原
极大似然估计详解
�0�2 �0�2 �0�2 �0�2 以前多次接触过极大似然估计,最近在看贝叶斯分类,总结如下:
贝叶斯决策
�0�2 �0�2 �0�2 �0�2 首先来看贝叶斯分类
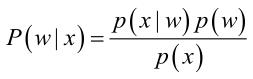
�0�2 �0�2 �0�2 �0�2 其中:p(w):为先验概率,表示在某种类别前提下,表示某事发生了,有了这个后验概率,说明某事物属于这个类别的可能性越大�0�2 �0�2 �0�2 �0�2 我们来看一个直观的例子:已知:在夏季,女性穿凉鞋的概率为2/3,问题:若你在公园中随机遇到一个穿凉鞋的人�0�2 �0�2 �0�2 �0�2 从问题看,某事发生了�0�2 �0�2 �0�2 �0�2 设:
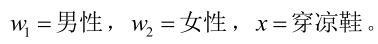
�0�2 �0�2 �0�2 �0�2 由已知可得:
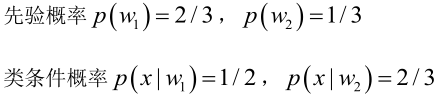
�0�2 �0�2 �0�2 �0�2 男性和女性穿凉鞋相互独立(若只考虑分类问题,的取值并不重要)。
�0�2 �0�2 �0�2 �0�2 由贝叶斯公式算出:
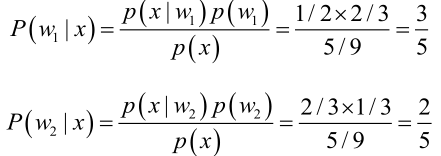
问题引出
�0�2 �0�2 �0�2 �0�2 但是在实际问题中并不都是这样幸运的,而先验概率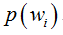
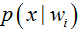
�0�2 �0�2 �0�2 �0�2 先验概率的估计较简单�0�2 �0�2 �0�2 �0�2 类条件概率的估计(非常难),把估计完全未知的概率密度
重要前提
�0�2 �0�2 �0�2 �0�2 上面说到�0�2 �0�2 �0�2 �0�2�0�2重要前提:训练样本的分布能代表样本的真实分布。每个样本集中的样本都是所谓独立同分布的随机变量 (iid条件)。
极大似然估计
�0�2 �0�2 �0�2 �0�2 极大似然估计的原理,如下图所示:
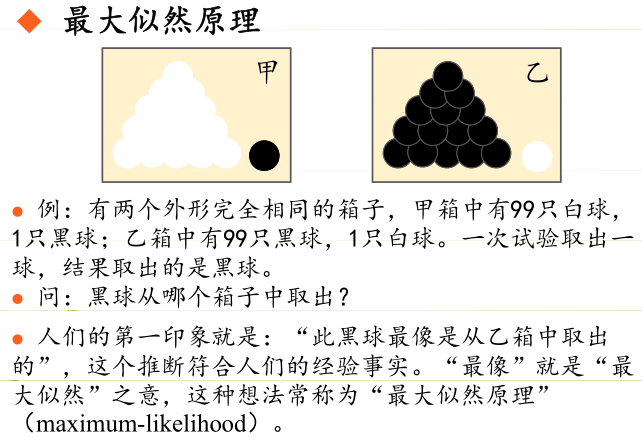
�0�2 �0�2 �0�2 �0�2 总结起来,反推最有可能(最大概率)导致这样结果的参数值。
�0�2 �0�2 �0�2 �0�2 原理:极大似然估计是建立在极大似然原理的基础上的一个统计方法,即:“模型已定,观察其结果,则称为极大似然估计。
�0�2 �0�2 �0�2 �0�2 由于样本集中的样本都是独立同分布,来估计参数向量θ。记已知的样本集为:
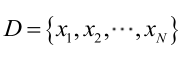
�0�2 �0�2 �0�2 �0�2 似然函数(linkehood function):联合概率密度函数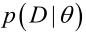
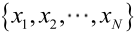
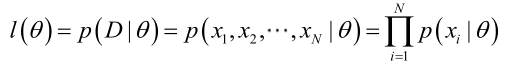
�0�2 �0�2 �0�2 �0�2 如果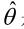
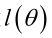

求解极大似然函数
�0�2 �0�2 �0�2 �0�2 ML估计:求使得出现该组样本的概率最大的θ值。
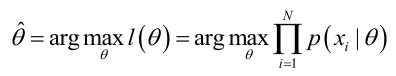
�0�2�0�2�0�2�0�2�0�2�0�2�0�2�0�2 实际中为了便于分析
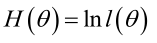
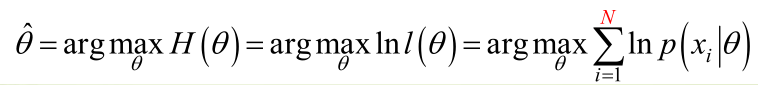
�0�2 �0�2 �0�2 �0�2 1. 未知参数只有一个(θ为标量)
�0�2 �0�2 �0�2 �0�2 在似然函数满足连续、可微的正则条件下
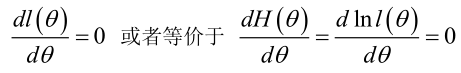
�0�2 �0�2 �0�2 �0�2 2.未知参数有多个(θ为向量)
�0�2 �0�2 �0�2 �0�2 则θ可表示为具有S个分量的未知向量:
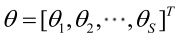
�0�2�0�2�0�2�0�2�0�2�0�2�0�2�0�2 记梯度算子:
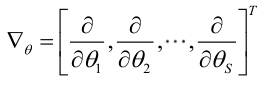
�0�2�0�2�0�2�0�2�0�2�0�2�0�2�0�2 若似然函数满足连续可导的条件
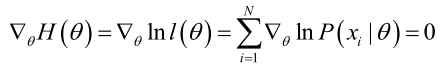
�0�2�0�2�0�2�0�2�0�2�0�2�0�2�0�2 方程的解只是一个估计值,它才会接近于真实值。
极大似然估计的例子
�0�2 �0�2 �0�2 �0�2 例1:设样本服从正态分布
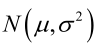
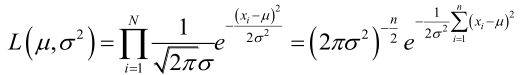
�0�2 �0�2 �0�2 �0�2 它的对数:
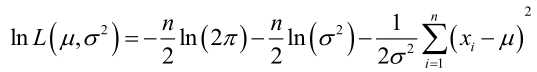
�0�2 �0�2 �0�2 �0�2 求导
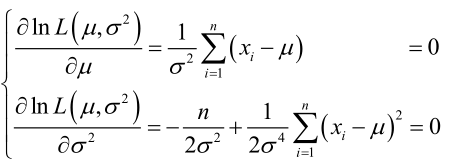
�0�2 �0�2 �0�2 �0�2 联合解得:
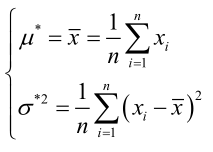
�0�2 �0�2 �0�2 �0�2 似然方程有唯一解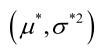
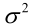
�0�2 �0�2 �0�2 �0�2 例2:设样本服从均匀分布[a
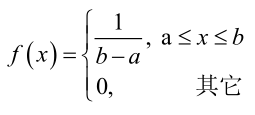
�0�2 �0�2 �0�2 �0�2 对样本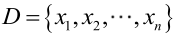
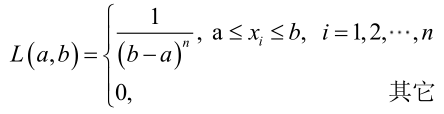
�0�2 �0�2 �0�2 �0�2 很显然,b)作为a和b的二元函数是不连续的,求L(a,为使L(a,b-a应该尽可能地小,否则,b)=0。类似地a不能大过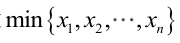
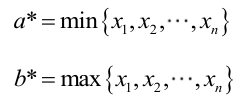
总结
�0�2 �0�2 �0�2 �0�2 求最大似然估计量
�0�2 �0�2 �0�2 �0�2 (1)写出似然函数;
�0�2 �0�2 �0�2 �0�2 (2)对似然函数取对数�0�2 �0�2 �0�2 �0�2 (3)求导数;
�0�2 �0�2 �0�2 �0�2 (4)解似然方程。
�0�2 �0�2 �0�2 �0�2 最大似然估计的特点:
�0�2 �0�2 �0�2 �0�2 1.比其他估计方法更加简单;
�0�2 �0�2 �0�2 �0�2 2.收敛性:无偏或者渐近无偏,收敛性质会更好;
�0�2 �0�2 �0�2 �0�2 3.如果假设的类条件概率模型正确,将导致非常差的估计结果。