hadoop:数据流转图(基于hadoop 0.18.3):通过一个最简单的例子来说明hadoop中的数据流转。
hadoop:数据流转图(基于hadoop 0.18.3):
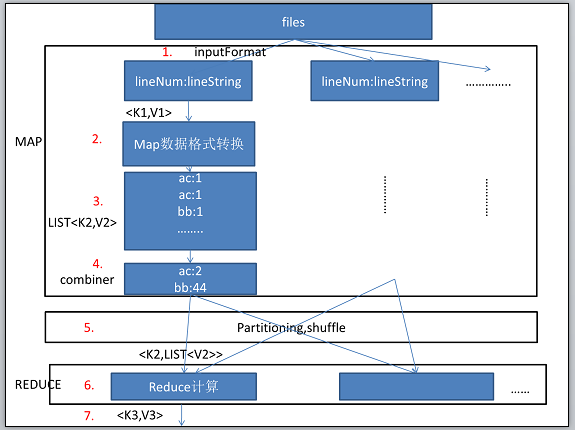
这里使用一个例子说明hadoop中的数据流转过程,这个例子是统计一些文章中词汇的总数。首先files表示这些需要统计词汇的文章。
首先,hadoop会把初始数据分配到各个机器的mapper任务中,图中的数字表示数据的依次流向步骤。
1.格式化输入,默认情况下,hadoop会使用 TextInputFormate,也就是按照行号作为key,行的字符串作为value.map函数的输入形式是<K1,V1>。
2.map函数如下。例如统计词汇,我们可以这么写。
public void map(LongWritable key,Text Value,OutputCollector<Text,Inwritable> output,Reporter reporter){//output为map函数的输出。
String line = value.toString();//每行的值
StringTokenizer itr = new StringTokenizer(line);//根据空格分词
while(itr.hasMoreTokens()){
output.collect( new Text().set(itr.nextToken()),new IntWritable(1));//输出 ,key为单词,value为1.
}
}
3.map函数的输出的形式是List<k2,v2>,如上面的output参数。把每个词记录下来,并且设置value为1.表示这个词出现过一次,后面统计的时候再把相同的key的value的总数计算出来。
4.combiner过程(非必要),可以理解为本地Reduce,在本地先进行一次计算,把相同key的键对汇总一下,例如‘ac’这个词汇一共出现了两次,这里输出就是<“ac”,2>。
5.partitioner主要是把map输出的结果进行分配,分配到不同机器的reduce中,让reduce处理。那么根据什么来分配呢?hadoop中默认是根据key的hash值进行分配。这个过程叫做洗牌过程。
6.reduce函数,入参为<k2,List<v2>>,在map中的output的格式是List<k2,v2>,经过shuffling过程之后,经过分区再组合,就成了<k2,List<v2>>。对应分词统计的例子,key2对应的就是某个词,List<v2>对应的就是不同机器的map函数得出的某个词汇的总数的集合。输出的形式为<k3,v3>。词汇统计的reduce方法如下:
public void reduce(Text key,Interator<InWritable> values,OutputCollector<Text,IntWritable> output,Reporter reporter) throws IOException{
int sum = 0;
while(values.hasNext()){//求和
sum += values.next().get();
}
output.collect(key,new IntWritable(sum));//输出
}
7.输出的格式为<k3,v3>这里可以作为下一个map函数的入参。
inputFormat:默认情况hadoop会使用TextInputFormat来作为输入的格式化工具,key会是行号,这个行号一般来说对我们没有什么用。当我们需要根据行的分隔符来区分key和value的时候,例如有这样格式的数据,”班级 姓名“(班级姓名之间使用制表符),我们需要使用班级作为key,姓名作为value,我们就可以使用KeyValueTextInputFormat ,默认分隔符为制表符( ),我们可以通过key.value.separator.in.input.line来设定分隔符。根据其他需求还可能用到SquenceFileInputFormat<K,V>,NLineInputFormat。
partitioning:hadoop中默认的HashJPartitioner有时候可以不符合我们的需求,就可以实现Partioner<K,V>,来自己实现Partioner。Partioner接口需要实现两个方法,configure() 和 getPartition()。configure()方法将作业的配置应用在partitioner上,而后者返回一个介于0和reduce任务之间的整数。