
Kudu自身的架构,部分借鉴了Bigtable/HBase/Spanner的设计思想。论文的作者列表中,有几位是HBase社区的Committer/PBC成员,因此,在论文中也能很深刻的感受到HBase对Kudu设计的一些影响
Kudu的底层数据文件的存储,未采用HDFS这样的较高抽象层次的分布式文件系统,而是自行开发了一套可基于Table/Tablet/Replica视图级别的底层存储系统。这套实现基于如下的几个设计目标:
• 可提供快速的列式查询。
• 可支持快速的随机更新
• 可提供更为稳定的查询性能保障。
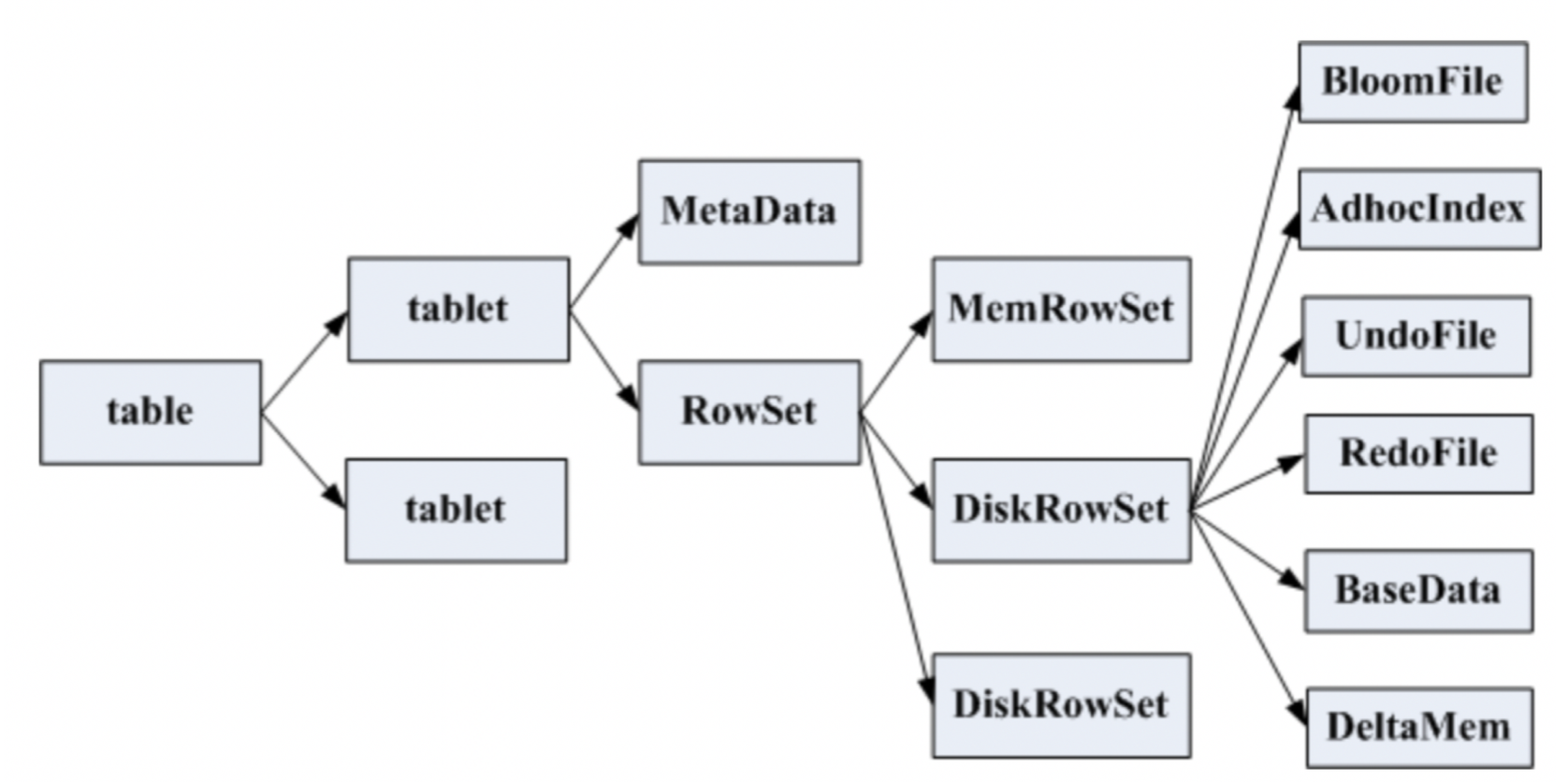
一张表会分成若干个tablet,每个tablet包括MetaData元信息及若干个RowSet,RowSet包含一个MemRowSet及若干个DiskRowSet,DiskRowSet中包含一个BloomFile、Ad_hoc Index、BaseData、DeltaMem及若干个RedoFile和UndoFile(UndoFile一般情况下只有一个)。
MemRowSet:用于新数据insert及已在MemRowSet中的数据的更新,一个MemRowSet写满后会将数据刷到磁盘形成若干个DiskRowSet。(默认是1G或者或者120S)
DiskRowSet用于老数据的变更(mutation),后台定期对DiskRowSet做compaction,以删除没用的数据及合并历史数据,减少查询过程中的IO开销。
BloomFile根据一个DiskRowSet中的key生成一个bloom filter,用于快速模糊定位某个key是否在DiskRowSet中存在。
Ad_hocIndex是主键的索引,用于定位key在DiskRowSet中的具体哪个偏移位置。
BaseData是MemRowSet flush下来的数据,按列存储,按主键有序。
UndoFile是基于BaseData之前时间的历史数据,通过在BaseData上apply UndoFile中的记录,可以获得历史数据。
RedoFile是基于BaseData之后时间的变更(mutation)记录,通过在BaseData上apply RedoFile中的记录,可获得较新的数据。
DeltaMem用于DiskRowSet中数据的变更mutation,先写到内存中,写满后flush到磁盘形成RedoFile
为了实现如上目标,Kudu参考了一种类似于Fractured Mirrors的混合列存储架构。Tablet在底层被进一步细分成了一个称之为RowSets的单元:
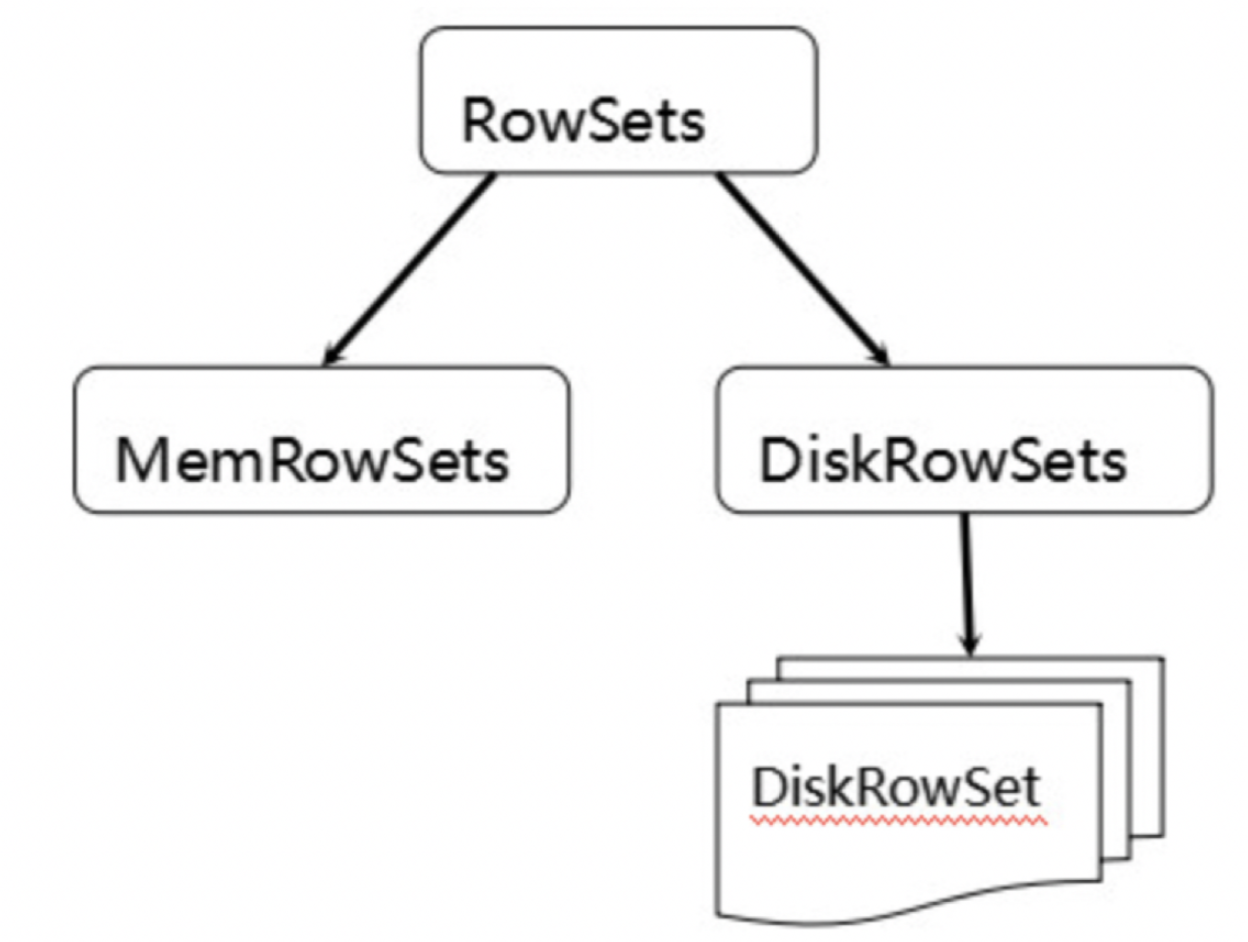
MemRowSets可以对比理解成HBase中的MemStore, 而DiskRowSets可理解成HBase中的HFile。MemRowSets中的数据按照行试图进行存储,数据结构为B-Tree。 MemRowSets中的数据被Flush到磁盘之后,形成DiskRowSets。 DisRowSets中的数据,按照32MB大小为单位,按序划分为一个个的DiskRowSet。 DiskRowSet中的数据按照Column进行组织,与Parquet类似。 这是Kudu可支持一些分析性查询的基础。每一个Column的数据被存储在一个相邻的数据区域,而这个数据区域进一步被细分成一个个的小的Page单元,与HBase File中的Block类似,对每一个Column Page可采用一些Encoding算法,以及一些通用的Compression算法。 既然可对Column Page可采用Encoding以及Compression算法,那么,对单条记录的更改就会比较困难了。 前面提到了Kudu可支持单条记录级别的更新/删除,是如何做到的? 与HBase类似,也是通过增加一条新的记录来描述这次更新/删除操作的。一个DiskRowSet包含两部分数据:基础数据(Base Data),以及变更数据(Delta Stores)。更新/删除操作所生成的数据记录,被保存在变更数据部分。
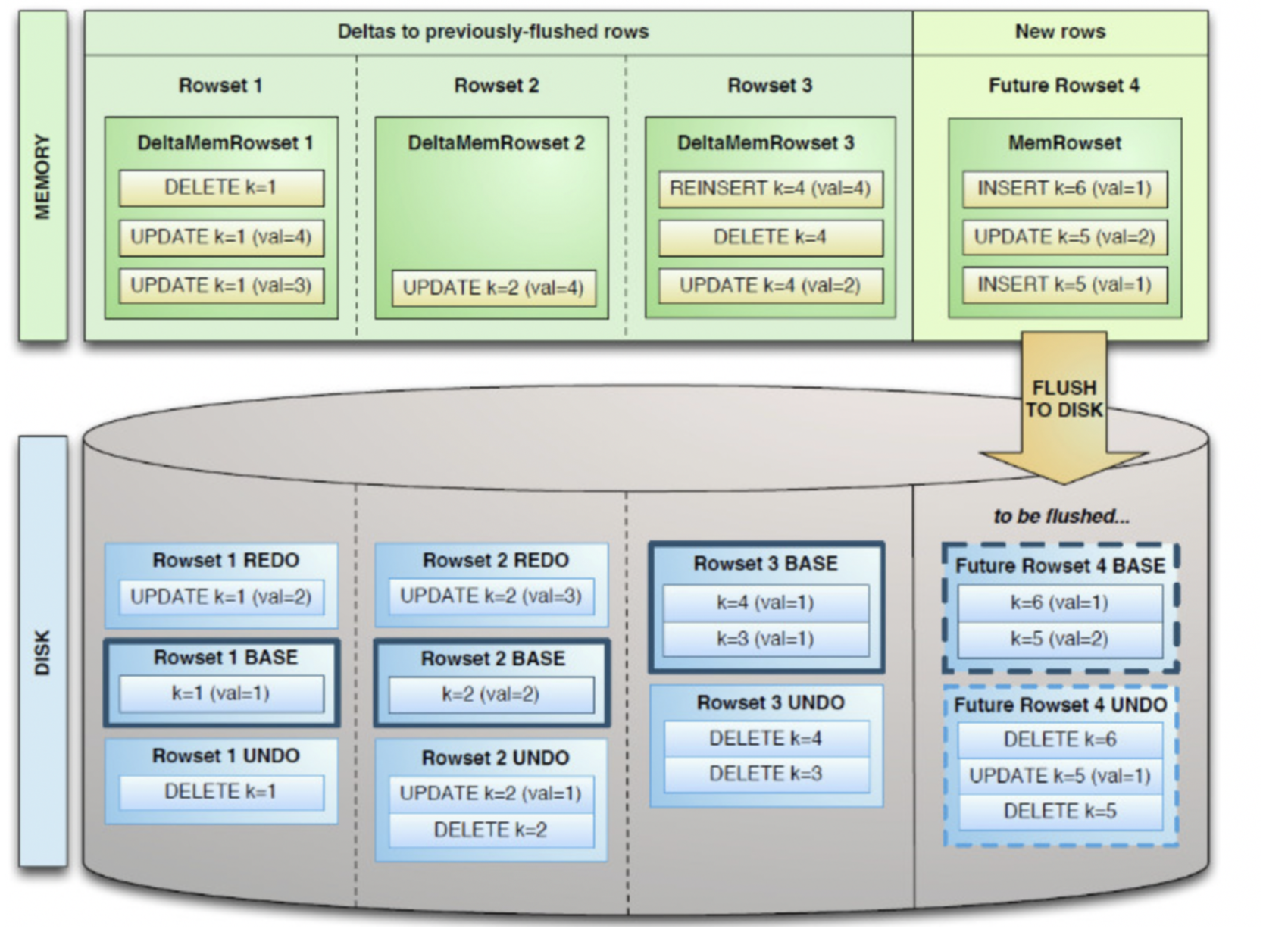
从上图(源自Kudu的源工程文件)来看:
Delta数据部分应该包含REDO与UNDO两部分,这里的REDO与UNDO与关系型数据库中的REDO与UNDO日志类似(在关系型数据库中,REDO日志记录了更新后的数据,可以用来恢复尚未写入Data File的已成功事务更新的数据。
而UNDO日志用来记录事务更新之前的数据,可以用来在事务失败时进行回滚),但也存在一些细节上的差异:
• REDO Delta Files包含了Base Data自上一次被Flush/Compaction之后的变更值。REDO Delta Files按照Timestamp顺序排列。 • UNDO Delta Files包含了Base Data自上一次Flush/Compaction之前的变更值。这样才可以保障基于一个旧Timestamp的查询能够看到一个一致性视图。UNDO按照Timestamp倒序排列。