一.今日内容
根据现有数据,编写分析报告,分析电影市场情况并预测观众群对“四合影业”计划投拍的电影“青春的竞赛”的评分。
1、 内容源码利用WPS或WORD软件完成分析报告,文件名为anl0400.doc或anl0400.docx,报告中需要明确描述分析方法,分析过程。
2、 分析报告中用明确的表格显示以下数据,评分最高值,评分最低值,评分中位数,评分均值 。
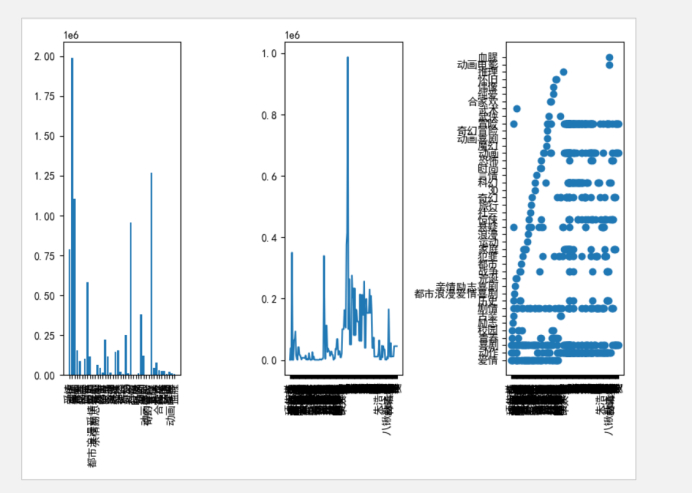
3、 分析报告中至少包含三种图,分别能够表达“各种类型片票房收入比较”,“导演票房收入比较”,“导演执导过的影片类型”的内容。
4、 提交支撑程序名为ans0400.py,要求程序运行后不可做任何人为操作,自动完成以下任务:
1) 在一个子图系统中输出要求3中所提及的三种图,该子图水平排列,顺序以要求3所列顺序为准,每个子图的具体形式不限。程序能够有提示地输出4个数据:评分最高值,评分最低值,评分中位数,评分均值。
2) 要求按次序将分析得出的评分最高值,评分最低值,评分中位数,评分均值,存入ans0400.dat文件中,要求ans0400.dat只包含所要求的4个浮点型数据,每个数据保留2位小数,英文逗号分隔,不分行,文件样例如下:
二.内容源码
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
import re
import sys
file_data = pd.read_csv(r'C:UsersliuDesktopargarg04score.log',sep=',')
file_data.fillna(0,inplace=True)
file_data.drop_duplicates(inplace=True)
db = file_data[file_data['userid'].isin([1344,1400,1102,1191,1488])]
max = db['score'].max()
min = db['score'].min()
median = db['score'].median()
mean = db['score'].mean()
print('评分最高值:%s,评分最低值:%.2f,评分中位数:%.2f,评分均值:%.2f'%(max,min,median,mean))
file_csv = pd.read_csv(r'C:UsersliuDesktopargarg04film-csv.txt',sep=';')
file_csv.dropna(axis=1,how='all',inplace=True)
file_csv.drop(file_csv[file_csv['影片类型'].isnull() | file_csv['导演'].isnull()].index.values,inplace=True)
file_csv.drop_duplicates(inplace=True)
file_csv.reset_index(drop=True,inplace=True)
#获取不重复的导演数或影片类型
def get_kinds(str):
only_kinds = []
for i in file_csv[str]:
i = i.strip().replace(')','')
if '·' in i:
kinds = re.split(r',|、|/|',i)
else:
kinds = re.split(r',|、| | |/|(',i)
for k in kinds:
k = k.strip()
if k != '' and k not in only_kinds:
only_kinds.append(k)
return only_kinds
#计算票房总收入
def get_money(kind,str1):
df = pd.DataFrame([])
for n in file_csv[str1]:
if kind in n:
data = file_csv[file_csv[str1].isin([n])]
df = df.append(data)
money = df['票房/万'].sum()
return money
#计算每种票房总收入
def get_total(kinds,str):
every_totals = []
for s in kinds:
ms= get_money(s,str)
every_totals.append(ms)
return every_totals
#从原始数据中筛选出需要的导演和影片类型数据,利用concat()整合
data = pd.concat([file_csv['导演'],file_csv['影片类型']],axis=1).dropna()
#获取每位导演对应的每种影片类型
def get_data(data,str1,str2):
authors,movies= [],[]
for x in range(data[str1].size):
author = data[str1][x].strip().replace(')', '')
if '·' in author:
kinds = re.split(r',|、|/|', author)
else:
kinds = re.split(r',|、| | |/|(', author)
for k in kinds:
k = k.strip()
if k != '' and k != None:
authors.append(k)
movies.append(data[str2][x])
data1 = {
'导演': authors,
'影片类型': movies
}
df = pd.DataFrame(data1)
return df,authors,movies
db1 = get_data(data,'导演','影片类型')
db2 = get_data(db1[0],'影片类型','导演')
movie_kinds = get_kinds('影片类型')
authors = get_kinds('导演')
every_movie = get_total(movie_kinds,'影片类型')
every_author = get_total(authors,'导演')
movie_authors = db2[1]
film_type = db2[2]
#画图
plt.figure(figsize=(8,6))
plt.rcParams['font.sans-serif'] = ['SimHei']
#各种类型片票房收入比较
plt.subplot(131)
plt.xticks(rotation=90)
plt.bar(movie_kinds,every_movie)
# 导演票房收入比较
plt.subplot(132)
plt.xticks(np.arange(len(authors)),authors,rotation=90)
plt.plot(np.arange(len(authors)),every_author)
# 导演执导过的影片类型
plt.subplot(133)
plt.xticks(rotation=90)
plt.scatter(film_type,movie_authors)
plt.rcParams['font.sans-serif']=['SimHei'] #显示中文标签
plt.rcParams['axes.unicode_minus']=False #这两行需要手动设置
plt.show()
plt.close()
1、首先使用pandas的read_csv()方法读取加载数据,然后针对所要求值的一列分别使用特定的方法进行计算,评分最高值可使用max()方法,评分最低值可使用min(),评分中位数可使用median(),评分均值可使用mean() 。
2、对于“各种类型片票房收入比较”可使用条形图进行比较,首先需求出数据文件中所有不重复的影片类型,添加到一个列表中,然后写一个方法分别求出每种影片类型的票房总数,与影片类型列表一一对应添加到另一个列表中。
3、对于“导演票房收入比较”可仿照上述图形做法,首先求出数据文件中所有的导演名字,添加到一个列表中,然后写一个方法分别求出与导演列表一一对应的票房收入总数,添加到另一个列表中。
4、对于“导演执导过的影片类型”可画一个散点图,先处理导演一列,将导演的一列分割成单个导演添加一个列表中,然后将每位导演对应的一种或多种影类型添加到另一个列表中。可由这两个列表重新组成一个pandas,然后再针对影片类型将每位导演名字和其对应的每种影片类型分别添加到两个列表中。
5、文件的打开或创建可使用open()方法,写入文件使用write()方法,格式化字符串使用%链接。
根据程序分析结果可知电影类型为“动作”,“冒险”,“喜剧”,“科幻”,“爱情”的票房收入较高,导演“李仁港”,“周星驰”票房收入较高。
导演们大多热衷于拍摄“动作”,“冒险”,“喜剧”,“剧情”,“爱情”等电影类型。从而可推荐《青春的竞赛》电影类型更适合拍摄成“喜剧”,“爱情”类型,预测评分会在中上评以上。
三.遇到问题
四.解决方案
在这个分析过程中,首先我们应该将文件中所有电影的各个分类,类型等关系电影评分的内容进行一个散点分析,看相对来说是哪一些类型的电影评分更高,更受欢迎,以及各个类型的电影综合评分是多少,根据这些相关内容来进行分析,分析哪些受众更大,评分更好。