阅读目录
- 1.1查看元素的方法
- 1.2根据元素的id属性选择元素
- 1.3根据name属性选择元素
- 1.4. 根据class属性选择元素
- 1.5 根据tag名选择元素
- 1.6 根据链接文本‘link’定位
- 1.7根据xpath路径表达式定位
- 1.8 根据css选择器定位
- 1.9 find_element和find_elements的区别
1.选择元素的方法
对于百度搜索页面,如果我们想自动化输入搜索内容,应该怎么做呢?
这就是在网页中,操控界面元素
web界面自动化,要操控元素,首先需要选择界面元素 ,或者说定位界面元素
就是先告诉浏览器,你要操作哪个界面元素, 让它找到你要操作的界面元素。
我们必须要让浏览器先找到元素,然后才能操作元素。
1.1查看元素的方法
对应web自动化来说,就是要告诉浏览器,你要操作的界面元素是什么。
那么,怎么告诉浏览器呢?
方法就是:告诉浏览器,你要操作的这个web元素的特征。
就是告诉浏览器,这个元素它有什么与众不同的地方,可以让浏览器一下子找到它。
元素的特征怎么查看?
可以使用浏览器的开发者工具栏帮我们查看、选择 web 元素。
请大家用chrome浏览器访问百度,按F12后,点击下图箭头处的Elements标签,即可查看页面对应的HTML 元素
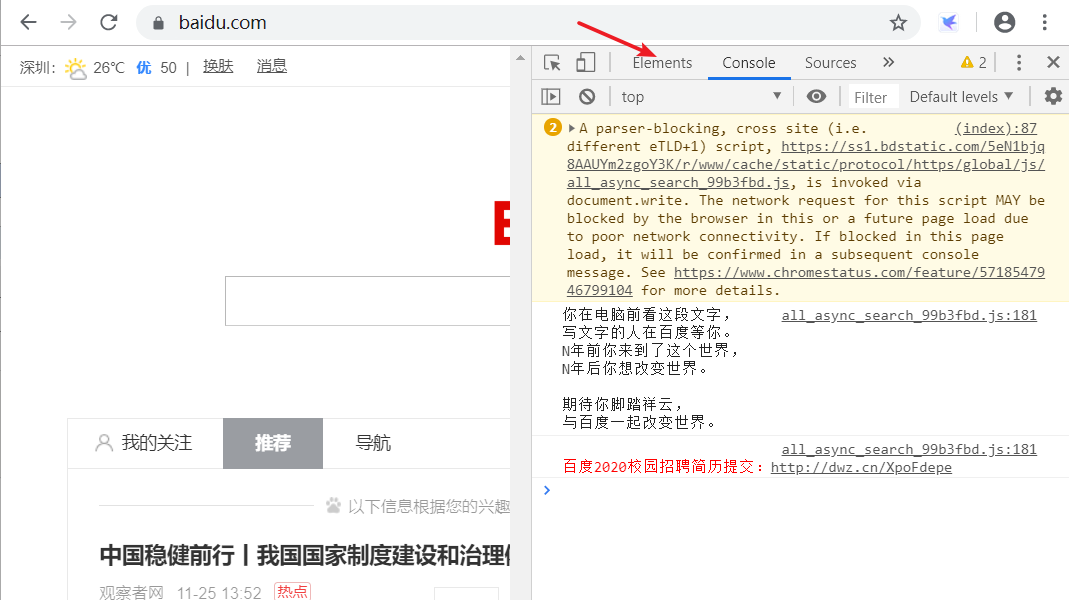
然后,再点击最左边的图标,如下所示

之后,鼠标在界面上点击哪个元素,就可以查看该元素对应的html标签了。
也可以直接在你想要查看的位置,右键选择检查,就可以直接定位到元素了。
1.2 根据元素的id属性选择元素
我们在input中,可以看到有一个属性叫id。
![]()
我们可以把id想象成元素的编号,是用来在html中标记该元素的。根据规范,如果元素有id属性,这个id必须是当前html中唯一的。
所以如果元素有id,根据id选择元素是最简单高效的方式。
这里,百度搜索框元素的id值为kw
下面的代码,可以自动化在浏览器中访问百度,并且在输入框中搜索selenium。
大家可以运行一下看看。
1 from selenium import webdriver 2 from time improt sleep 3 4 #驱动Chrome 5 driver = webdriver.Chrome() 6 #打开百度页面,未登录状态 7 driver.get("https://www.baidu.com/") 8 9 10 # 根据id选择元素,返回的就是该元素对应的WebElement对象 11 element = driver.find_element_by_id('kw') 12 13 # 通过该 WebElement对象,就可以对页面元素进行操作了 14 # 比如输入字符串到 这个 输入框里 15 element.send_keys('selenium ')
其中
-
#驱动Chrome driver = webdriver.Chrome()
前面讲过,driver赋值的是WebDriver类型的对象,我们可以通过这个对象来操控浏览器,比如打开网址、选择界面元素等。
下面的代码
- driver.find_element_by_id('kw')
使用了 WebDriver对象的find_element_by_id方法。
这行代码运行时,就会发起一个请求,通过浏览器驱动转发给浏览器,告诉它,需要选择一个id为kw的元素。
浏览器找到id为kw的元素后,将结果通过浏览器驱动返回给自动化程序,所以find_element_by_id方法会返回一个WebElement 类型的对象。
这个WebElement对象可以看成是对应页面元素的遥控器。
比如 :
调用这个对象的send_keys()方法就可以在对应的元素中输入字符串,
调用这个对象的click()方法就可以点击该元素。
我们通过这个WebElement对象,就可以操控对应的界面元素。
1.3 根据元素的name属性选择元素
我们在input中,可以看到有一个属性叫name。
这里,百度搜索框元素的name值为wd
下面的代码,可以自动化在浏览器中访问百度,并且在输入框中搜索selenium。
大家可以运行一下看看。
1 from selenium import webdriver
2 from time improt sleep
3
4 #驱动Chrome
5 driver = webdriver.Chrome()
6 #打开百度页面,未登录状态
7 driver.get("https://www.baidu.com/")
8
9
10 # 根据id选择元素,返回的就是该元素对应的WebElement对象
11 element = driver.find_element_by_id('wd')
12
13 # 通过该 WebElement对象,就可以对页面元素进行操作了
14 # 比如输入字符串到 这个 输入框里
15 element.send_keys('selenium
')
其中
-
#驱动Chrome driver = webdriver.Chrome()
前面讲过,driver赋值的是WebDriver类型的对象,我们可以通过这个对象来操控浏览器,比如打开网址、选择界面元素等。
下面的代码
- driver.find_element_by_name('wd')
使用了 WebDriver对象的find_element_by_name方法。
这行代码运行时,就会发起一个请求,通过浏览器驱动转发给浏览器,告诉它,需要选择一个id为kw的元素。
浏览器找到id为kw的元素后,将结果通过浏览器驱动返回给自动化程序,所以find_element_by_name方法会返回一个WebElement 类型的对象。
这个WebElement对象可以看成是对应页面元素的遥控器。
我们通过这个WebElement对象,就可以操控对应的界面元素。
比如 :
调用这个对象的send_keys()方法就可以在对应的元素中输入字符串,
调用这个对象的click()方法就可以点击该元素。
我们通过这个WebElement对象,就可以操控对应的界面元素。
1.4 根据class属性选择元素
web自动化的难点和重点之一,就是如何选择我们想要操作的web页面元素。
除了根据元素的id和name,我们还可以根据元素的class属性选择元素。
1 #单元素定位 2 from selenium import webdriver 3 from time import sleep 4 5 6 #main函数,程序运行入口 7 if __name__ == "__main__": 8 #驱动Chrome 9 driver = webdriver.Chrome() 10 #打开百度页面,未登录状态 11 driver.get("https://www.baidu.com/") 12 sleep(2) 13 #页面单元素定位操作 20 #class 属性定位 21 element = driver.find_element_by_class_name("s_ipt") 22 #操作元素->输入 23 element.send_keys("selenium") 24 sleep(2) 25 #元素点击 26 # button = driver.find_element_by_id("su") 27 #复合型class选择其一 28 button = driver.find_element_by_class_name("s_btn") 29 button.click() 30 sleep(2) 31 driver.quit()
#复合型class选择其一(若是class元素内是复合型元素,可以选择任意其中一个)
driver.find_element_by_class_name("s_btn");
若是向查看所选的元素是否有重合一样的,可以按Ctrl+F搜索查看是否有相同元素
1.5 根据tag名选择元素
和class方法差不多的,我们可以通过方法find_elements_by_tag_name,选择所有的tag名为div的元素
from selenium import webdriver driver = webdriver.Chrome() #驱动Chrome driver.get("https://www.baidu.com/") # 根据 tag name 选择元素,返回的是 一个列表 # 里面 都是 tag 名为 div 的元素对应的 WebElement对象 elements = wd.find_elements_by_tag_name('div') # 取出列表中的每个 WebElement对象,打印出其text属性的值 # text属性就是该 WebElement对象对应的元素在网页中的文本内容 for element in elements: print(element.text)
1.6 根据链接文本‘link’选择元素
(1)driver.find_element_by_text()
此种方法是专门用来定位文本链接的,比如百度首页右上角有“新闻”,“hao123”,“地图”等链接
链接元素定位 from selenium import webdriver from time import sleep if __name__ == "__main__": #main函数,程序运行入口 driver = webdriver.Chrome() #驱动Chrome driver.get("https://www.baidu.com/") #打开百度页面,未登录状态 sleep(2) news = driver.find_element_by_link_text("新闻") #链接元素文本信息定位 news.click() #点击 sleep(2) #等待2秒 driver.quit() #退出
(2)部分链接定位(链接元素文本信息模糊定位)-partial_link定位:
driver.find_element_by_partial_link_text()
有时候一个超链接的文本很长很长,我们如果全部输入,既麻烦,又显得代码很不美观,这时候我们就可以只截取一部分字符串,用这种方法模糊匹配了。
1 from selenium import webdriver 2 from time import sleep 3 4 #main函数,程序运行入口 5 if __name__ == "__main__": 6 7 driver = webdriver.Chrome() #驱动Chrome 8 9 driver.get("https://www.baidu.com/") #打开百度页面,未登录状态 10 sleep(2) #等待2秒 11 12 hao = driver.find_element_by_partial_link_text("hao") #链接元素文本信息模糊定位 13 hao.click() #点击 14 sleep(2) 15 driver.quit()
1.7 xpath路劲表达式--xpath定位:driver.find_element_by_xpath()
前面介绍的几种定位方法都是在理想状态下,有一定使用范围的,那就是:在当前页面中,每个元素都有一个唯一的id或name或class或超链接文本的属性,那么我们就可以通过这个唯一的属性值来定位他们。
但是在实际工作中并非有这么美好,有时候我们要定位的元素并没有id,name,class属性,或者多个元素的这些属性值都相同,又或者刷新页面,这些属性值都会变化。那么这个时候我们就只能通过xpath或者CSS来定位了。

from selenium import webdriver
from time import sleep
# 启动浏览器
driver = webdriver.Chrome()
# 打开百度首页
driver.get(r'https://www.baidu.com/')
# 通过xpath定位搜索框,并输入selenium
driver.find_element_by_xpath("//*[@id='kw']").send_keys('selenium')
# 等待2秒
sleep(2)
# 退出
driver.quit()
1.8 css选择器-css定位:driver.find_element_by_css_selector()
这种方法相对xpath要简洁些,定位速度也要快些,但是学习起来会比较难理解,这里只做下简单的介绍。
from selenium import webdriver
from time import sleep
# 启动浏览器
driver = webdriver.Chrome()
# 打开百度首页
driver.get(r'https://www.baidu.com/')
# 通过css定位搜索框,并输入selenium
driver.find_element_by_css_selector('#kw').send_keys('selenium')
# 等待2秒
sleep(2)
# 退出
driver.quit()
1.9 find_elemen和find_elements的区别
元素定位的方法有2个(单元素和多元素)
#id 属性定位
driver.find_element_by_id("kw") 返回值是WebElement //此方法是获取单一的页面元素
driver.find_elements_(By.args) 返回值是list<WebElement> //此方法是获取多个页面元素;例如:获取一组复选框,然后都打上√号
在选择器的选用时,要记得获取一个还是多个,要区分开 find_elements 还是 find_element 。这个s容易忽略。
使用find_elements选择的是符合条件的所有元素,如果没有符合条件的元素,返回空列表。
使用find_element选择的是符合条件的第一个 元素, 如果没有符合条件的元素, 抛出 NoSuchElementException异常。