
1、spark的ThriftServer介绍
spark的thriftServer是在hiveServer2基础上实现的 , 提供了Thrift服务
,也就是提供了远程的ODBC服务
用户画像,对受众目标进行筛选 , 数据源是在hive数仓的;
后来改用了thriftServer,采用jdbc的方式,直接去读取数据仓库内容,性能在一定程度得到了提升
2、ThriftServer的缺陷
我们使用了spark的ThriftServer,虽然性能得到了提升,但是安全并没有得到保障
因为spark的ThriftServer并没有 类似hive里面的服务自主发现功能;
所以spark的thriftServer就出现了单点问题
3、ThriftServer的解决
解决这个问题,首先要搞懂ThriftServer的启动流程大概 什么样子
3.1、ThriftServer的启动流程
1):我们在启动thrift server,是通过脚本start-thriftserver.sh

2):然后在进入spark-daemon.sh 这个脚本 , 携带CLASS参数进行启动


3):然后看bin/spark-submit.sh

然后sparksubmit,会去执行一个叫做:HiveThriftServer2的类;
3.2、解决单点问题
3.2.1、内部流程说明
1):首先进入HiveThriftServer2,会执行main函数

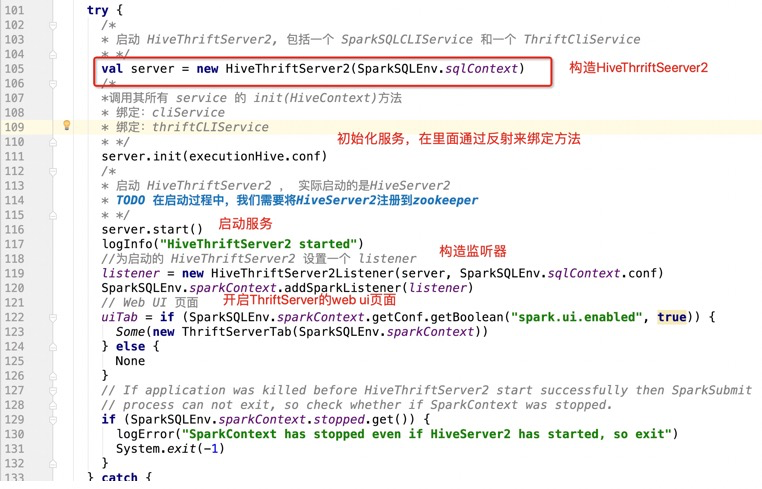
这样,最后在server.start() 这里,就启动了
启动的服务是HiveThriftServer2
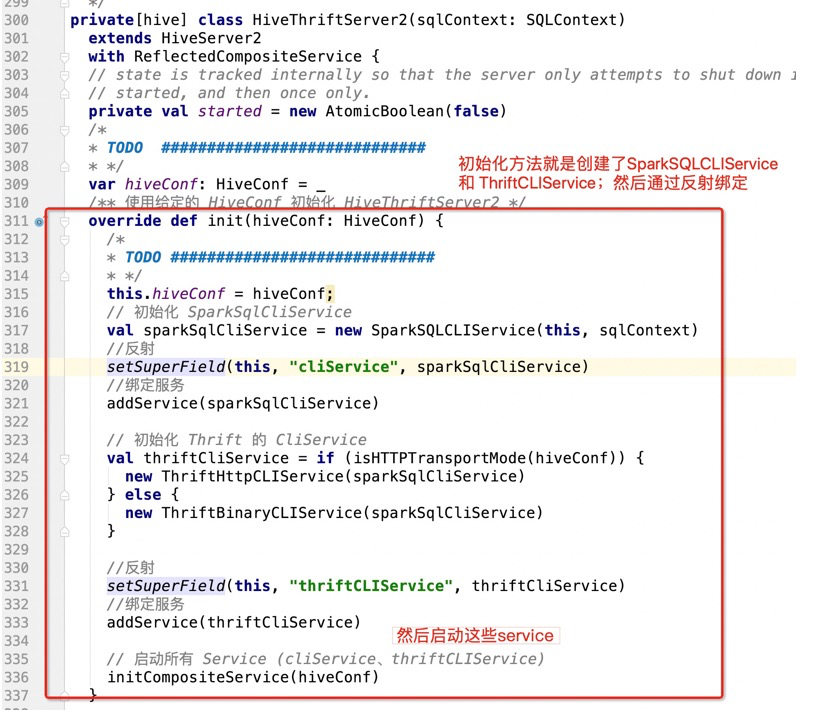
其中的绑定服务addService,就是在ArrayList去维护当前的service

所以在调用initCompositeService,开始启动服务,会最终调用到HiveServer2
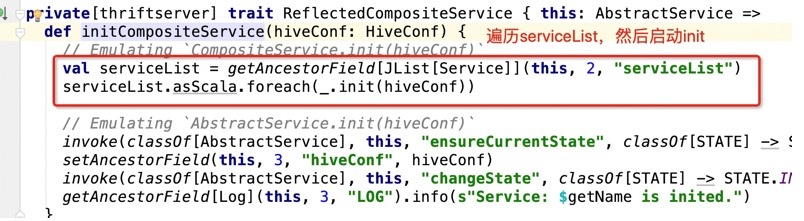
这个init方法是个接口:
直接看实现,是在HiveService2的init方法:

那么最后我们这个流程是怎么启动的呢?
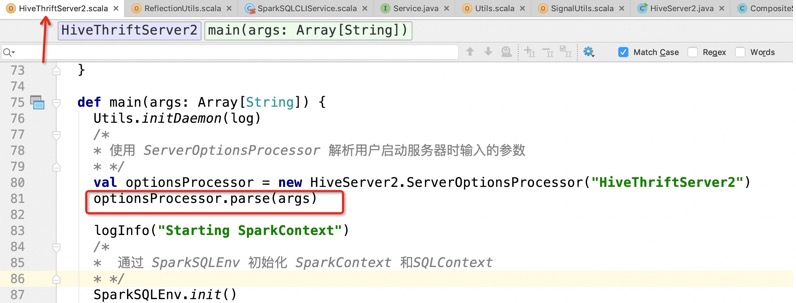
然后我们 查看parse方法
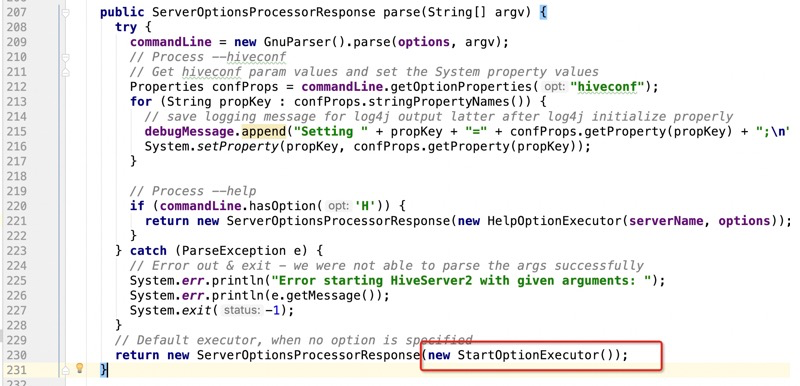
然后查看StartOptionExecutor
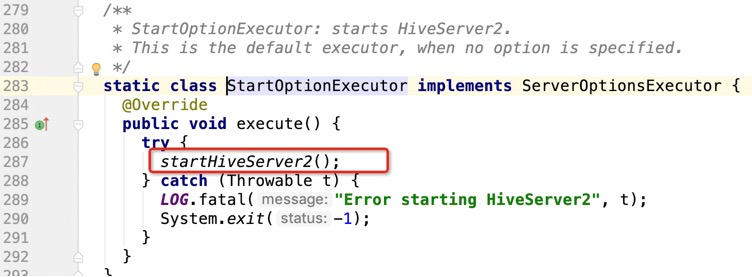
然后查看startHiveServer2

那么我们遇到的问题是sparkThriftServer存在单点问题 ,但是尴尬的是,spark本身没有给出解决方案,
但是hive是有的,hive支持了hiveServer2服务的高可用;
通过配置就可以实现;
所以我们可以通过zookeeper来实现spark的 ThriftServer的高可用
3.2.3、在HiveThriftServer2启动的时候,让他在zookeeper里面注册一份信息,代表当前第一个实例
所以需要在:
1):实例化一个全局的hiveConf,用来调用hive的一些回调函数,
主要是可以去hive-site.xml里面拿配置文件
<property>
<name>hive.server2.support.dynamic.service.discovery</name>
<value>true</value>
</property>
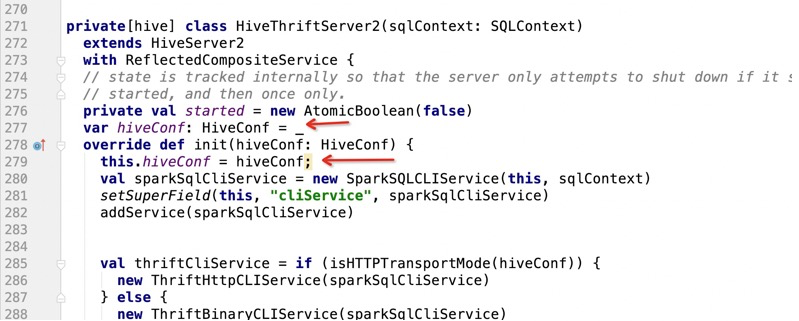
2):在启动HiveThriftServer2的时候,把hiveServer2注册到zookeeper中
HiveThriftServer2 实现了HIveServer2
而且是使用反射处理的(早期hive开发的时候,就已经在内部使用private,可能没想过别人 会调用)
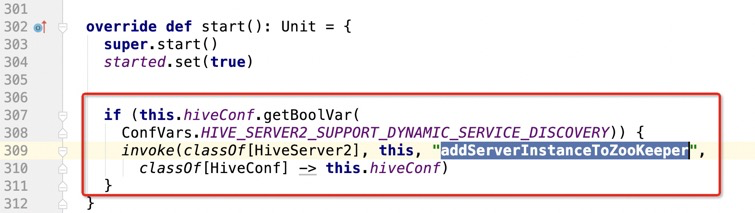
3):在停止HiveThriftServer2的时候,把hiveserrver2从zookeeper中注销掉

3.3、修改hiveServer2源码
1):添加获取thriftServer的IP:HOST
拿到thriftServer的域名

拼接ThriftServer的地址

2):对zookeeper做kuberos认证


4):控制是否需要重新在zookeeper上注册hiveServer2

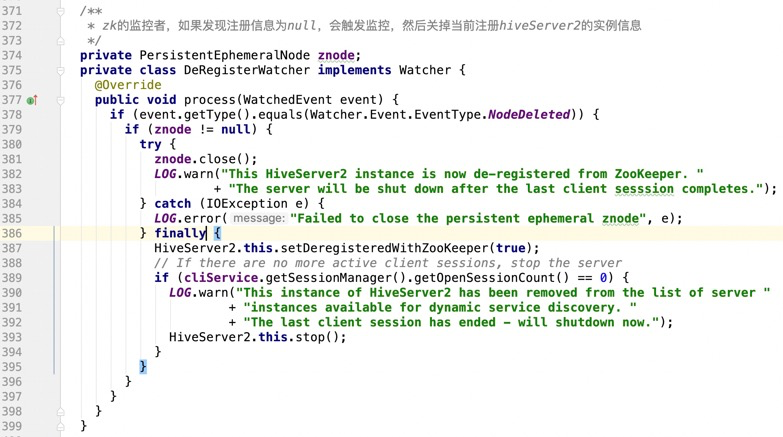
6):把服务注册到zookeeper中
1 private CuratorFramework zooKeeperClient; 2 private String znodePath; 3 /** 4 * 把服务注册到zookeeper中(通过反射调用) 5 * @param hiveConf 6 * @throws Exception 7 */ 8 private void addServerInstanceToZooKeeper(HiveConf hiveConf) throws Exception { 9 //从hiveConf中获取zookeeper地址 10 String zooKeeperEnsemble = ZooKeeperHiveHelper.getQuorumServers(hiveConf); 11 //从hive-site.xml中获取hive.server2.zookeeper.namespace的配置信息 12 String rootNamespace = hiveConf.getVar(HiveConf.ConfVars.HIVE_SERVER2_ZOOKEEPER_NAMESPACE); 13 //获取用户提供的thriftServer地址(IP:PORT) node01:10001 , node02:10002 14 String instanceURI = getServerInstanceURI(); 15 //做Kerberos认证 16 setUpZooKeeperAuth(hiveConf); 17 //获取hive连接zookeeper的session超时时间 18 int sessionTimeout = 19 (int) hiveConf.getTimeVar(HiveConf.ConfVars.HIVE_ZOOKEEPER_SESSION_TIMEOUT, 20 TimeUnit.MILLISECONDS); 21 //hive连接zookeeper的等待时间 22 int baseSleepTime = 23 (int) hiveConf.getTimeVar(HiveConf.ConfVars.HIVE_ZOOKEEPER_CONNECTION_BASESLEEPTIME, 24 TimeUnit.MILLISECONDS); 25 //hive连接zookeeper的最大重试次数 26 int maxRetries = hiveConf.getIntVar(HiveConf.ConfVars.HIVE_ZOOKEEPER_CONNECTION_MAX_RETRIES); 27 // 获取zookeeper客户端 28 zooKeeperClient = 29 CuratorFrameworkFactory.builder().connectString(zooKeeperEnsemble) 30 .sessionTimeoutMs(sessionTimeout).aclProvider(zooKeeperAclProvider) 31 .retryPolicy(new ExponentialBackoffRetry(baseSleepTime, maxRetries)).build(); 32 //启动zookeeper客户端 33 zooKeeperClient.start(); 34 //TODO 在zookeeper上根据rootNamespace创建一个空间(用来存储数据的文件夹) 35 try { 36 zooKeeperClient.create().creatingParentsIfNeeded().withMode(CreateMode.PERSISTENT) 37 .forPath(ZooKeeperHiveHelper.ZOOKEEPER_PATH_SEPARATOR + rootNamespace); 38 LOG.info("Created the root name space: " + rootNamespace + " on ZooKeeper for HiveServer2"); 39 } catch (KeeperException e) { 40 if (e.code() != KeeperException.Code.NODEEXISTS) { 41 LOG.fatal("Unable to create HiveServer2 namespace: " + rootNamespace + " on ZooKeeper", e); 42 throw e; 43 } 44 } 45 //TODO 把hiveserver2的信息注册到rootNamespace下: 46 // serverUri=cdh1:10001;version=1.2.1.spark2;sequence=0000000005 47 try { 48 String pathPrefix = 49 ZooKeeperHiveHelper.ZOOKEEPER_PATH_SEPARATOR + rootNamespace 50 + ZooKeeperHiveHelper.ZOOKEEPER_PATH_SEPARATOR + "serverUri=" + instanceURI + ";" 51 + "version=" + HiveVersionInfo.getVersion() + ";" + "sequence="; 52 byte[] znodeDataUTF8 = instanceURI.getBytes(Charset.forName("UTF-8")); 53 //创建一个临时节点 54 znode = 55 new PersistentEphemeralNode(zooKeeperClient, 56 PersistentEphemeralNode.Mode.EPHEMERAL_SEQUENTIAL, pathPrefix, znodeDataUTF8); 57 znode.start(); 58 59 //给定临时节点创建的超时时间,如果超过120秒,则抛异常 60 long znodeCreationTimeout = 120; 61 if (!znode.waitForInitialCreate(znodeCreationTimeout, TimeUnit.SECONDS)) { 62 throw new Exception("Max znode creation wait time: " + znodeCreationTimeout + "s exhausted"); 63 } 64 65 66 setDeregisteredWithZooKeeper(false); 67 znodePath = znode.getActualPath(); 68 // TODO 添加zk的watch , 如果服务不见了,需要第一时间watche到 69 if (zooKeeperClient.checkExists().usingWatcher(new DeRegisterWatcher()).forPath(znodePath) == null) { 70 // No node exists, throw exception 71 throw new Exception("Unable to create znode for this HiveServer2 instance on ZooKeeper."); 72 } 73 LOG.info("Created a znode on ZooKeeper for HiveServer2 uri: " + instanceURI); 74 } catch (Exception e) { 75 LOG.fatal("Unable to create a znode for this server instance", e); 76 if (znode != null) { 77 znode.close(); 78 } 79 throw (e); 80 } 81 }
7):移除znode,代表当前程序关闭
1 //移除znode,代表当前程序关闭(通过反射调用) 2 private void removeServerInstanceFromZooKeeper() throws Exception { 3 setDeregisteredWithZooKeeper(false); 4 5 if (znode != null) { 6 znode.close(); 7 } 8 zooKeeperClient.close(); 9 LOG.info("Server instance removed from ZooKeeper."); 10 }
3:修改spark-daemon.sh脚本

4、maven打包
mvn -Pyarn -Phadoop-2.6 -Dhadoop.version=2.6.0 -Phive -Phive-thriftserver -Dscala-2.11 -DskipTests clean package
但是以上操作只是编译出了一份文件,并不是可运行的包,所以需要稍微改一下命令:
./make-distribution.sh --name 2.6.0-cdh5.14.0 --tgz -Pyarn -Phive -Phive-thriftserver -Phadoop-2.6 -Dscala-2.11 -Dhadoop.version=hadoop-2.6.0-cdh5.14.0 -DskipTests clean package
5、将新生成的spark-hive-thriftserver_2.11-2.1.0.jar替换spark/jars 下面的同名包
6、修改hive/conf和spark/conf下面的配置文件:hive-site.xml
在里面添加如下配置:
<property>
<name>hive.server2.support.dynamic.service.discovery</name>
<value>true</value>
</property>
<property>
<name>hive.server2.zookeeper.namespace</name>
<value>hiveserver2_zk</value>
</property>
<property
<name>hive.zookeeper.quorum</name>
<value>cdh1:2181,cdh2:2181,cdh3:2181</value>
</property>
<property>
<name>hive.zookeeper.client.port</name>
<value>2181</value>
</property>
<property>
<name>hive.server2.thrift.bind.host</name>
<value>cdh1</value>
</property>
<property>
<name>hive.server2.thrift.port</name>
<value>10003</value>
</property>
7、验证
分别在某台机器上执行两次:
sbin/start-thriftserver.sh --master yarn --conf spark.driver.memory=1G --executor-memory 512m --num-executors 1 --hiveconf hive.server2.thrift.port=10001/10002
2):在zookeeper中可以看到如下信息:

3):通过beeline模拟jdbc去查询hive
[root@cdh2 spark-2.1.0-bin-2.6.0-cdh5.14.0]# beeline Beeline version 1.2.1.spark2 by Apache Hive beeline> !connect jdbc:hive2://cdh1:2181,cdh2:2181,cdh3:2181/default;serviceDiscoveryMode=zooKeeper;zooKeeperNamespace=hiveserver2_zk
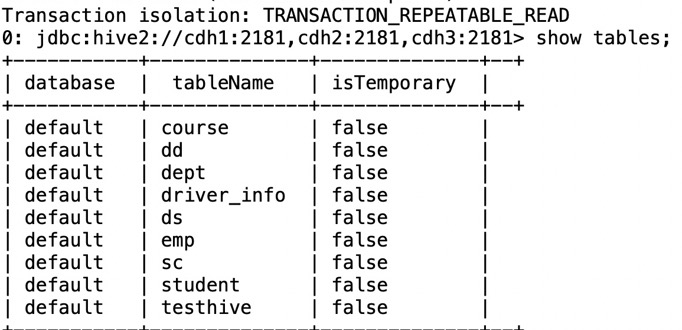
去页面观察:
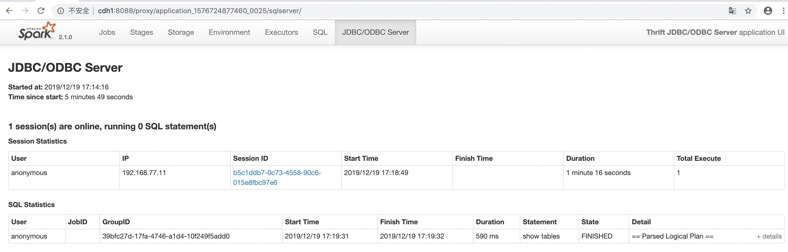
杀掉一个thriftServer

在重新登录beeline,在做查询,可以发现依然可以查询
