前提是有 rman 备份。
rman 全备 run 块:
run{ allocate channel c1 type disk; allocate channel c2 type disk; allocate channel c3 type disk; backup as compressed backupset Database Format '/u01/backup/rman/20211220/bak_all_db_%s_%p_%T' filesperset=4; #归档当前的重做日志(redolog)文件 sql 'alter system archive log current'; #备份归档日志 backup archivelog all format '/u01/backup/rman/20211220/bak_arch_%s_%p_%T' delete input; #备份控制文件 backup current controlfile format '/u01/backup/rman/20211220/bak_ctl_%s_%p_%T'; #备份 spfile backup spfile format '/u01/backup/rman/20211220/bak_sp_%s_%p_%T'; crosscheck backup; #检查备份是否存在于备份介质 crosscheck archivelog all; #删除过期备份 delete noprompt obsolete; #删除不在备份介质的备份记录 delete noprompt expired backup; delete noprompt backup of database completed before 'sysdate -15'; delete noprompt backup of archivelog all completed before 'sysdate -5'; delete noprompt expired archivelog all; #释放通道 release channel c1; release channel c2; release channel c3; }
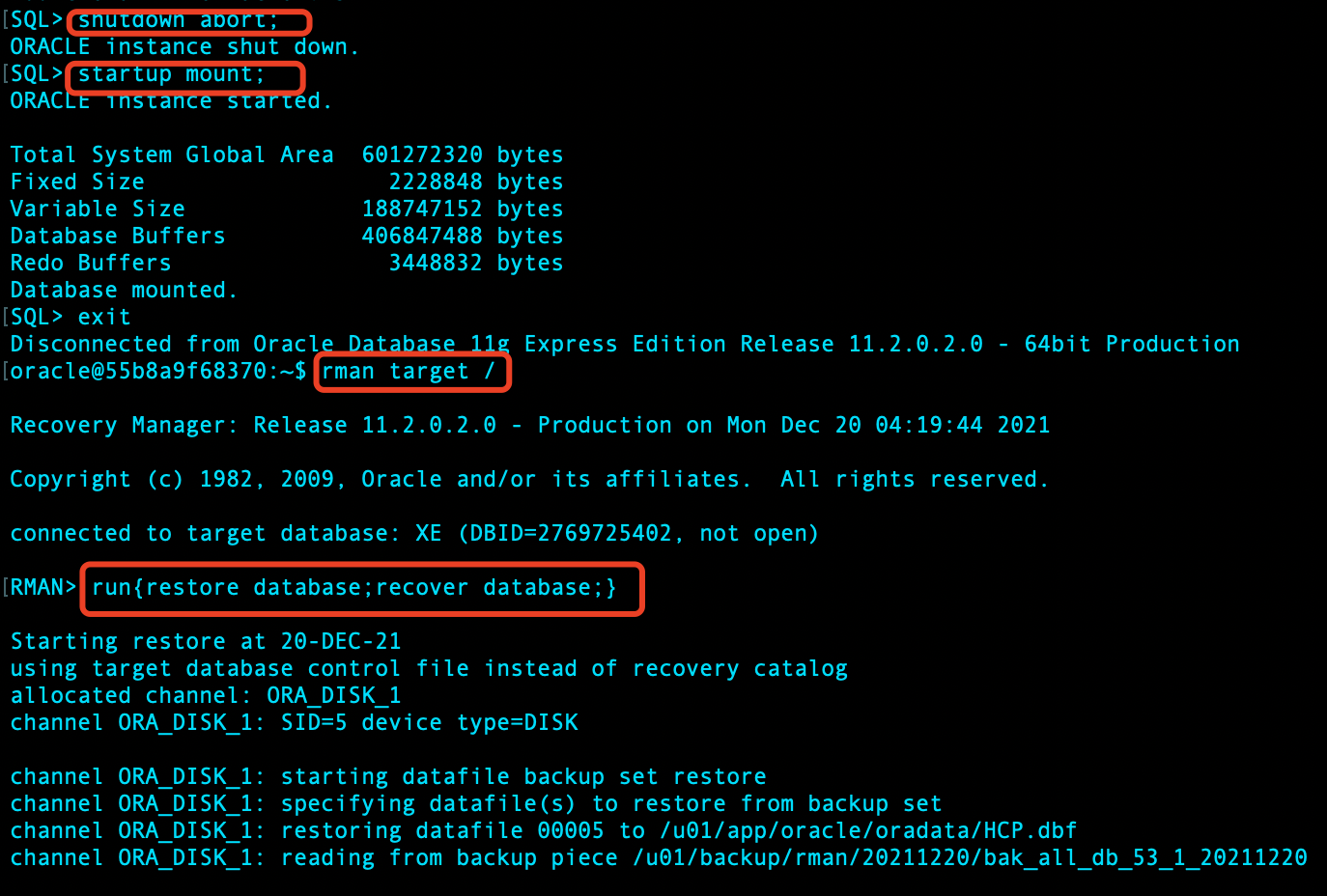
rman 恢复 run 块:
run{restore database;recover database;}
rman 恢复到某时间点 run 块:
run{set until time "to_date('2021-12-20 11:32:01','yyyy-mm-dd hh24:mi:ss')";restore database;recover database;}
测试情形 1 ,数据文件 (HCP.dbf) 被物理删除
可以看到,靶场环境,HCP 用户下有一张 test 表:
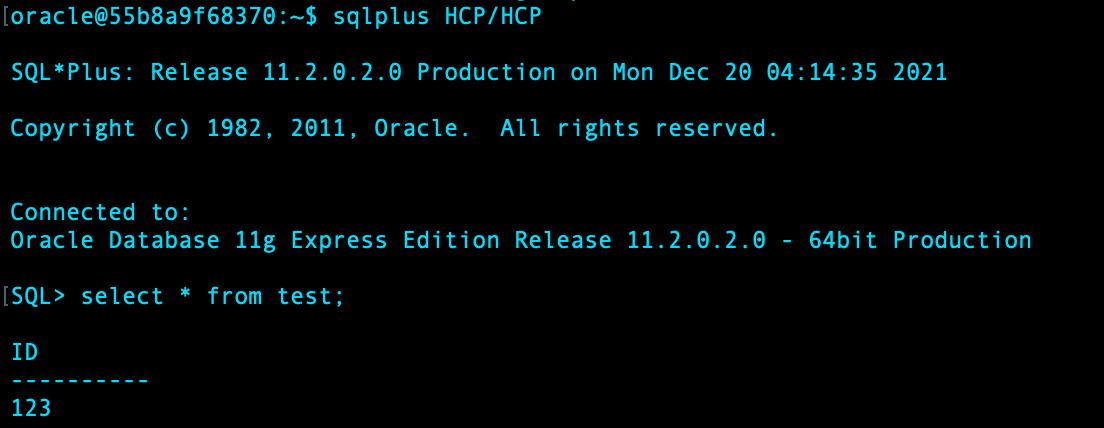
物理删除数据文件:
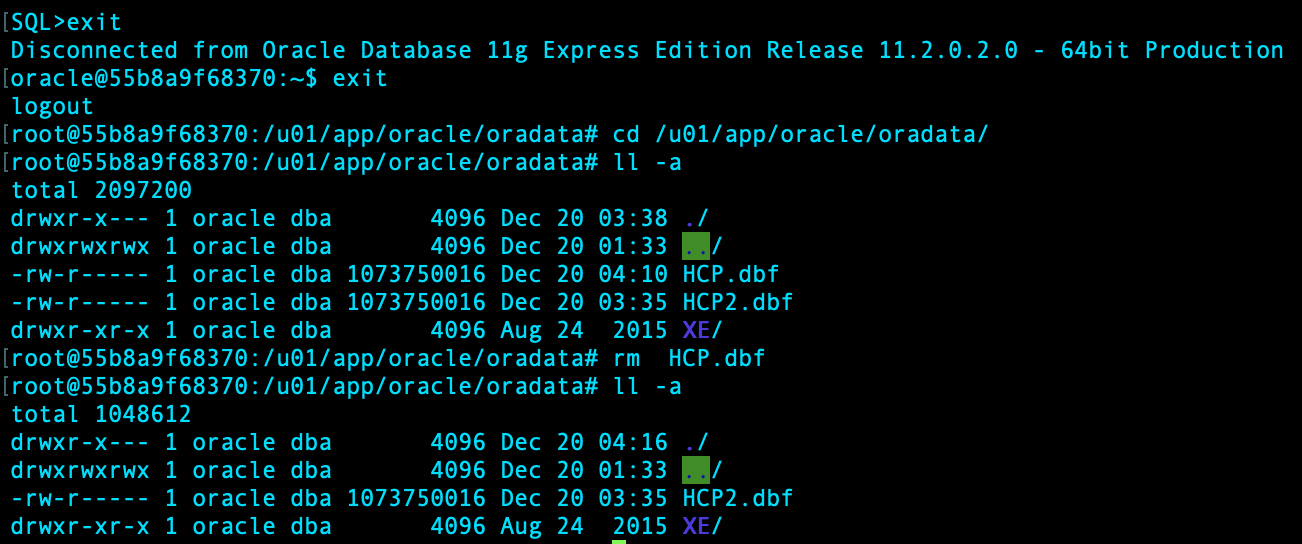
整个数据库已经无法 shutdown immediate:

shutdown abort;并启动到 mount 进行数据恢复:
open 数据库,发现 test 表已恢复:
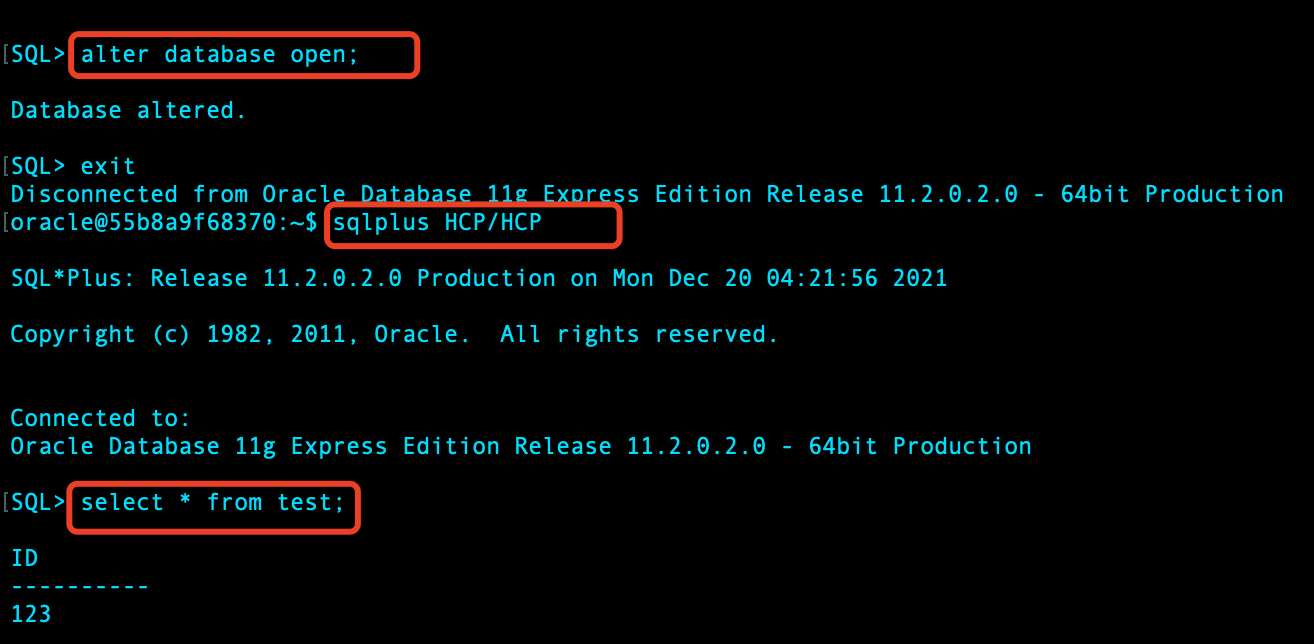
查看物理文件,发现表空间物理文件也已恢复:
测试情形 2,数据文件 (HCP.dbf) 被手工误删除删除
在 test 表中新插入 666 后,进行全备:
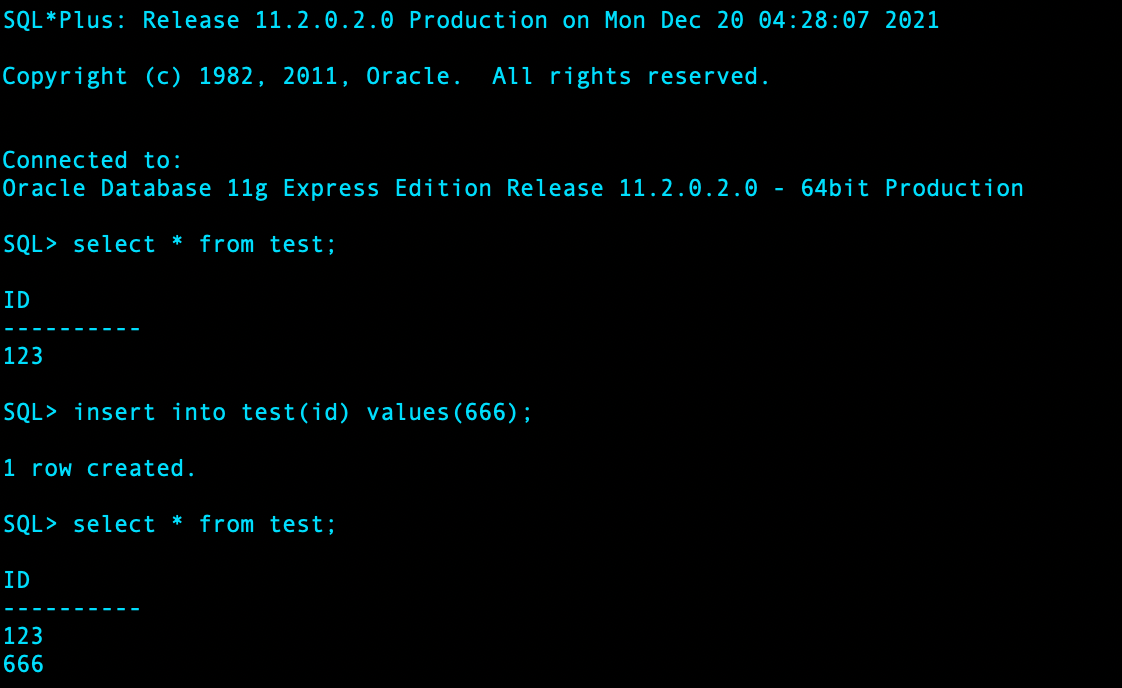
手工删除表空间及物理文件,test 表已不存在:
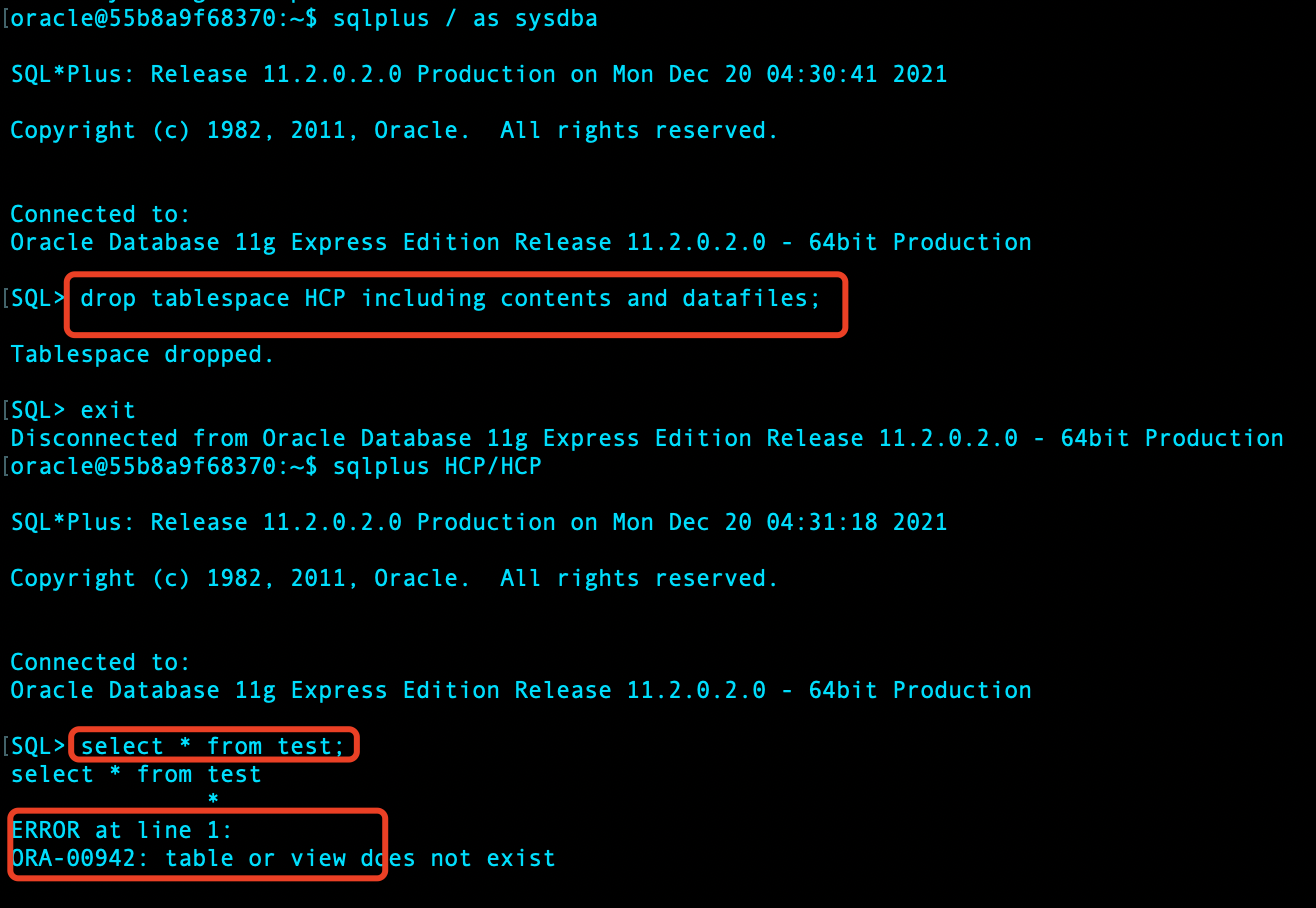
重启数据库到 mount,进行 rman 恢复:
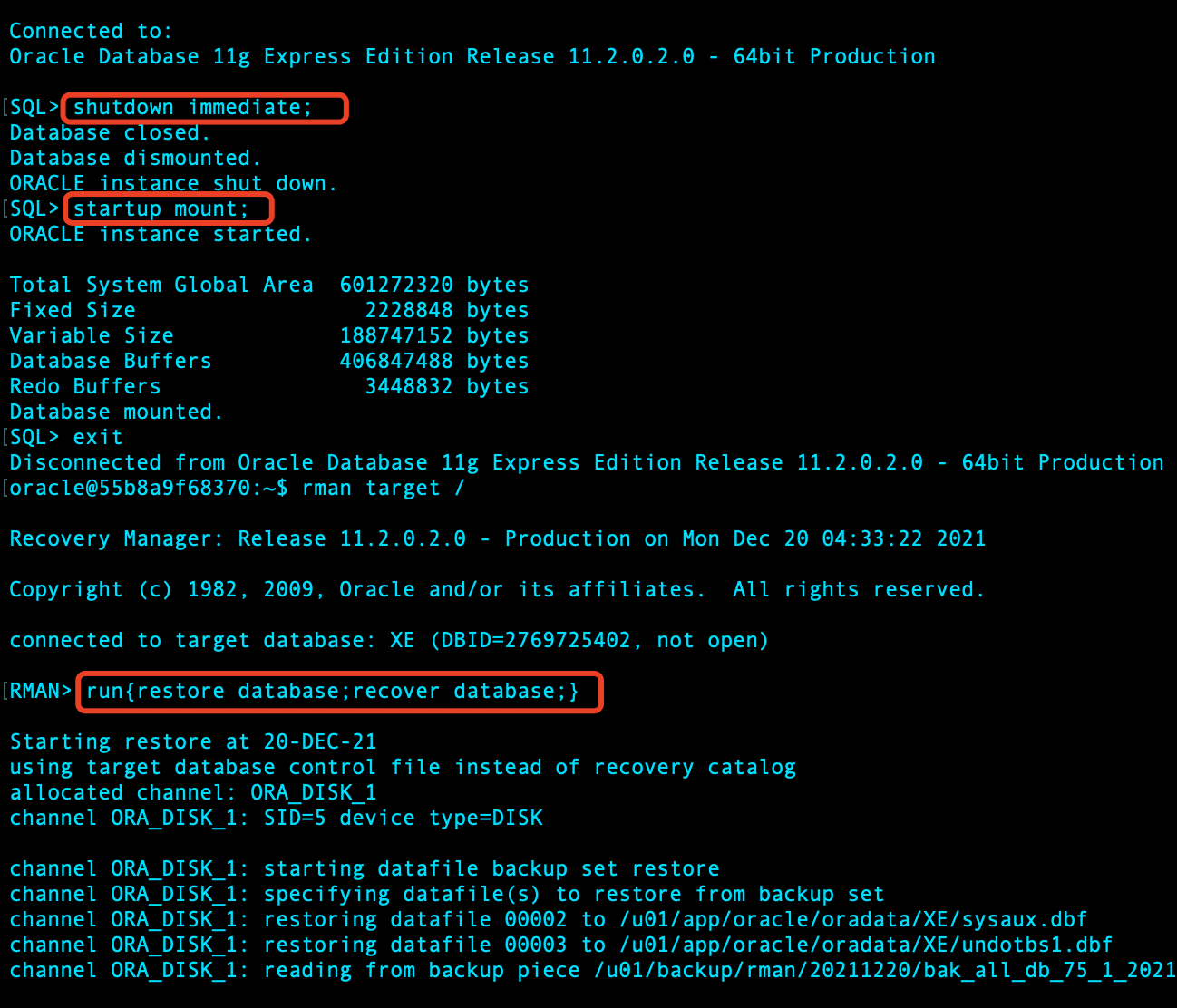
open 数据库,查询 test 表,发现依然不存在:
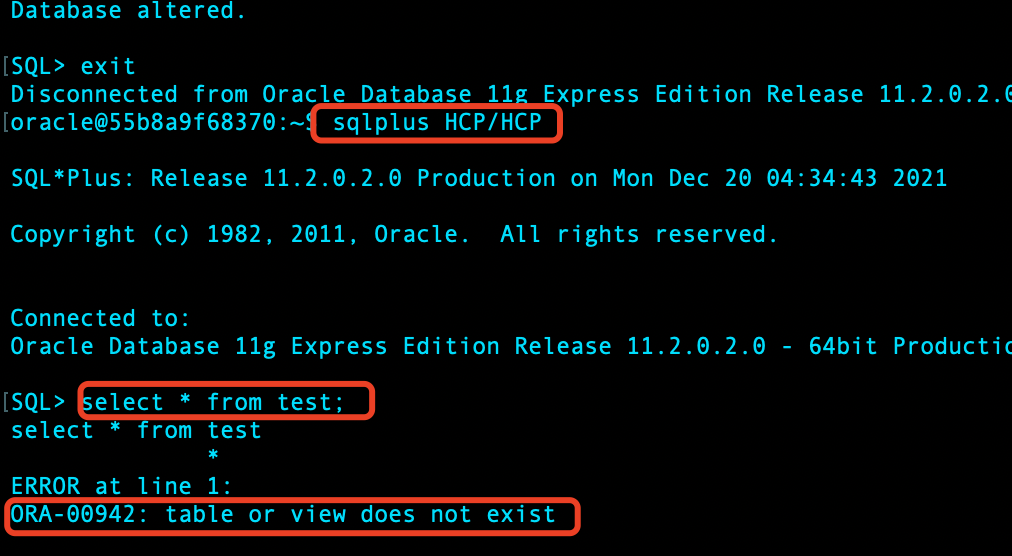
基于时间点进行恢复:
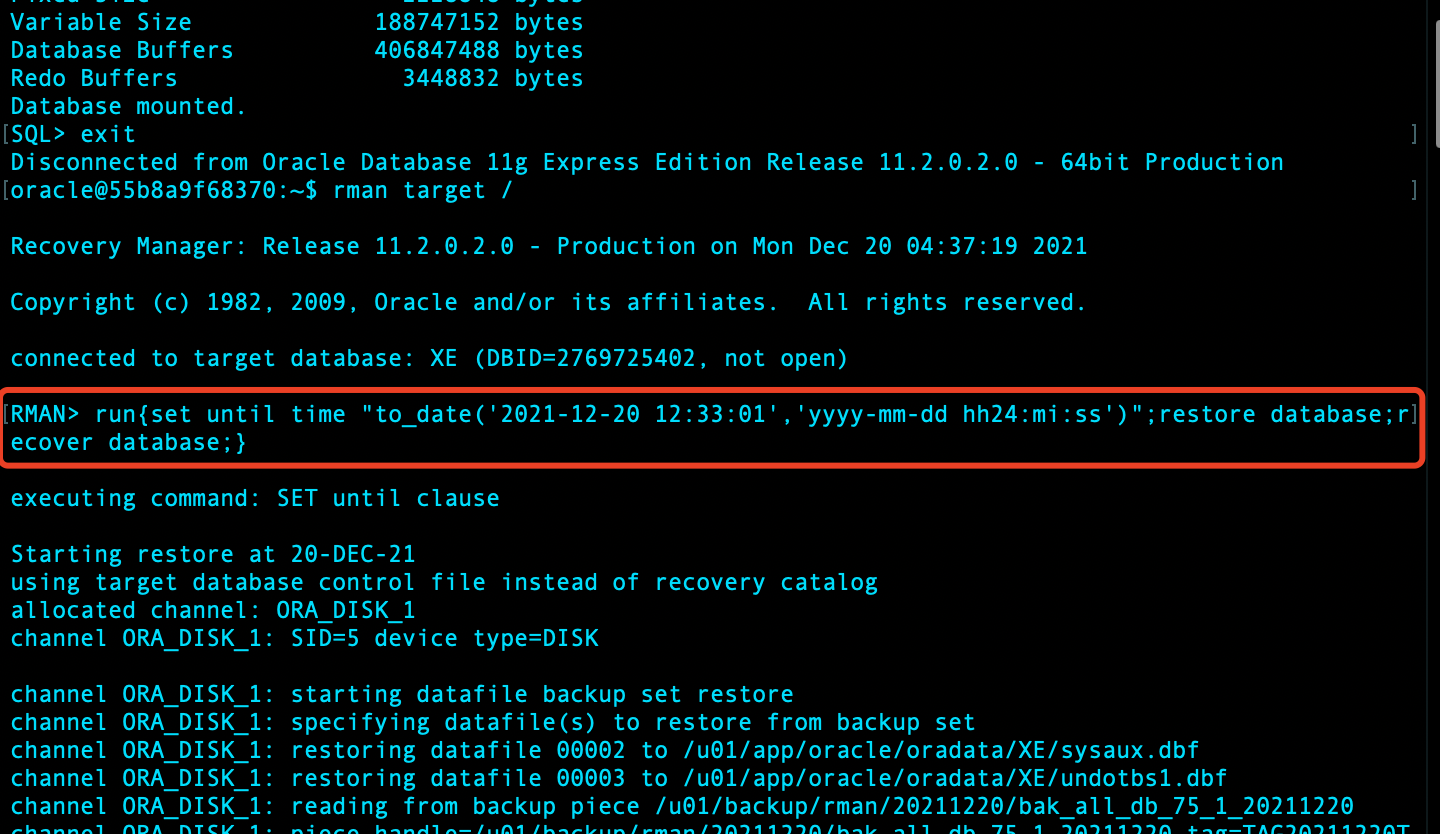
open 数据库,查看 test 表:
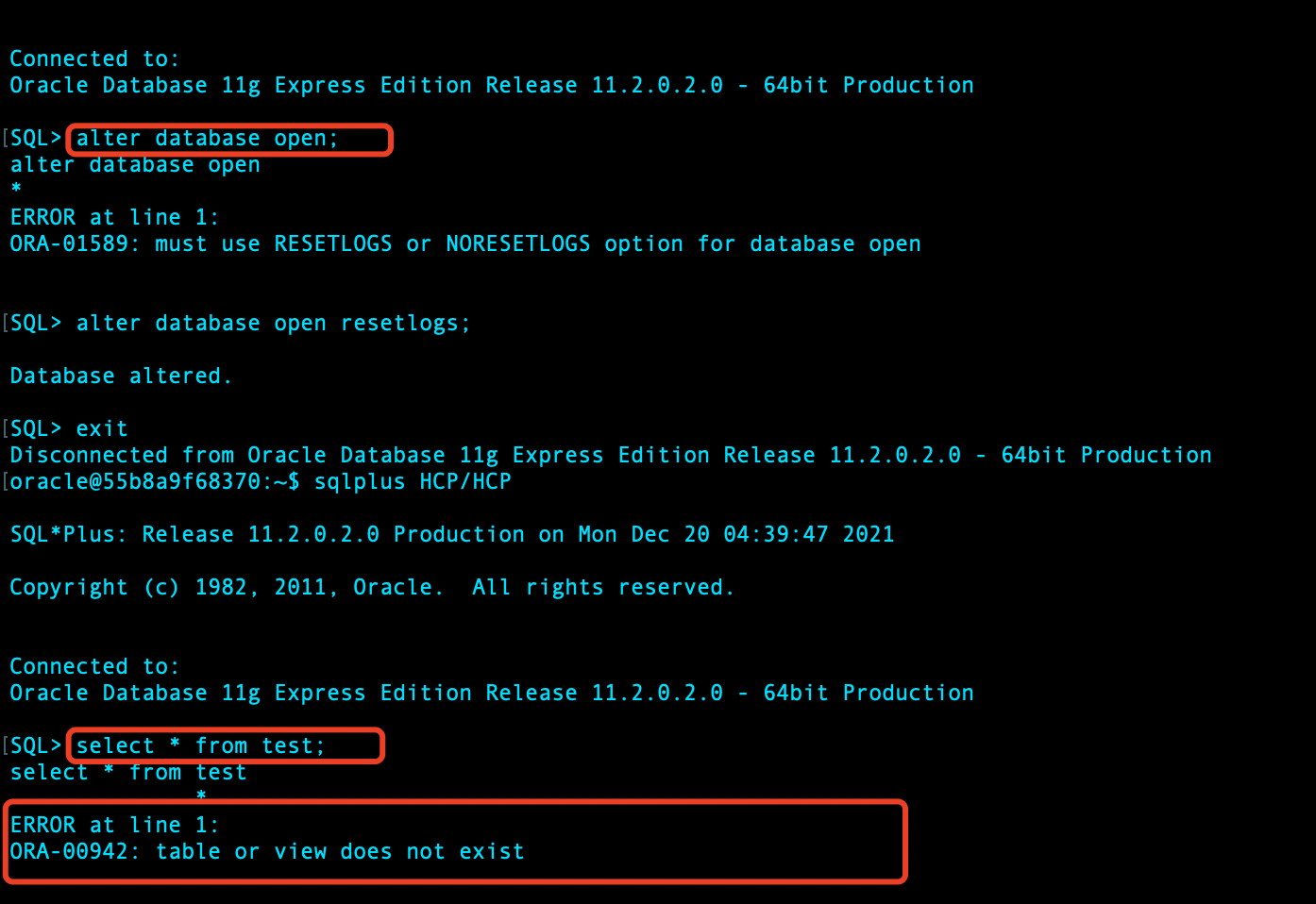
依然没有恢复,原因是什么
情形 3 ,全备后又修改了一些数据,根据全备做全量恢复
做全备前,test 表中仅有数据 123:
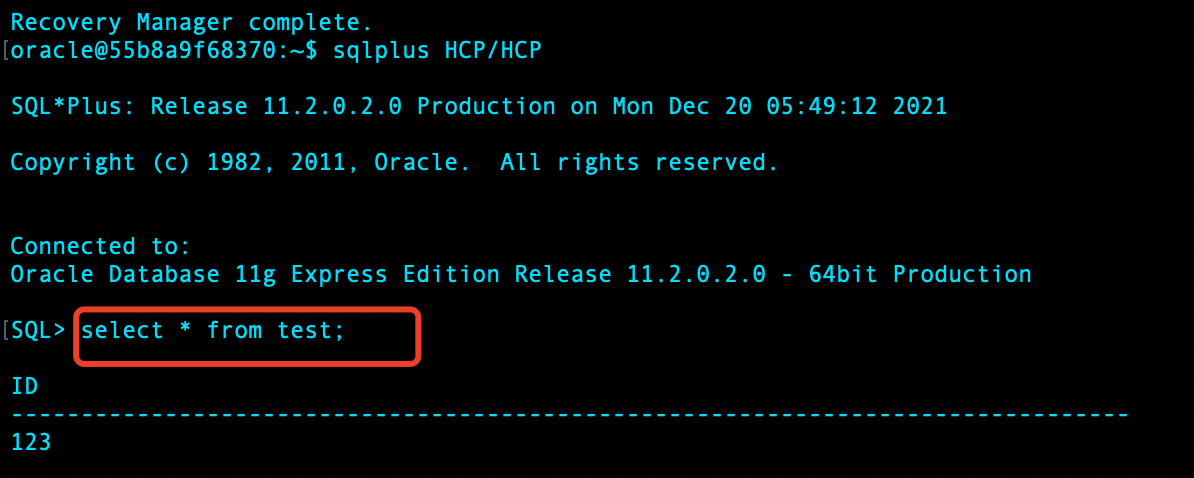
进行全量备份后,插入数据 666:

物理删除表空间,制造故障:
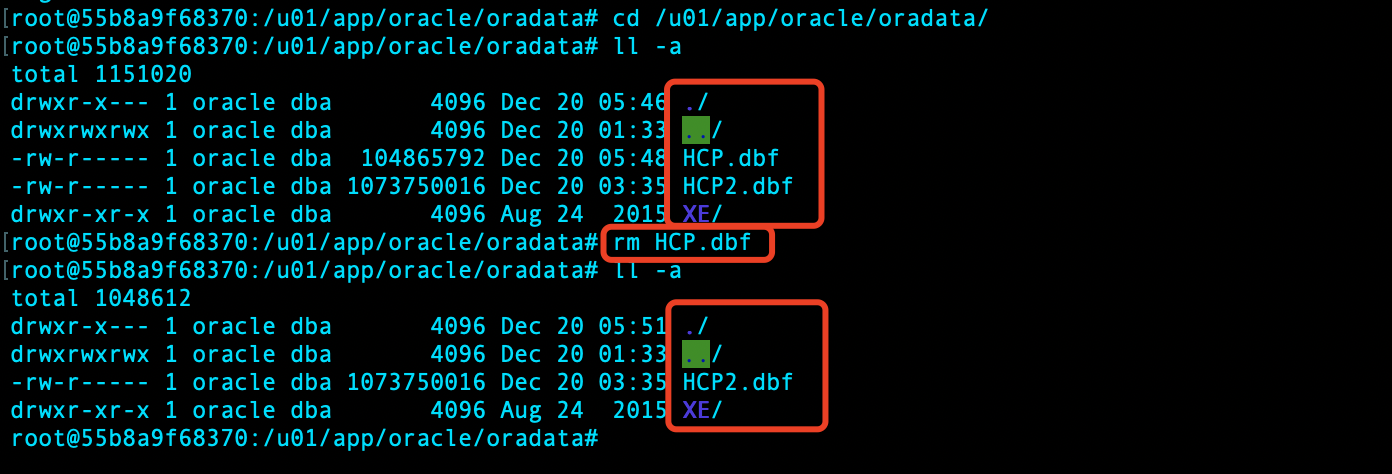
表空间物理文件已删除,数据库已无法 shutdown immediate:

shutdown abort 后启动到 mount,使用 rman 做完全恢复:

open 数据库并查询 test 表:
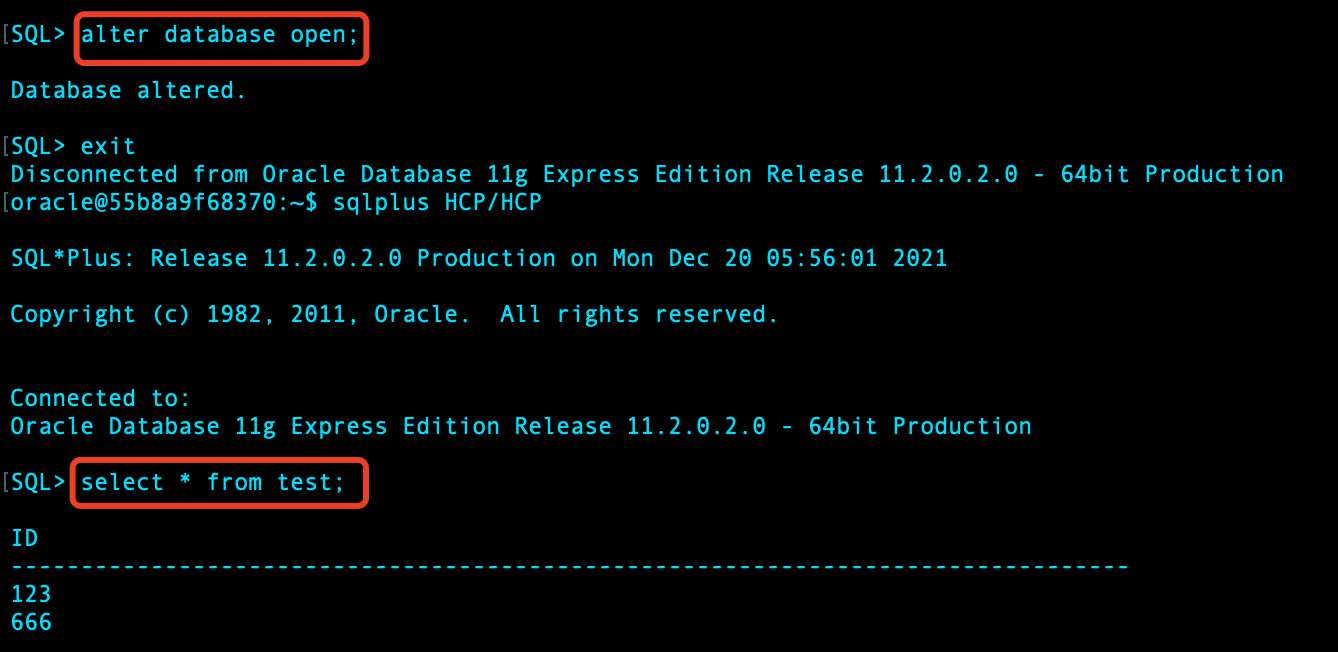
可以发现,除 123 外,备份后新增的数据 666 也被恢复了。
因为 recover 操作进行的是完全恢复,在全量备份、全量备份后的归档日志及 redo.log 都完好的情况下。会先根据全量备份恢复数据,后根据归档日志和 redo.log 恢复全量备份后的数据库变更记录。
因此每次做全量备份,一定要将全量备份后的归档日志留好,不要清理。可在每次全量备份后清理备份前的归档日志。
那么问题又来了,既然留好全量备份与归档日志(当然还有当前的 redo.log)即可进行完整恢复,那么增量备份的好处又在哪里。每周或月进行全备,留一周或一月的归档日志,完全可以满足备份需求。比起此种方式,每周 0 级全备,每天 1 级增量的优势又在哪。