1.首先介绍下卡方公式

其中,t代表候选特征,c代表对应分类,A代表t在c中出现的次数。B代表t不在c中出现的次数,C代表c中不出现t的次数。D代表文档集中c和t都不出现的次数,N代表整个文档集的大小。(次数不是指t的次数,均指样本数)
2.扩展过程
a.首先,既然是扩展,那么就一定有原始的种子,这个可以人工挑出来。种子词不必很多,但要有强烈类别代表性。
b.假设有n个类别,先用n个类别的种子词在总的数据中匹配,当数据的一个样本中匹配到了一个种子词,则这个样本被划为这个种子词所属的类别。这样一个样本可能会被划分到多个类别。
c.在b步骤已经把数据分为了n+1类,对这些类中的每个特征词进行卡方统计,然后分别排序。
d.取每类前5~10个特征词加到原种子词中。
e.加完新特征后特征词是否收敛,是则程序结果,否则重复b~e.
3.细节
过程很简单,但还是有些需要注意的地方,要自己去优化。
1)首先卡方统计有效是建立在分类正确的基础上,而b步骤的匹配词来进行分类显然误差很大,这是导致结果不准确的原因之一。
2)扩展过程虽说是以是否收敛来判断迭代是否结束,但实际上程序可能会一直不收敛,在我的实验中前几次迭代还是可信的,往后的结果就有些偏离类别了。
3)从迭代结果中可以看出有些特征词排名很靠前,但它们往往不是我们想要的词,它们往往是那些在本类中出现的较少,而在其它类出现更少或没有出现过的词。特征强烈,但不是我们想要的。这里我们可以考虑用特征词的tf适当的过滤下。
=====================华丽的分割线(以下是在网上查来的关于卡方的详细资料)=============================
x2检验(chi-square test)或称卡方检验
x2检验(chi-square test)或称卡方检验,是一种用途较广的假设检验方法。可以分为成组比较(不配对资料)和个别比较(配对,或同一对象两种处理的比较)两类。
一、四格表资料的x2检验
例20.7某医院分别用化学疗法和化疗结合放射治疗卵巢癌肿患者,结果如表20-11,问两种疗法有无差别?
表20-11 两种疗法治疗卵巢癌的疗效比较
| 组别 | 有效 | 无效 | 合计 | 有效率(%) |
| 化疗组 | 19 | 24 | 43 | 44.2 |
| 化疗加放疗组 | 34 | 10 | 44 | 77.3 |
| 合计 | 53 | 34 | 87 | 60.9 |
表内用虚线隔开的这四个数据是整个表中的基本资料,其余数据均由此推算出来;这四格资料表就专称四格表(fourfold table),或称2行2列表(2×2 contingency table)从该资料算出的两种疗法有效率分别为44.2%和77.3%,两者的差别可能是抽样误差所致,亦可能是两种治疗有效率(总体率)确有所不同。这里可通过x2检验来区别其差异有无统计学意义,检验的基本公式为:
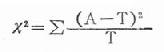
式中A为实际数,以上四格表的四个数据就是实际数。T为理论数,是根据检验假设推断出来的;即假设这两种卵巢癌治疗的有效率本无不同,差别仅是由抽样误差所致。这里可将两种疗法合计有效率作为理论上的有效率,即53/87=60.9%,以此为依据便可推算出四格表中相应的四格的理论数。兹以表20-11资料为例检验如下。
检验步骤:
1.建立检验假设:
H0:π1=π2
H1:π1≠π2
α=0.05
2.计算理论数(TRC),计算公式为:
TRC=nR.nc/n 公式(20.13)
式中TRC是表示第R行C列格子的理论数,nR为理论数同行的合计数,nC为与理论数同列的合计数,n为总例数。
第1行1列: 43×53/87=26.2
第1行2列: 43×34/87=16.8
第2行1列: 44×53/87=26.8
第2行2列: 4×34/87=17.2
以推算结果,可与原四项实际数并列成表20-12:
表20-12 两种疗法治疗卵巢癌的疗效比较
| 组别 | 有效 | 无效 | 合计 |
| 化疗组 | 19(26.2) | 24(16.8) | 43 |
| 化疗加放疗组 | 34(26.8) | 10(17.2) | 44 |
| 合计 | 53 | 34 | 87 |
因为上表每行和每列合计数都是固定的,所以只要用TRC式求得其中一项理论数(例如T1.1=26.2),则其余三项理论数都可用同行或同列合计数相减,直接求出,示范如下:
T1.1=26.2
T1.2=43-26.2=16.8
T2.1=53-26.2=26.8
T2.2=44-26.2=17.2
3.计算x2值 按公式20.12代入
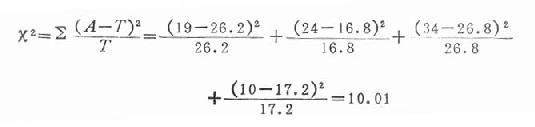
4.查x2值表求P值
在查表之前应知本题自由度。按x2检验的自由度v=(行数-1)(列数-1),则该题的自由度v=(2-1)(2-1)=1,查x2界值表(附表20-1),找到x20.001(1)=6.63,而本题x2=10.01即x2>x20.001(1),P<0.01,差异有高度统计学意义,按α=0.05水准,拒绝H0,可以认为采用化疗加放疗治疗卵巢癌的疗效比单用化疗佳。
通过实例计算,读者对卡方的基本公式有如下理解:若各理论数与相应实际数相差越小,x2值越小;如两者相同,则x2值必为零,而x2永远为正值。又因为每一对理论数和实际数都加入x2值中,分组越多,即格子数越多,x2值也会越大,因而每考虑x2值大小的意义时同时要考虑到格子数。因此自由度大时,x2的界值也相应增大。
二、四格表的专用公式
对于四格表资料,还可用以下专用公式求x2值。
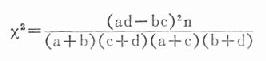
式中a、b、c、d各代表四格表中四个实际数,现仍以表20-12为例,将上式符号标记如下(表20-13),并示范计算。
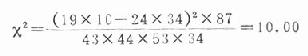
表20-13 两种疗法治疗卵巢肿瘤患者的疗效
| 组别 | 有效 | 无效 | 合计 |
| 化疗组 | 19(a) | 24(b) | 43(a+b) |
| 化疗加放疗组 | 34(c) | 10(d) | 44(c+d) |
| 53(a+c) | 34(b+d) | 87(n) |
计算结果与前述用基本公式一致,相差0.01用换算时小数点后四舍五入所致。
三、四格表x2值的校正
x2值表是数理统计根据正态分布中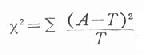 的定义计算出来的。
的定义计算出来的。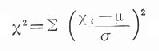 是一种近似,在自由度大于1、理论数皆大于5时,这种近似很好;当自由度为1时,尤其当1<T<5,而n>40时,应用以下校正公式:
是一种近似,在自由度大于1、理论数皆大于5时,这种近似很好;当自由度为1时,尤其当1<T<5,而n>40时,应用以下校正公式:
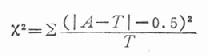
如果用四格表专用公式,亦应用下式校正:
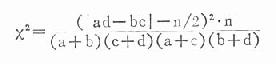
例20.8某医师用甲、乙两疗法治疗小儿单纯性消化不良,结果如表20-14.试比较两种疗法效果有无差异?
表20-14 两种疗法效果比较的卡方较正计算
| 疗法 | 痊愈数 | 未愈数 | 合计 |
| 甲 | 26(28.82) | 7(4.18) | 33 |
| 乙 | 36(33.18) | 2(4.82) | 38 |
| 合计 | 62 | 9 | 71 |
从表20-14可见,T1.2和T2.2数值都<5,且总例数大于40,故宜用校正公式(20.15)检验。步骤如下:
1.检验假设:
H0:π1=π2
H1:π1≠π2
α=0.05
2.计算理论数:(已完成列入四格表括弧中)
3.计算x2值:应用公式(20.15)运算如下:
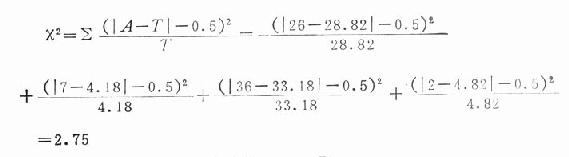
查x2界值表,x20.05(1)=3.84,故x2<x20.05(1),P>0.05.
按α=0.05水准,接受H0,两种疗效差异无统计学意义。
如果不采用校正公式,而用原基本公式,算得的结果x2=4.068,则结论就不同了。
如果观察资料的T<1或n<40时,四格表资料用上述校正法也不行,可参考预防医学专业用的医学统计学教材中的精确检验法直接计算概率以作判断。
四、行×列表的卡方检验(x2test for R×C table)
适用于两个组以上的率或百分比差别的显著性检验。其检验步骤与上述相同,简单计算公式如下:
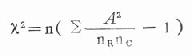
式中n为总例数;A为各观察值;nR和nC为与各A值相应的行和列合计的总数。
例20.9北方冬季日照短而南移,居宅设计如何适应以获得最大日照量,增强居民体质,减少小儿佝偻病,实属重要。胡氏等1986年在北京进行住宅建筑日照卫生标准的研究,对214幢楼房居民的婴幼儿712人体检,检出轻度佝偻病333例,比较了居室朝向与患病的关系。现将该资料归纳如表20-15作行×列检验。
表20-15居室朝向与室内婴幼儿佝偻病患病率比较
| 检查结果 | 居室朝向 | 合计 | |||
| 南 | 西、西南 | 东、东南 | 北、东北、西北 | ||
| 患病 | 180 | 14 | 120 | 65 | 379 |
| 无病 | 200 | 16 | 84 | 33 | 333 |
| 合计 | 380 | 30 | 204 | 98 | 712 |
| 患病率(%) | 47.4 | 46.7 | 58.8 | 66.3 | 53.2 |
/P>
该表资料由2行4列组成,称2×4表,可用公式(20.17)检验。
(一)检验步骤
1.检验假设
H0:四类朝向居民婴幼儿佝偻病患病率相同。
H1:四类朝向居民婴幼儿佝偻病患率不同。
α=0.05
2.计算x2值
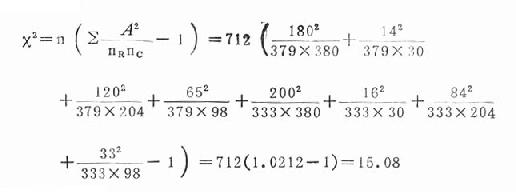
3.确定P值和分析
本题v=(2-1)(4-3)=3,据此查附表20-1:
x20.01(3)=11.34,本题x2=15.08,x2>x20.01(3),P<0.01,按α=0.05水准,拒绝H0,可以认为居室朝向不同的居民,婴幼儿佝偻病患病率有差异。
(二)行×列表x2检验注意事项
1.一般认为行×列表中不宜有1/5以上格子的理论数小于5,或有小于1的理论数。当理论数太小可采取下列方法处理:①增加样本含量以增大理论数;②删去上述理论数太小的行和列;③将太小理论数所在行或列与性质相近的邻行邻列中的实际数合并,使重新计算的理论数增大。由于后两法可能会损失信息,损害样本的随机性,不同的合并方式有可能影响推断结论,故不宜作常规方法。另外,不能把不同性质的实际数合并,如研究血型时,不能把不同的血型资料合并。
2.如检验结果拒绝检验假设,只能认为各总体率或总体构成比之间总的来说有差别,但不能说明它们彼此之间都有差别,或某两者间有差别。
五、配对计数资料x2检验(x2test of paired comparison of enumeration data)
在计量资料方面,同一对象实验前后差别或配对资料的比较与两样本均数比较方法有所不同;在计数资料方面亦如此。例如表20-16是28份咽喉涂抹标本,每份按同样条件分别接种在甲、乙两种白喉杆菌培养基中,观察白喉杆菌生长情况,试比较两种培养基的效果。
表20-16 两种白喉杆菌培养基培养结果比较
| 甲培养基 | 乙培养基 | 合计 | |
| + | - | ||
| + | 11(a) | 9(b) | 20 |
| - | 1(c) | 7(d) | 8 |
| 合计 | 12 | 16 | 28 |
从表中资料可见有四种结果:(a)甲+乙+,(b)甲+乙-(c)甲-乙+,(d)甲-乙-;如果我们目的是比较两种培养基的培养结果有无差异,则(a)、(d)两种结果是一致的,对差异比较毫无意义,可以不计,我们只考虑结果不同的(b)和(c),看其差异有无意义,可以应用以下简易公式计算:
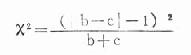
检验步骤:
1.检验假设
H0:π1=π2
H1:π1≠π2
α=0.05
2.计算x2值
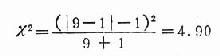
3.确定P值和分析 配对资料v=1,查附表20-1得知x20.05(1)=3.84,x2>x0.05(1),P<0.05,按α=0.05水准,拒绝H0,可以认为甲培养基的白喉杆菌生长效率较高。
如果b+c>40,则可采用:
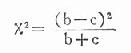
此外还有两种以上处理方法的比较,可参阅预防医学专业的医学统计方法有关章节。
附表20-1 x2界值表
| v | P | V | P | ||||
| 0.05 | 0.01 | 0.001 | 0.05 | 0.01 | 0.001 | ||
| 1 | 3.84 | 6.63 | 10.83 | 16 | 26.30 | 32.00 | 39.25 |
| 2 | 5.99 | 9.21 | 13.81 | 17 | 27.59 | 33.14 | 40.79 |
| 3 | 7.81 | 11.34 | 16.27 | 18 | 28.87 | 34.18 | 42.31 |
| 4 | 9.49 | 13.28 | 18.47 | 19 | 30.14 | 36.19 | 43.82 |
| 5 | 11.07 | 15.09 | 20.52 | 20 | 31.41 | 37.57 | 45.32 |
| 6 | 12.59 | 16.81 | 22.46 | 21 | 32.67 | 38.93 | 46.80 |
| 7 | 14.07 | 18.48 | 24.32 | 22 | 33.92 | 40.29 | 48.27 |
| 8 | 15.51 | 20.09 | 26.12 | 23 | 35.17 | 41.64 | 49.73 |
| 9 | 16.92 | 21.67 | 27.88 | 24 | 36.42 | 42.98 | 51.18 |
| 10 | 18.31 | 23.21 | 29.59 | 25 | 37.65 | 44.31 | 52.62 |
| 11 | 19.68 | 24.72 | 31.26 | 26 | 38.89 | 45.64 | 54.05 |
| 12 | 21.03 | 26.22 | 32.91 | 27 | 40.11 | 46.96 | 55.48 |
| 13 | 22.36 | 27.69 | 34.53 | 28 | 41.34 | 48.28 | 56.89 |
| 14 | 23.68 | 29.14 | 36.12 | 29 | 42.56 | 49.59 | 58.30 |
| 15 | 25.00 | 30.58 | 37.70 | 30 | 43.77 | 50.89 | 59.70 |