前言
这一篇文章我们来谈一下2017年新加坡国立大学提出的基于深度学习的协同过滤模型NeuralCF。我们在之前讲过矩阵分解技术,将协同过滤中的共现矩阵分解成用户向量矩阵以及物品向量矩阵。那么Embedding的思路也是一样的,只不过不是通过矩阵分解的形式,而是通过多层神经网络使用Embedding构造用户隐向量以及物品隐向量。用户隐向量与物品隐向量的內积,就是用户对物品的评分。这个內积的操作,同样可以使用神经网络层来实现,也就是前一篇文章所用的Scoring层,得到所谓的“相似度”,也就得到了评分。在实际使用中,我们往往会发现矩阵分解的模型会得到欠拟合的结果,所以深度学习可以弥补矩阵分解的结构简单,拟合不充分的弊端。论文原文以及我找到的一篇全文翻译的博文我贴在参考里面了,有兴趣的读者可以阅读一下。
网络结构
NeuralCF的网络结构如下图所示:
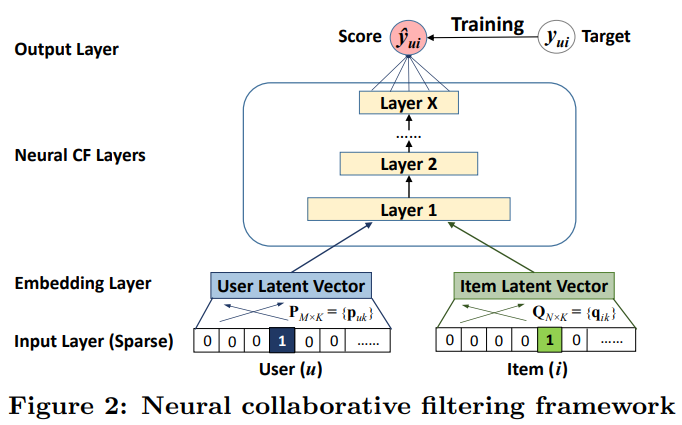
这里使用一个用户和一个物品作为输入特征,它使用one-hot编码将它们转化为二值化稀疏向量。注意到,对输入使用这样的通用特征表示,可以很容易地使用的内容特征来表示用户和物品,以调整解决冷启动问题。文章使用了多层感知机(Layer1-X)来代替了之前的内机操作,最终得到了评分。这样做的原因:
- 可以使得用户向量和物品向量充分交叉,得到更多有价值的特征组合
- 可以引入更多的非线性特征让模型的表达能力更强
输入层上面是嵌入层(Embedding Layer);它是一个全连接层,用来将输入层的稀疏表示映射为一个稠密向量(dense vector)。所获得的用户(物品)的Embedding(就是一个稠密向量)可以被看作是在潜在因素模型的上下文中用于描述用户(项目)的潜在向量。然后我们将用户Embedding和物品Embedding送入多层神经网络结构,我们把这个结构称为神经协作过滤层,它将潜在向量映射为预测分数。NCF层的每一层可以被定制,用以发现用户-物品交互的某些潜在结构。最后一个隐含层Layer X的维度大小决定了模型的能力。
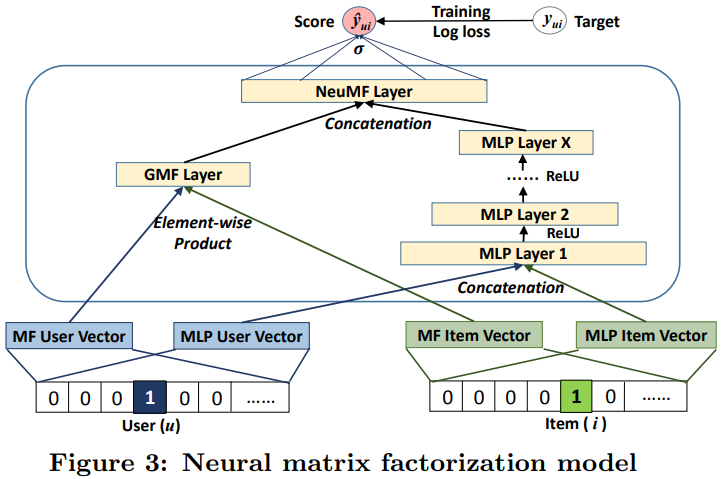
实际上,用户和商品的互操作可以使用任意的互操作形式,这也就是广义矩阵分解(GMF)。那么,这篇文章使用了元素积,也就是逐元素点乘(element-wise product)的形式,将用户向量和物品向量映射到同等维度大小的空间当中,然后对应维度相乘,这样就实现了互操作,最后再送入逻辑回归层等输出层,拟合最终的预测目标。GMF,它应用了一个线性内核来模拟潜在的特征交互;MLP,使用非线性内核从数据中学习交互函数。接下来的问题是:我们如何能够在NCF框架下融合GMF和MLP,使他们能够相互强化,以更好地对复杂的用户-物品交互建模?为了解决这个问题,这篇文章将多种互操作结合起来,如传统矩阵分解,多层感知机映射这两种形式进行,然后也是用了两种互操作,逐元素点乘以及多层感知机,如下图所示。
公式部分
对于结合GMF和单层MLP的模型形成数学公式的话如下所示:
整体的框架中的公式可以如下:
这里的(p^G_u)和(p^M_u)分别表示GMF部分和MLP部分的用户嵌入(user embedding);同样的,(q^G_i)和(q^M_i)分别表示物品的Embedding。
代码部分
# 广义矩阵分解
class GMF(torch.nn.Module):
def __init__(self, config):
super(GMF, self).__init__()
self.num_users = config['num_users']
self.num_items = config['num_items']
self.latent_dim = config['latent_dim']
self.embedding_user = torch.nn.Embedding(num_embeddings=self.num_users, embedding_dim=self.latent_dim)
self.embedding_item = torch.nn.Embedding(num_embeddings=self.num_items, embedding_dim=self.latent_dim)
self.affine_output = torch.nn.Linear(in_features=self.latent_dim, out_features=1)
self.logistic = torch.nn.Sigmoid()
def forward(self, user_indices, item_indices):
user_embedding = self.embedding_user(user_indices)
item_embedding = self.embedding_item(item_indices)
element_product = torch.mul(user_embedding, item_embedding)
logits = self.affine_output(element_product)
rating = self.logistic(logits)
return rating
def init_weight(self):
pass
class GMFEngine(Engine):
"""Engine for training & evaluating GMF model"""
def __init__(self, config):
self.model = GMF(config)
if config['use_cuda'] is True:
use_cuda(True, config['device_id'])
self.model.cuda()
super(GMFEngine, self).__init__(config)
# 多层感知机
class NeuMF(torch.nn.Module):
def __init__(self, config):
super(NeuMF, self).__init__()
self.config = config
self.num_users = config['num_users']
self.num_items = config['num_items']
self.latent_dim_mf = config['latent_dim_mf']
self.latent_dim_mlp = config['latent_dim_mlp']
self.embedding_user_mlp = torch.nn.Embedding(num_embeddings=self.num_users, embedding_dim=self.latent_dim_mlp)
self.embedding_item_mlp = torch.nn.Embedding(num_embeddings=self.num_items, embedding_dim=self.latent_dim_mlp)
self.embedding_user_mf = torch.nn.Embedding(num_embeddings=self.num_users, embedding_dim=self.latent_dim_mf)
self.embedding_item_mf = torch.nn.Embedding(num_embeddings=self.num_items, embedding_dim=self.latent_dim_mf)
self.fc_layers = torch.nn.ModuleList()
for idx, (in_size, out_size) in enumerate(zip(config['layers'][:-1], config['layers'][1:])):
self.fc_layers.append(torch.nn.Linear(in_size, out_size))
self.affine_output = torch.nn.Linear(in_features=config['layers'][-1] + config['latent_dim_mf'], out_features=1)
self.logistic = torch.nn.Sigmoid()
def forward(self, user_indices, item_indices):
user_embedding_mlp = self.embedding_user_mlp(user_indices)
item_embedding_mlp = self.embedding_item_mlp(item_indices)
user_embedding_mf = self.embedding_user_mf(user_indices)
item_embedding_mf = self.embedding_item_mf(item_indices)
mlp_vector = torch.cat([user_embedding_mlp, item_embedding_mlp], dim=-1) # the concat latent vector
mf_vector =torch.mul(user_embedding_mf, item_embedding_mf)
for idx, _ in enumerate(range(len(self.fc_layers))):
mlp_vector = self.fc_layers[idx](mlp_vector)
mlp_vector = torch.nn.ReLU()(mlp_vector)
vector = torch.cat([mlp_vector, mf_vector], dim=-1)
logits = self.affine_output(vector)
rating = self.logistic(logits)
return rating
def init_weight(self):
pass
def load_pretrain_weights(self):
"""Loading weights from trained MLP model & GMF model"""
config = self.config
config['latent_dim'] = config['latent_dim_mlp']
mlp_model = MLP(config)
if config['use_cuda'] is True:
mlp_model.cuda()
resume_checkpoint(mlp_model, model_dir=config['pretrain_mlp'], device_id=config['device_id'])
self.embedding_user_mlp.weight.data = mlp_model.embedding_user.weight.data
self.embedding_item_mlp.weight.data = mlp_model.embedding_item.weight.data
for idx in range(len(self.fc_layers)):
self.fc_layers[idx].weight.data = mlp_model.fc_layers[idx].weight.data
config['latent_dim'] = config['latent_dim_mf']
gmf_model = GMF(config)
if config['use_cuda'] is True:
gmf_model.cuda()
resume_checkpoint(gmf_model, model_dir=config['pretrain_mf'], device_id=config['device_id'])
self.embedding_user_mf.weight.data = gmf_model.embedding_user.weight.data
self.embedding_item_mf.weight.data = gmf_model.embedding_item.weight.data
self.affine_output.weight.data = 0.5 * torch.cat([mlp_model.affine_output.weight.data, gmf_model.affine_output.weight.data], dim=-1)
self.affine_output.bias.data = 0.5 * (mlp_model.affine_output.bias.data + gmf_model.affine_output.bias.data)
class NeuMFEngine(Engine):
"""Engine for training & evaluating GMF model"""
def __init__(self, config):
self.model = NeuMF(config)
if config['use_cuda'] is True:
use_cuda(True, config['device_id'])
self.model.cuda()
super(NeuMFEngine, self).__init__(config)
print(self.model)
if config['pretrain']:
self.model.load_pretrain_weights()
小结
多种用户向量、物品向量的Embedding,以及多种互操作形式进行特征的交叉组合,可以灵活的进行拼接,同时也利用了神经网络对任意函数的拟合能力,按需增加复杂度或者减小复杂度。但是NeuralCF并没有引入其他类型的特征,使得很多有价值的信息浪费。同时,互操作的选取也没有给出更多说明,只有在实践中进行探讨了。
参考
深度学习推荐系统 王喆编著
Neural Collaborative Filtering
【翻译】Neural Collaborative Filtering--神经协同过滤
Github:yihong-chen/neural-collaborative-filtering