl = r'https://tieba.baidu.com{}'
self.picXpath = r'//cc//img[@class="BDE_Image"]/@src'
self.titleurlXpath = r'//li//a[@class="j_th_tit "]/@href'
self.videoXpath = r'/div[@class="video_src_wrap_main"]/video/@src'
self.ua = UserAgent()
self.savePath = r'/home/user/work/spider/baidu/BaiduTieba/'
def get_html(self,url):
# header = {'User-Agent':self.ua.random}
header = {'User-Agent':'Mozilla/5.0 (Windows NT 10.0; WOW64; Trident/7.0; rv:11.0) like Gecko'}
res = requests.get(url=url,headers=header).content
return res
def parse_html(self,html):
parse = etree.HTML(html)
titlelink_list = parse.xpath(self.titleurlXpath)
for li in titlelink_list:
titleurl = self.title_baseurl.format(li)
print(titleurl)
self.save_html(titleurl)
time.sleep(random.randint(2,3))
def save_html(self,url):
html = self.get_html(url)
parse = etree.HTML(html)
piclinks = parse.xpath(self.picXpath)
for pics in piclinks:
self.save_img(pics,self.savePath+pics[-10:])
videolinks = parse.xpath(self.videoXpath)
for videos in videolinks:
self.save_img(videos,self.savePath+videos[-10:])
def save_img(self,imgurl,filename):
img = self.get_html(imgurl)
with open(filename,'wb') as f :
f.write(img)
print(filename,'DownLoad Sucess')
def run(self):
name = input('输入要查询的贴吧名称>')
start = input('Start Page>')
end = input('End Page>')
mainurl = self.baseurl.format(parse.quote(name),0)
print(mainurl)
pagehtml = self.get_html(mainurl)
self.parse_html(pagehtml)
if __name__ == '__main__':
spider = BaiduTiebaSpider()
spider.run();
注意header
3.结果
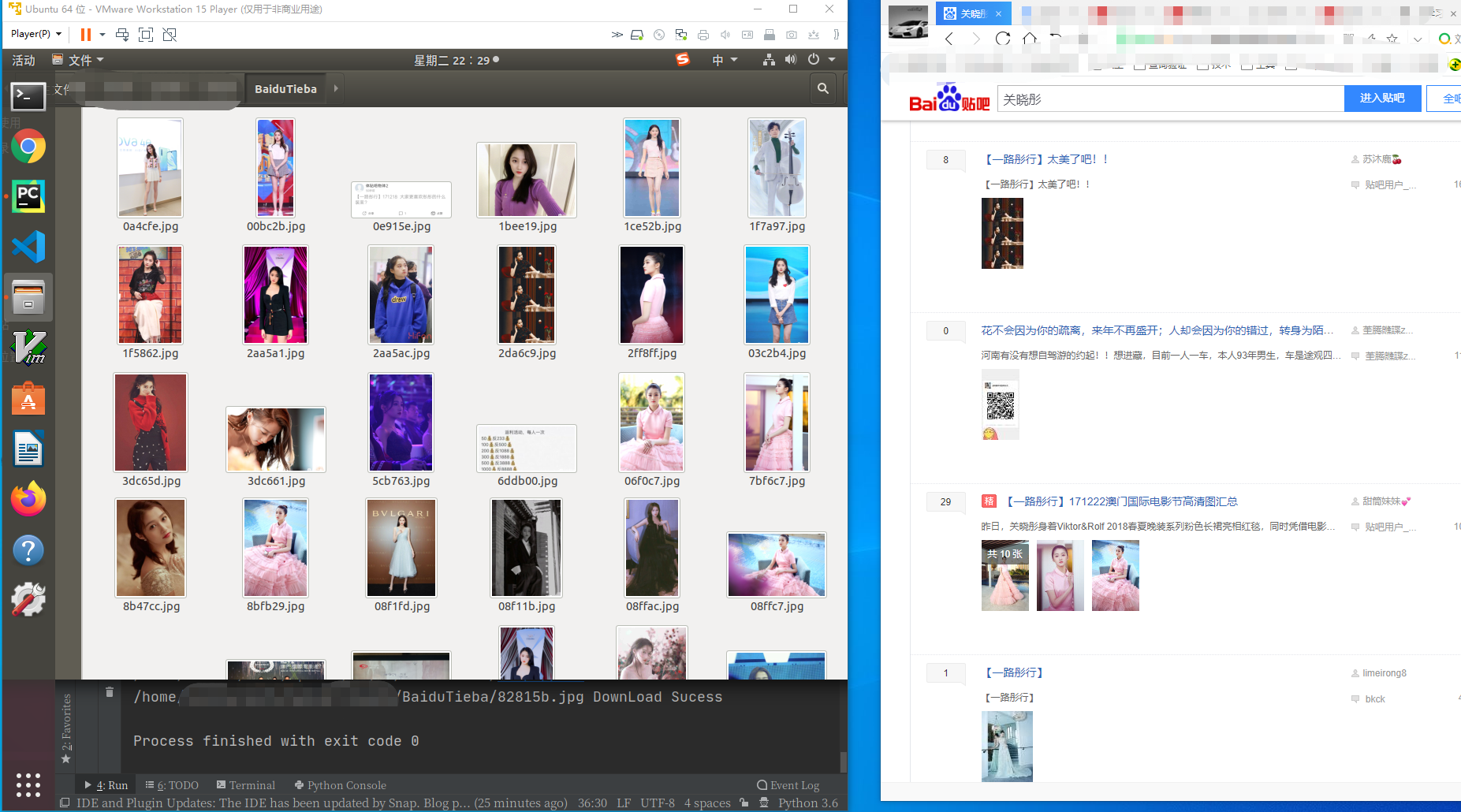
案例3:Python3 爬虫-链家2手房-xpath
- XPath 是一门在 XML 文档中查找信息的语言。XPath 可用来在 XML 文档中对元素和属性进行遍历。
XPath 是 W3C XSLT 标准的主要元素,并且 XQuery 和 XPointer 都构建于 XPath 表达之上。
因此,对 XPath 的理解是很多高级 XML 应用的基础。
- Xpath插件在Chrome浏览器商店中,360浏览器扩展中心里也有
打开一个网页,F12,就在最后的

3.xpath过滤
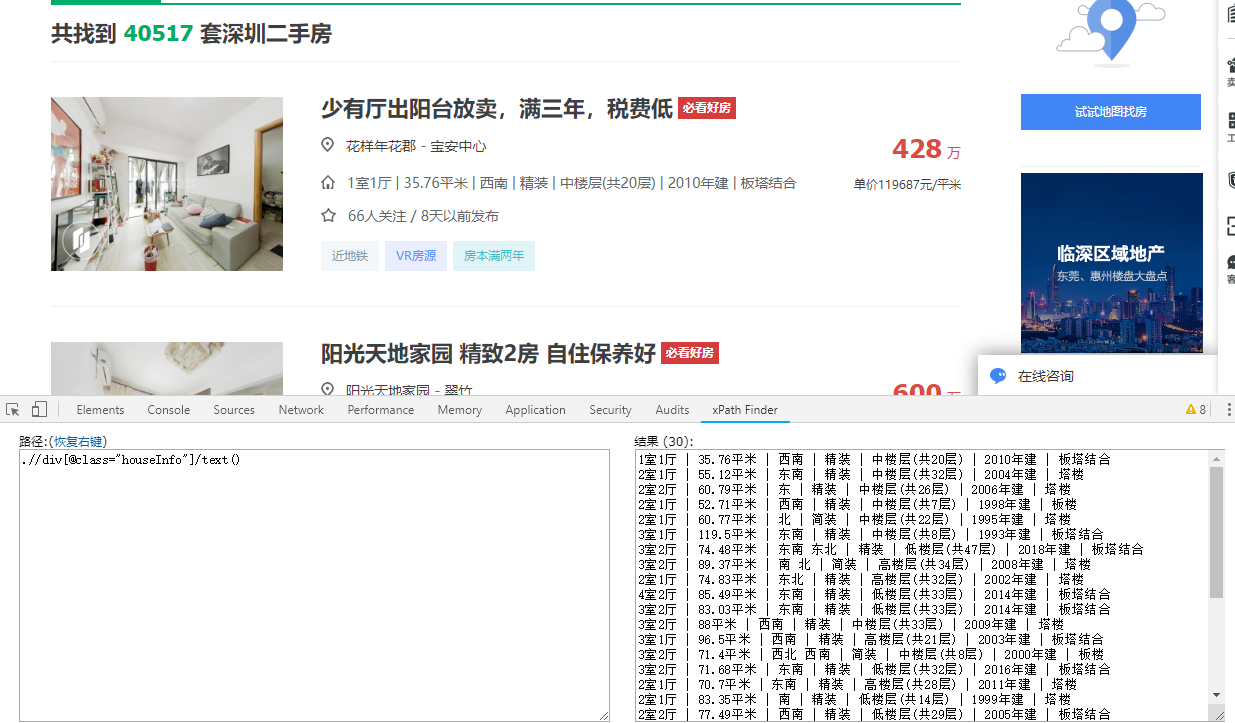
在这里面测试,测试好了,放到代码中
- Python3 代码
import requests
import random,re,time
from fake_useragent import UserAgent
from lxml import etree
class LianJiaSpider(object):
def __init__(self):
self.baseurl = 'https://sz.lianjia.com/ershoufang/pg{}/'
self.ua = UserAgent()
def get_html(self,url):
header = {'User-Agent':self.ua.random}
html = requests.get(url,headers=header,timeout=5).text
# html.encoding = 'utf-8'
self.parse_html(html)
def parse_html(self,html):
parse = etree.HTML(html)
li_list = parse.xpath('//ul[@class="sellListContent"]/li[@class="clear LOGVIEWDATA LOGCLICKDATA"]')
item = {}
for i in li_list:
item['name'] = i.xpath('.//a[@data-el="region"]/text()')[0]
info_list = i.xpath('.//div[@class="houseInfo"]/text()')[0].split('|')
item['model'] = info_list[0].strip()
item['area'] = info_list[1].strip()
item['direction'] = info_list[2].strip()
item['perfect'] = info_list[3].strip()
item['floor'] = info_list[4].strip()
item['age'] = info_list[5].strip()
item['address'] = i.xpath('.//div[@class="positionInfo"]/a/text()')[0].strip()
item['total'] = i.xpath('.//div[@class="totalPrice"]/span/text()')[0].strip()
item['unit'] = i.xpath('.//div[@class="unitPrice"]/span/text()')[0].strip()[2:-4]
print(item)
def run(self):
url = self.baseurl.format(1)
self.get_html(url)
if __name__ == '__main__':
spider = LianJiaSpider();
spider.run();
5.结果
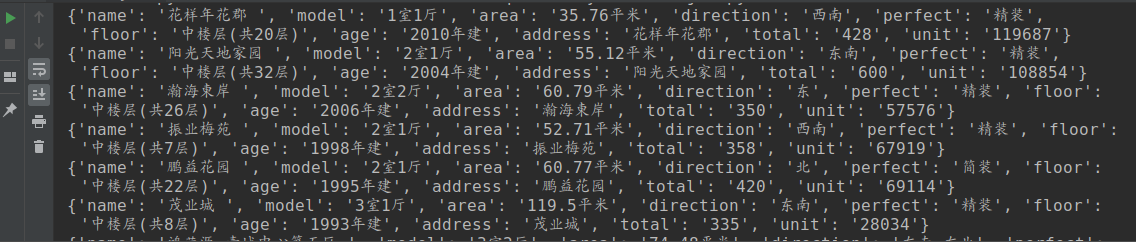
穷 穷 穷,买不起,2手都买不起
案例4:python3 爬虫-百度图片
import requests
import re,time,random,os
from urllib import parse
from fake_useragent import UserAgent
class BaiduImgSpider(object):
def __init__(self):
self.baseurl = 'https://image.baidu.com/search/index?tn=baiduimage&word={}'
self.count = 1;
self.ua = UserAgent()
self.savepath = '/home/user/work/spider/day03/'
self.re_str = r'{"thumbURL":"(.*?)","replaceUrl":'
def get_html(self,name,orgname):
header = {'User-Agent':self.ua.random}
url = self.baseurl.format(name)
html = requests.get(url=url,headers = header).text
pattent = re.compile(self.re_str,re.S)
img_list = pattent.findall(html)
path = self.savepath+orgname
if not os.path.exists(path):
os.mkdir(path)
for img_link in img_list:
print(img_link)
self.save_img(img_link,path)
time.sleep(random.randint(1,2))
def save_img(self,url,path):
header = {'User-Agent': self.ua.random}
html = requests.get(url=url,headers=header).content
filename = path+"/"+str(self.count)+'.jpg'
with open(filename,'wb') as f:
f.write(html)
print('下载成功',filename)
self.count += 1
def run(self):
search_name = input('输入要获取的名字>');
word = parse.quote(search_name)
self.get_html(word,search_name)
if __name__ == '__main__':
spider = BaiduImgSpider()
spider.run();
直接上代码了,非常简单的
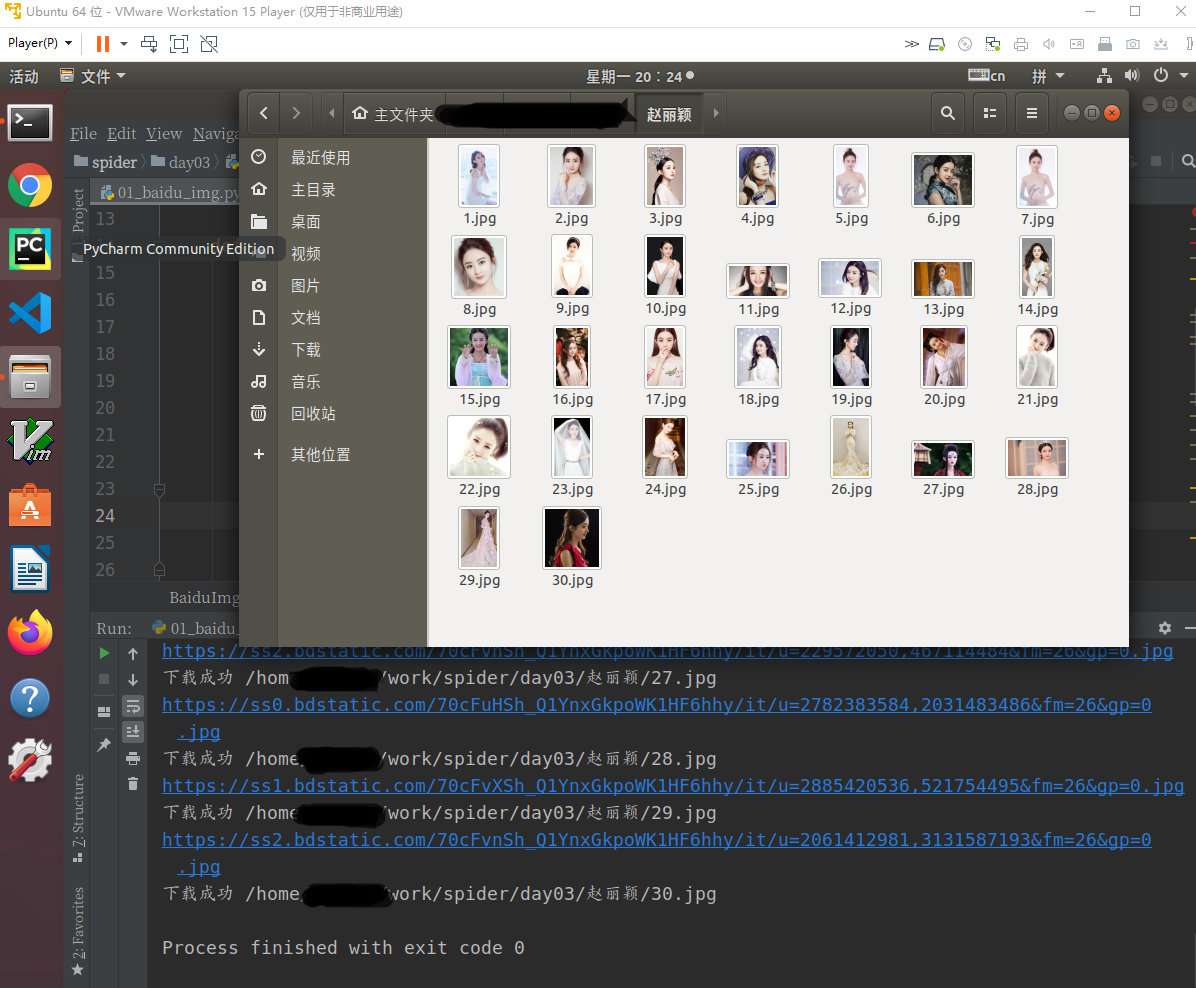
案例5:Python3 爬虫 电影天堂
from urllib import request
import re,time,random
from fake_useragent import UserAgent
class DyTTSpider(object):
def __init__(self):
self.base_url = 'https://www.dytt8.net'
self.url_one = 'https://www.dytt8.net/html/gndy/dyzz/list_23_{}.html'
self.ua = UserAgent()
def get_html(self,url):
header = {'User-Agent':self.ua.random}
req = request.Request(url,headers=header)
res = request.urlopen(req)
ret = res.read().decode('gb2312','ignore')
return ret;
def re_html(self,html,restr):
patent = re.compile(restr,re.S)
ret = patent.findall(html)
return ret;
def parse_html(self,one_url):
html_ret = self.get_html(one_url);
re_str = r'<table .*?<td width="5%".*?<a href="(.*?)" class="ulink">.*?</table>';
ret_list = self.re_html(html_ret, re_str);
for link in ret_list:
print(link)
self.parse_sencond(self.base_url+link)
time.sleep(random.randint(2,3))
def parse_sencond(self,second_html):
item = {}
html_ret = self.get_html(second_html)
re_str = r'<div class="title_all".*?<font.*?>(.*?)</font>.*?<td style="WORD-WRAP:.*?gaygpquf="(.*?)" clickid.*?</td>'
two_list = self.re_html(html_ret,re_str)
item['name'] = two_list[0].strip()
item['dlink'] = two_list[1].strip()
def run(self):
geturl = self.url_one.format(1)
self.parse_html(geturl)
if __name__ == '__main__':
dy = DyTTSpider()
dy.run();
案例6:Python3 爬虫 youdao
import requests
import random,time
from hashlib import md5
from fake_useragent import UserAgent
'''
var t = n.md5(navigator.appVersion)
, r = "" + (new Date).getTime()
, i = r + parseInt(10 * Math.random(), 10);
return {
ts: r,
bv: t,
salt: i,
sign: n.md5("fanyideskweb" + e + i + "Nw(nmmbP%A-r6U3EUn]Aj")
}
'''
class FanyiSpider(object):
def __init__(self):
self.baseurl = 'http://fanyi.youdao.com/translate_o?smartresult=dict&smartresult=rule'
self.ua = UserAgent()
def make_formdata_string(self,word):
formdata = {
"i": "",
"from": "AUTO",
"to": "AUTO",
"smartresult": "dict",
"client": "fanyideskweb",
"salt": "",
"sign": "",
"ts": "",
"bv": "37074a7035f34bfbf10d32bb8587564a",
"doctype": "json",
"version": "2.1",
"keyfrom": "fanyi.web",
"action": "FY_BY_REALTlME",
}
s = md5()
formdata['i'] = word;
formdata['ts'] = str(int(time.time()*1000));
# formdata['bv'] = s.hexdigest();
formdata['salt'] = formdata['ts'] + str(int(random.randint(0,9)))
signstring = "fanyideskweb" + word + formdata['salt'] + "Nw(nmmbP%A-r6U3EUn]Aj"
s.update(signstring.encode())
formdata['sign'] = s.hexdigest();
return formdata;
def make_headerString(self):
headerdata = {
"Accept": "application/json, text/javascript, */*; q=0.01",
"Accept-Encoding": "gzip, deflate",
"Accept-Language": "zh-CN,zh;q=0.9",
"Connection": "keep-alive",
"Content-Length": "240",
"Content-Type": "application/x-www-form-urlencoded; charset=UTF-8",
"Cookie": "DICT_UGC=be3af0da19b5c5e6aa4e17bd8d90b28a|; OUTFOX_SEARCH_USER_ID=-259218095@117.61.240.151; JSESSIONID=abcd4CqXd2rvOfBBNVfgx; OUTFOX_SEARCH_USER_ID_NCOO=928698907.9532578; _ntes_nnid=163fba552b6912766f975a5c9077e584,1587086791577; SESSION_FROM_COOKIE=fanyiweb; YOUDAO_FANYI_SELECTOR=OFF; ___rl__test__cookies=1587095527239",
"Host": "fanyi.youdao.com",
"Origin": "http://fanyi.youdao.com",
"Referer": "http://fanyi.youdao.com/?keyfrom=fanyi-new.logo",
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/69.0.3497.100 Safari/537.36",
"X-Requested-With": "XMLHttpRequest",
}
# headerdata['User-Agent'] = self.ua.random;
return headerdata;
def request_str(self):
pass
def post_html(self,headerdata,formdata):
ret = requests.post(url=self.baseurl,data=formdata,headers=headerdata)
print(ret.text)
def run(self):
word = input('输入要查询的文字>')
formdata = self.make_formdata_string(word);
self.post_html(self.make_headerString(),formdata)
if __name__ == '__main__':
spider = FanyiSpider()
spider.run();

案例7:Tencent招聘
这个网站是HTTP2.0的,不过有些参数未验证,仍可以跑
import requests
import time,random,os
from fake_useragent import UserAgent
class TencentSpider(object):
def __init__(self):
self.baseurl = 'https://careers.tencent.com/tencentcareer/api/post/Query?timestamp=1587104037054&countryId=&cityId=&bgIds=&productId=&categoryId=&parentCategoryId=&attrId=&keyword=&pageIndex={}&pageSize=10&language=zh-cn&area=cn'
self.header= {
# ":authority": "careers.tencent.com",
# ":method": "GET",
# ":path": "/tencentcareer/api/post/Query?timestamp=1587104037054&countryId=&cityId=&bgIds=&productId=&categoryId=&parentCategoryId=&attrId=&keyword=&pageIndex=3&pageSize=10&language=zh-cn&area=cn",
# ":scheme": "https",
"accept": "application/json, text/plain, */*",
"accept-encoding": "gzip, deflate, br",
"accept-language": "zh-CN,zh;q=0.9",
"referer": "https://careers.tencent.com/search.html?index={}",
"user-agent": "Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/69.0.3497.100 Safari/537.36",
}
self.ua = UserAgent()
def get_html(self,pageindex):
self.header['user-agent'] = self.ua.random
self.header['referer'] = self.header['referer'].format(pageindex)
url = self.baseurl.format(pageindex)
ret = requests.get(url=url,headers=self.header)
print(ret.text)
def run(self):
self.get_html(3)
if __name__ == '__main__':
spider = TencentSpider()
spider.run();
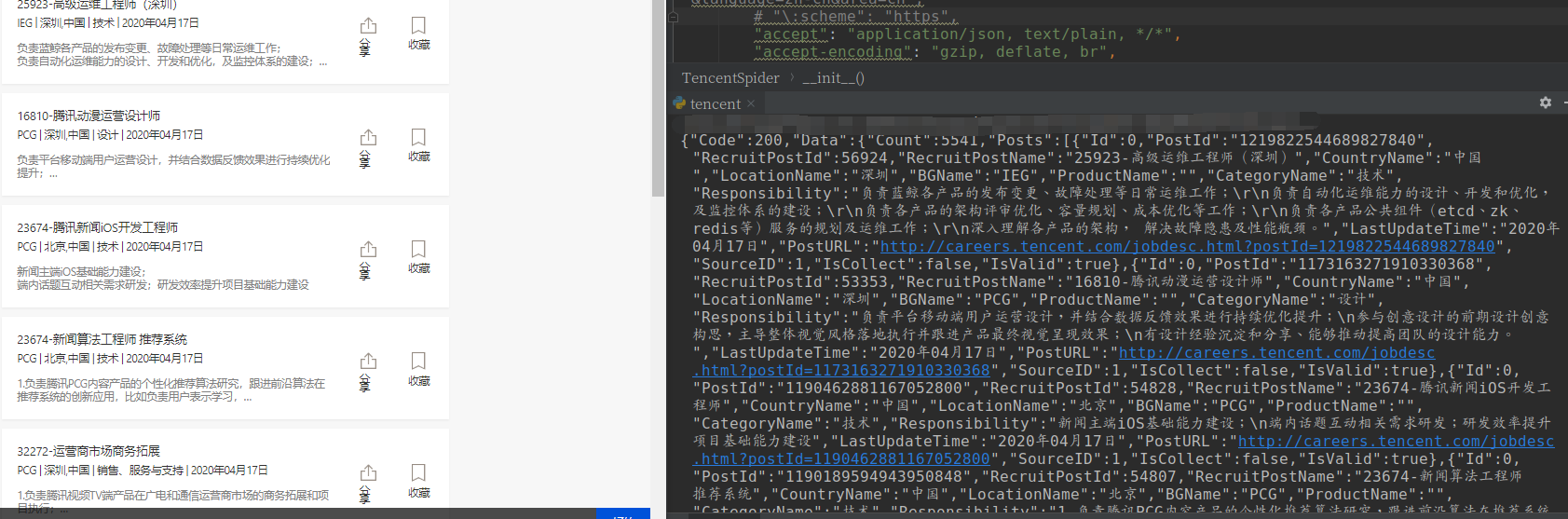
案例8 douban电影
整体比较简单,F12里面都有,网站返回的json
import requests
from fake_useragent import UserAgent
import random,time
import json
from urllib import parse
class DoubanMovieSpider(object):
def __init__(self):
self.baseurl = 'https://movie.douban.com/j/search_tags?type=movie&source='
self.detilurl = 'https://movie.douban.com/j/search_subjects?type=movie&tag={}&sort=recommend&page_limit=20&page_start={}'
self.ua = UserAgent()
self.douban_movie_types = []
def make_header(self):
data = {
'User-Agent':self.ua.random
}
return data
def get_html(self,url):
ret = requests.get(url=url,headers=self.make_header()).text
return ret
def run(self):
movie_type_json = self.get_html(self.baseurl)
move_type = json.loads(movie_type_json);
for item in move_type['tags']:
self.douban_movie_types.append(item)
print(item,sep=None)
want_type = input('请输入感兴趣的类别>')
startpage = input('输入开始页>')
endpage = input('输入结束页>')
if want_type in self.douban_movie_types:
# for i in range(startpage,endpage,20):
insterurl = self.detilurl.format(parse.quote(want_type),0)
movie_infos_json = self.get_html(insterurl)
movie_infos = json.loads(movie_infos_json)
for info in movie_infos['subjects']:
print(info['title'],info['rate'],info['url'])
if __name__ == '__main__':
spider = DoubanMovieSpider()
spider.run();
案例9:xiaomiappshop
获取应用类别和总页数,多线程获取
import requests
import json
from threading import Thread
from queue import Queue
import time,random
from fake_useragent import UserAgent
from lxml import etree
class AppShopSpider(object):
def __init__(self):
self.mainurl = 'http://app.mi.com/'
self.baseurl = 'http://app.mi.com/categotyAllListApi?page={}&categoryId={}&pageSize=30'
self.xpathtype = '//ul[@class="category-list"]/li/a'
self.xpathpagenum = '//div[@class="pages"]/a[6]/text()'
self.q = Queue()
self.ua = UserAgent()
self.type_code = {}
def make_url(self,categoryid,startpage,endpage):
for page in range(startpage,endpage,1):
url = self.baseurl.format(page,categoryid)
self.q.put(url)
def get_url(self):
if not self.q.empty():
url = self.q.get()
print(url)
self.parse_html(self.get_html(url))
def get_html(self,url):
header = {'User-Agent':self.ua.random}
ret = requests.get(url=url,headers=header).text
return ret;
def parse_html(self,html):
jsonstr = json.loads(html)
for item in jsonstr['data']:
print(item['displayName'])
def get_typecode(self):
html = self.get_html(self.mainurl)
xpathobj = etree.HTML(html)
ret = xpathobj.xpath(self.xpathtype)
for item in ret:
apptype = item.xpath('./text()')[0]
appcode = item.xpath('./@href')[0].split('/')[-1]
self.type_code[apptype] = appcode
print(apptype)
def get_typepage(self,keyword):
for key,value in self.type_code.items():
if key == keyword:
url = self.baseurl.format(0,value)
html = self.get_html(url)
jsonstr = json.loads(html)
pagenum = int(int(jsonstr['count'])/30 +1)
print('总页数为>',pagenum)
def run(self):
self.get_typecode();
instert_type = input('输入想获取的类别>')
self.get_typepage(instert_type)
strtpage = int(input('输入开始页面>'))
endpage = int(input('输入结束页面>'))
self.make_url(self.type_code[instert_type],strtpage,endpage)
thread_list= []
for i in range(5):
t = Thread(target=self.get_url())
thread_list.append(t)
t.start();
for t in thread_list:
t.join()
if __name__ == '__main__':
starttime = time.time()
spider = AppShopSpider()
spider.run();
endtime = time.time()
print('时间>%.2f'%(endtime-starttime))
案例10:jingdong商品
使用selenium调起chrome浏览器抓取数据,速度慢,但是简单
2020-04-19
from selenium import webdriver
import time
class JDSpider(object):
def __init__(self):
self.baseurl = 'https://www.jd.com/'
self.searchinput_xpath = '//*[@id="key"]'
self.searchButton_xpath = '//*[@id="search"]/div/div[2]/button'
self.browser = None
self.detail_xpath = '//*[@id="J_goodsList"]/ul/li'
self.nextpage_xpath = '//*[@id="J_bottomPage"]/span[1]/a[9]'
self.sum = 0;
def get_html(self,url,word):
self.browser.get(url)
search_input = self.browser.find_element_by_xpath(self.searchinput_xpath)
search_input.send_keys(word)
time.sleep(3)
self.send_click(self.searchButton_xpath)
self.parse_html()
def send_click(self,xpathstr):
button = self.browser.find_element_by_xpath(xpathstr)
button.click()
time.sleep(3)
def scrollend(self):
js = "var q=document.documentElement.scrollTop=100000"
self.browser.execute_script(js)
time.sleep(3)
def parse_html(self):
self.scrollend()
item = {}
li_list = self.browser.find_elements_by_xpath(self.detail_xpath)
for li in li_list:
item['price'] = li.find_element_by_xpath('.//div[@class="p-price"]').text.strip()
item['title'] = li.find_element_by_xpath('.//div[@class="p-name p-name-type-2"]/a/em').text.strip()
item['commit'] = li.find_element_by_xpath('.//div[@class="p-commit"]/strong').text.strip()
print(item)
self.sum +=1;
def run(self):
name = input('输入想搜索的关键字>')
self.browser = webdriver.Chrome()
self.get_html(self.baseurl,name)
while True:
if self.browser.page_source.find('pn-next disable') == -1:
self.browser.find_element_by_class_name('pn-next').click()
time.sleep(3)
self.parse_html()
else:
break;
if __name__ == '__main__':
spider = JDSpider();
spider.run();
print('共计:',spider.sum)