大数据简介
大数据的概念
Volume(数据容量)、Variety(数据类型)、Viscosity(价值密度)、Velocity(速度)、Veracity(真实性)
大数据的性质
非结构性、不完备性、时效性、安全性、可靠性
大数据处理的全过程
数据采集与记录 --> 数据抽取、清洗、标记 --> 数据集成、转换、简约 --> 数据分析与建模 --> 数据解释
大数据技术的特征
1.分析全面的数据而非随机抽样
2.重视数据的复杂性,弱化精确性
3.关注数据的相关性,而非因果关系
大数据的关键技术
流处理、并行化、摘要索引、可视化
大数据应用趋势
细分市场、推动企业发展、大数据分析的新方法出现、大数据与云计算高度融合、大数据一体化设备陆续出现、大数据安全
科学研究范式
第一范式(科学实验)、第二范式(科学理论)、第三范式(系统模拟)、第四范式(数据密集型计算)
格雷法则
1.科学计算数据爆炸式增长
2.解决方案为横向扩展的体系结构
3.将计算用于数据而不是数据用于计算(把程序向数据迁移。以计算为中心转变为以数据为中心)
CAP理论
Consistency(一致性)、Availability(可用性)、Partition Tolerance(分区容错性)
CAP定理
一个分布式系统不可能同时满足一致性、可用性、分区容错性三个系统需求,最多只能同时满足两个。
CAP选择
1.放弃分区容错,导致可扩展性不强:MySQL、Postgres
2.放弃可用性,导致性能不是特别高:Redis、MongoDB、MemcacheDB、HBase、BigTable、Hypertable
3.放弃一致性,对一致性要求低:Cassandra、Dynamo、Voldemort 、CouchDB
HDFS
HDFS目标
1.兼容廉价的硬件设备
2.流数据读写
3.大数据集
4.简单的文件模型
5.强大的跨平台兼容性
HDFS主要组件(图来自哈尔滨理工大学大数据课程李老师的课件)

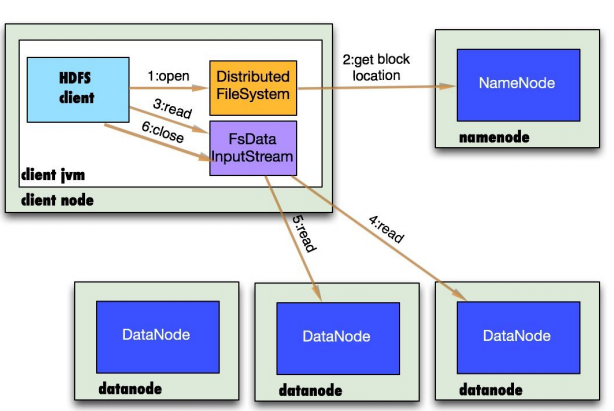
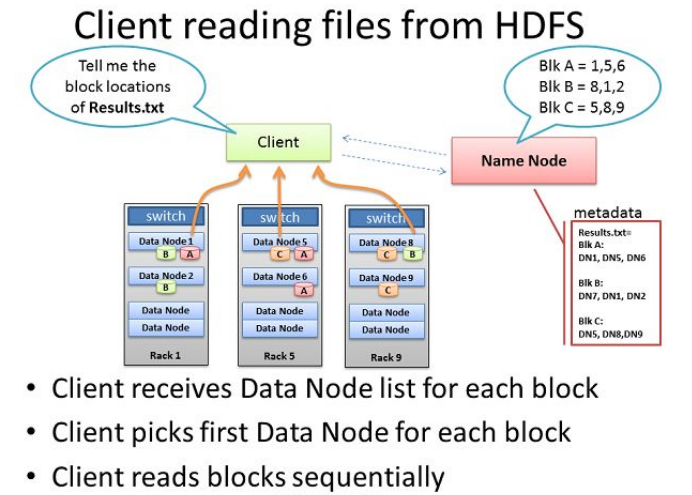
HDFS读文件
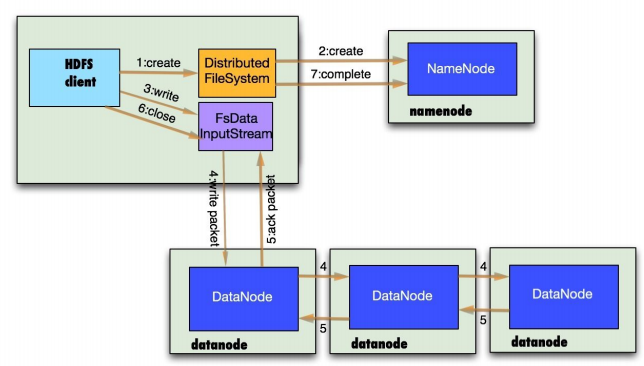
HDFS写文件
HDFS容错
1.心跳检测:NameNode和DataNode之间
2.文件块完整性:记录新建文件所有块的校验和
3.集群负载均衡:自动从负载重的DataNode上迁移数据
4.文件删除:存放在/trash下,过一段时间才正式删除。在hdfs-site.xml中配置
MapReduce
函数式编程优点
1.逻辑可证
2.模块化
3.组件化
4.易于调试
5.易于测试
6.更高的生产率
函数式编程的特征
1.没有副作用:没有修改过函数在其作用域之外的量并被其他函数使用
2.无状态的编程:将状态保存在参数中,作为函数的附赠品来传递(不是很懂)
3.输入值和输出值:在函数式编程中,只有输入值和输出值。函数是基本的单位。在面向对象编程中,将对象传来传去;在函数式编程中,是将函数传来传去。
MapReduce流程图(图来自南京大学黄宜华老师的课件)
大数据流式计算
流式数据的特征
实时性、易失性、突发性、无序性、无限性、准确性
大数据流式计算模型
数据流管理系统:固定查询、ad hoc查询
大数据流式计算:Twitter Storm、Yahoo S4
Storm总体架构
主节点Nimbus:负责全局资源分配、任务调度、状态监控、故障检测
从节点Supervisor:接收任务,启动或停止工作进程Worker。每个Worker内部有多个Executor。每个Executor对应一个线程。每个Executor对应一个或多个Task。
Zookeeper:协调、存储元数据、从节点心跳信息、存储整个集群的所有状态信息、所有配置信息
Storm特征
1.编程简单
2.支持多语言
3.作业级容错
4.水平扩展
5.底层使用Zero消息队列,快
Storm缺点
1.资源分配没有考虑任务拓扑的结构特征,无法适应数据负载的动态变化
2.采用集中式的作业级容错,限制了系统的可扩展性
搜索引擎
搜索引擎的定义
根据一定的策略、运用特定的计算机程序、从互联网上搜集信息,对信息进行组织和处理之后,将这些信息展示给用户的系统叫搜索引擎。
搜索引擎的组成
搜索器:搜集信息
索引器:抽取索引
检索器:在库中检索,排序。
用户接口:展示
搜索引擎的工作过程
爬行 -> 抓取存储 -> 预处理 -> 排名
搜索引擎的评价指标
查全率、查准率、响应时间、覆盖范围、用户方便性
大数据分析
数据分析的目的
对杂乱无章的数据进行集中、萃取、提炼,进而找出所研究对象的内在规律,发现其价值。
数据分析的意义
在杂乱的数据中分析出有价值的内容,获得对数据的认知。
数据分析的类型
1.探索性数据分析(为了形成值得假设的检验)
2.定性数据分析(非数值型数据)
3.离线数据分析(先存于磁盘,批处理)
4.在线数据分析(实时)