xpath是XML路径语言,它可以用来确定xml文档中的元素位置,通过元素的路径来完成对元素的查找。HTML就是XML的一种实现方式,所以xpath是一种非常强大的定位方式。
xpath也分几种不同类型的定位方法。
一种是绝对路径定位。这种定位方式是利用html标签名的层级关系来定位元素的绝对路径,一般从<html>标签开始依次往下进行查找。
如百度搜索框的绝对路径xpath定位可以是这样的:
driver.find_element_by_xpath("/html/body/div[1]/div[1]/div/div[1]/div/form/span[1]/input")
xpath这个方法是非常强大的元素查找方式,使用这种方法几乎可以定位到页面上的任意元素。
优点:基本上是万能的
缺点:因为要遍历所愿元素的路径,执行效率可能比较慢
定位的方法有两种:
“/” 绝对路径,从页面的根元素开始
“//” 相对路径,从页面上的任何节点开始匹配
driver.findElement(By.xpath("//input[@id='kw']")).sendKeys("通过xpath进行定位"); //查找页面上id=kw的input输入框
driver.findElement(By.xpath("//form[1]/input")) //查找页面上第一个form元素内的直接子input元素(即只包括form元素的下一级input元素,使用绝对路径表示,单/号)
driver.findElement(By.xpath("//form[1]//input")) //查找页面上第一个form元素内的所有子input元素(只要在form元素内的input都算,不管还嵌套了多少个其他标签,使用相对路径表示,双//号)
id, name, class name, tag name,
link text, partial link text, xpath, css selector
下面主要介绍一下xpath:
一、xpath基本定位用法
1.1 使用id定位 -- driver.find_element_by_xpath('//input[@id="kw"]')

1.2 使用class定位 -- driver.find_element_by_xpath('//input[@class="s_ipt"]')

1.3 当然 通过常用的8种方式结合xpath均可以定位(name、tag_name、link_text、partial_link_text)以上只列举了2种常用方式哦。
二、xpath相对路径/绝对路径定位
2.1 相对定位 -- 以// 开头 如://form//input[@name="phone"]
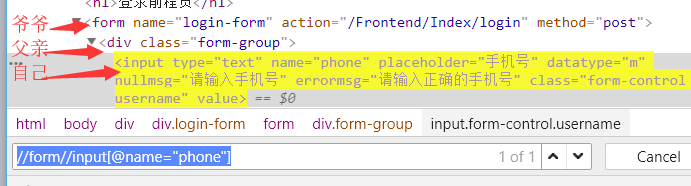
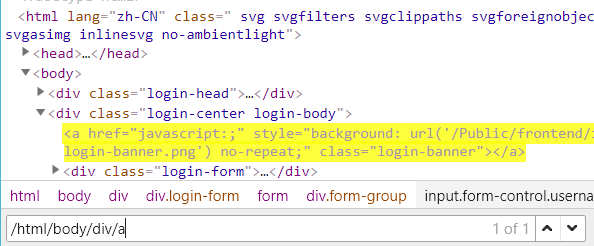
2.2 绝对定位 -- 以/ 开头,但是要从根目录开始,比较繁琐,一般不建议使用 如:/html/body/div/a
三、xpath文本、模糊、逻辑定位
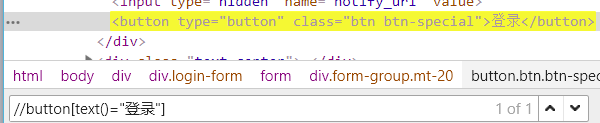
3.1【文本定位】使用text()元素的text内容 如://button[text()="登录"]
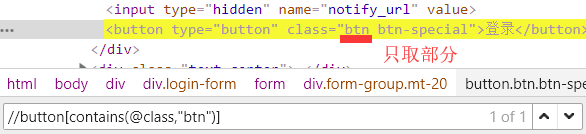
3.2 【模糊定位】使用contains() 包含函数 如://button[contains(text(),"登录")]、//button[contains(@class,"btn")] 除了contains不是=等于
3.3 【模糊定位】使用starts-with -- 匹配以xx开头的属性值;ends-with -- 匹配以xx结尾的属性值 如://button[starts-with(@class,"btn")]、//input[ends-with(@class,"-special")]
3.4 使用逻辑运算符 -- and、or;如://input[@name="phone" and @datatype="m"]
四、xpath轴定位
4.1 轴运算
parent:父节点
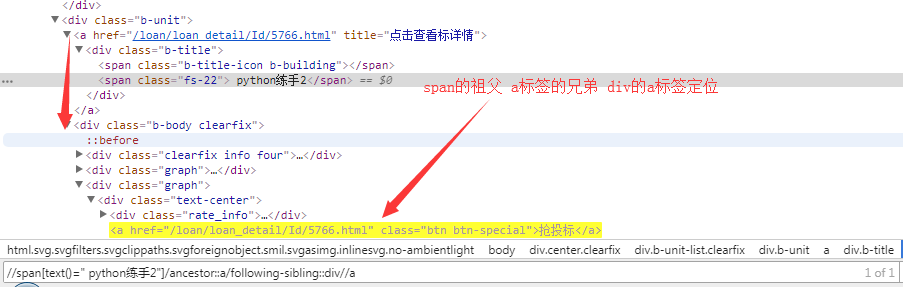
preceding-sibling:当前元素节点标签之前的所有兄弟节点
preceding:当前元素节点标签之前的所有节点
注意:
#定位 找到元素 -- 做到唯一识别
#优先使用id
#舍弃:有下标的出现、有绝对定位的出现、id动态变化时舍弃
selenium提供的xpath定位方法名:
driver.find_element_by_xpath(xpath表达式)
xpath定位是将整个HTML看成一个树形结构。HTML节点为根节点。页面当中节点与其他节点可以有祖先、父辈、兄弟、后代这样的关系存在,类似于我们人类的家庭关系。
xpath基本定位语法


一、绝对定位
特点:1.以单斜杠/开头;2.从页面根元素(HTML标签)开始,严格按照元素在HTML页面中的位置和顺序向下查找
如:
driver.find_element_by_xpath("/html/body/div[2]/div[1]/div/div[1]/div/form/span[1]/input")
二、相对定位
特点:1.以双斜杠//开头;2.不考虑元素在页面当中的绝对路径和位置;3.只考虑是否存在符合表达式的元素即可。
我们一般都使用相对定位来定位元素。下面来介绍下常用的相对定位表达式。
2.1使用标签名+节点属性定位
语法://标签名[@属性名=属性值]
如:
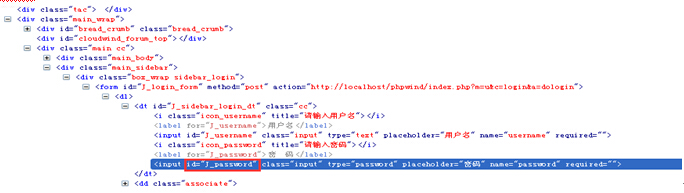
现在要引用id为“J_password”的input元素,可以像下面这样写:
ele_password= driver.find_element_by_xpath("//*[@id='J_login_form']/dl/dt/input[@id='J_password']")
另外一种写法:
|
1
|
ele_password = driver.find_element_by_xpath("//*[@id='J_login_form']/*/*/input[@id='J_password']") |
2.2.组合元素索引(下标)定位
如:
|
1
|
ele_password = driver.find_element_by_xpath("//*[@id='J_login_form']/*/*/input[2]”) |
2.3.通过部分属性值匹配
语法://标签名[contains(@属性名,部分属性值)]、//标签名[starts-with(@属性名,部分属性值)]、//标签名[ends-with(@属性名,部分属性值)]
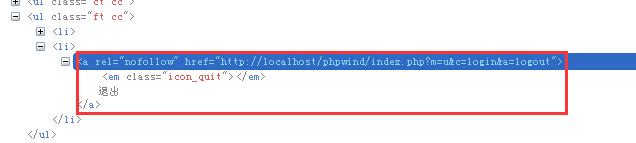
a.starts-with 例子: //input[starts-with(@id,'ctrl')] 解析:匹配以 ctrl开始的属性值
b.ends-with 例子://input[ends-with(@id,'_userName')] 解析:匹配以 userName 结尾的属性值
c.contains() 例子://input[contains(@id,'userName')] 解析:匹配含有 userName 属性值
如下:
|
1
|
driver.find_element_by_xpath(“//a[contains(@href, ‘logout’)]”) |
|
1
|
driver.find_element_by_xpath(“//a[ends-with(@href, ‘logout’)]”) |
|
1
|
driver.find_element_by_xpath(“//a[starts-with(text(), ‘退’)]”) |
2.4.使用文本内容匹配
函数:text()
语法:文本全部匹配://标签名[text()=文本内容]
文本部分匹配-包含://标签名[contains(text(),部分文本内容)]
示例代码如下:
|
1
|
driver.find_element_by_xpath("//a[text(),"退出"]")#文本全部匹配 |
|
1
|
driver.find_element_by_xpath("//a[contains(text(),"出")])#文本部分匹配 |
2.5、使用轴定位表达式
轴运算名称:
ancestor:祖先节点,包括父节点
parent:父节点
preceding:当前元素节点标签之前的所有节点(HTML页面之前的)
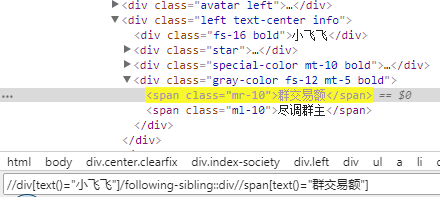
preceding-sibling:当前元素节点标签之前的所有兄弟节点(同级)
following:当前元素节点标签之后的所有节点
following-sibling:当前元素节点标签之后的所有兄弟节点(同级)
使用语法:轴名称::节点名称
前后的定位与之前一致,用/隔开即可。
例如:
|
1
|
//div//table/td/preceding::td/following-sibling::a//[contains(text(),"课程”)]<br>#表示//div//table/td/路径前所有节点中找到节点名称为td的节点,向下同级下的一个兄弟节点包含文本课程 |
目前为止,已经整理了自动化测试Python+Selenium中对于web测试定位页面元素的两种主流,也是最好的定位方式XPATH和CSS定位方式,在我个人看来两个方式都很不错,效率都很高,也很容易解决日常工作中的问题,也能够减少页面的变动对于脚本的维护成本,当然不同问题还需要不同的方式解决,能解决问题的方法都是好方法,希望以后的日子对于定位元素不再是难题。下面我们对这两种定位方式大概做个对比;
XPATH定位和CSS定位很相似,XPATH功能更强大一些吧,但CSS定位方式执行速度更快,鉴于某些浏览器不支持CSS定位方式,并且一般在自动化测试实施过程中使用xpath定位方式要比css更普遍,所以建议大家先掌握xpath,再来看下二者在语法上有什么区别
| 定位元素目标 | XPATH | CSS |
| 所有元素 | //* | * |
| 所有div元素 | //div | div |
| 所有div元素子元素 | //div/* | div>* |
| 根据ID属性获取元素 | //*[@id=''] | div#id |
| 根据class属性获取元素 | //*[@class=''] | div.class |
| 拥有某个属性的元素 | //*[@href=''] | *[href=''] |
| 所有div元素的第一个子元素 | //div/*[1] | div>* :first-child |
| 所有拥有子元素a的div元素 | //div[a] | 无法实现 |
| input的下一个兄弟元素 | //input/following-sibling::[1] | input+* |