做过深度学习的小伙伴,大家应该多多少少都听说过Embedding,这么火的Embedding到底是什么呢?这篇文章就用来介绍Embedding。另外,基于深度学习的推荐系统方法或者论文还没有结束,我打算穿插进行讲解,毕竟,深度学习出来的推荐框架的算法实在是太相像了,很难有大的不同。所以,这一篇就聊聊Embedding。
初识Embedding
Embedding又被成为向量化,或者向量的映射。Embedding(嵌入)也是拓扑学里面的词,在深度学习领域经常和Manifold(流形)搭配使用。在之前的Embedding的操作,往往都是将稀疏的向量转换成稠密的向量,以便于交给后面的神经网络处理。其实,Embedding还有更多应用场景,以及更多的实现方法,后面会慢慢谈到这些方法。Embedding可以看做是用低维稠密向量表示一个对象,可以是单词,可以是用户,可以是电影,可以是音乐,可以是商品等等。只要这个向量能够包含,或者表达所表示对象的特征,同时能够通过向量之间的距离反应对象之间的关系或者相似性,那么Embedding的作用就体现出来了。
Example
如下图所示,就是Embedding在自然语言处理当中,对单词Embedding的一种刻画:
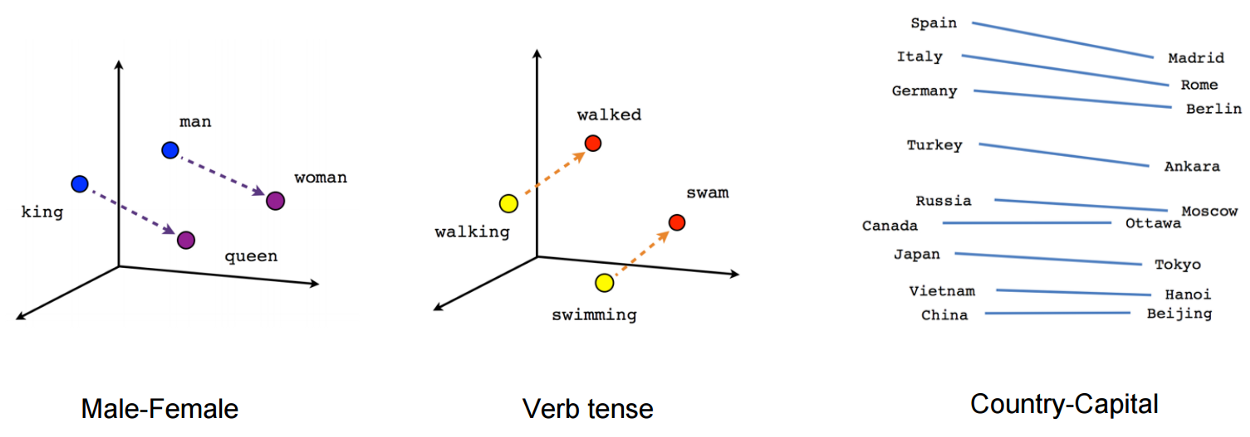
上图中从king到queen,与从man到woman的距离几乎相同,说明Embedding之间的向量运算能够包含词之间的语义关系信息,同理,图中的词性例子当中,从进行时态到过去时态也是相同的距离。Embedding可以在大量预料的输入前提下,发掘出一些通用的常识,比如首都-国家之间的关系。
通过这个例子,我们可以了解到,在词向量空间当中,即使是完全不知道一个词向量的含义下,仅依靠语义关系加词向量运算就可以推断出这个词的词向量。Embedding就这样从一个空间表达对象,同时还可以表示对象之间的关系。
应用
除了在自然语言处理中对单词进行Embedding之外,我们可以对物品进行Embedding。比如在影视作品推荐当中,“神探夏洛克”与“华生”在Embedding向量空间当中会比较近,“神探夏洛克”与“海绵宝宝”在向量空间中会比较远。另外,如果在电商推荐领域,“桌子”和“桌布”在向量空间中会比较紧,“桌子”和“滑雪板”在向量空间中会比较远。
不同领域在使用这些语义资料进行训练的时候也会有不同,比如电影推荐会将用户观看的电影进行Embedding,而电商会对用户购买历史进行Embedding。
Embedding in DeepRecSys
一般来说,推荐系统当中会大量使用Embedding操作:
- 使用one-hot对类别,id等类型进行编码会导致特征向量极其稀疏,使用Embedding可以将高维稀疏的特征向量转化为低维稠密的特征向量。
- Embedding具有很强的表达能力,在Graph Embedding提出之后,Embedding可以引入任何信息进行编码,包含大量有价值的信息。
- Embedding可以表达对象之间的关系,可以对物品、用户的相似度进行计算,在推荐系统的召回层经常使用,尤其是在局部敏感哈希(Locality-Sensitive Hashing)等快速最近邻搜索提出之后,Embedding被用来对物品进行快速筛选,到几百或几千的量级之后再进行神经网络的精排。
常见方法
- Word2Vec
- Item2Vec
- Node2Vec
等等方法,以及文中提到的局部敏感哈希,也会在后续的系列文章逐步更新介绍。
代码
我们看一下在PyTorch框架当中,深度学习里面的Embedding是怎么实现的。首先是官方给出的介绍
A simple lookup table that stores embeddings of a fixed dictionary and size. This module is often used to store word embeddings and retrieve them using indices. The input to the module is a list of indices, and the output is the corresponding word embeddings.
翻译一下就是
一个简单的查找表,存储固定字典和大小的嵌入。该模块通常用于存储词嵌入,并使用索引检索它们。该模块的输入是一个索引列表,输出是相应的词嵌入。
from typing import Optional
import torch
from torch import Tensor
from torch.nn.parameter import Parameter
from .module import Module
from .. import functional as F
from .. import init
class Embedding(Module):
r"""A simple lookup table that stores embeddings of a fixed dictionary and size.
This module is often used to store word embeddings and retrieve them using indices.
The input to the module is a list of indices, and the output is the corresponding
word embeddings.
Args:
num_embeddings (int): size of the dictionary of embeddings
embedding_dim (int): the size of each embedding vector
padding_idx (int, optional): If given, pads the output with the embedding vector at :attr:`padding_idx`
(initialized to zeros) whenever it encounters the index.
max_norm (float, optional): If given, each embedding vector with norm larger than :attr:`max_norm`
is renormalized to have norm :attr:`max_norm`.
norm_type (float, optional): The p of the p-norm to compute for the :attr:`max_norm` option. Default ``2``.
scale_grad_by_freq (boolean, optional): If given, this will scale gradients by the inverse of frequency of
the words in the mini-batch. Default ``False``.
sparse (bool, optional): If ``True``, gradient w.r.t. :attr:`weight` matrix will be a sparse tensor.
See Notes for more details regarding sparse gradients.
Attributes:
weight (Tensor): the learnable weights of the module of shape (num_embeddings, embedding_dim)
initialized from :math:`mathcal{N}(0, 1)`
Shape:
- Input: :math:`(*)`, LongTensor of arbitrary shape containing the indices to extract
- Output: :math:`(*, H)`, where `*` is the input shape and :math:`H= ext{embedding\_dim}`
.. note::
Keep in mind that only a limited number of optimizers support
sparse gradients: currently it's :class:`optim.SGD` (`CUDA` and `CPU`),
:class:`optim.SparseAdam` (`CUDA` and `CPU`) and :class:`optim.Adagrad` (`CPU`)
.. note::
With :attr:`padding_idx` set, the embedding vector at
:attr:`padding_idx` is initialized to all zeros. However, note that this
vector can be modified afterwards, e.g., using a customized
initialization method, and thus changing the vector used to pad the
output. The gradient for this vector from :class:`~torch.nn.Embedding`
is always zero.
Examples::
>>> # an Embedding module containing 10 tensors of size 3
>>> embedding = nn.Embedding(10, 3)
>>> # a batch of 2 samples of 4 indices each
>>> input = torch.LongTensor([[1,2,4,5],[4,3,2,9]])
>>> embedding(input)
tensor([[[-0.0251, -1.6902, 0.7172],
[-0.6431, 0.0748, 0.6969],
[ 1.4970, 1.3448, -0.9685],
[-0.3677, -2.7265, -0.1685]],
[[ 1.4970, 1.3448, -0.9685],
[ 0.4362, -0.4004, 0.9400],
[-0.6431, 0.0748, 0.6969],
[ 0.9124, -2.3616, 1.1151]]])
>>> # example with padding_idx
>>> embedding = nn.Embedding(10, 3, padding_idx=0)
>>> input = torch.LongTensor([[0,2,0,5]])
>>> embedding(input)
tensor([[[ 0.0000, 0.0000, 0.0000],
[ 0.1535, -2.0309, 0.9315],
[ 0.0000, 0.0000, 0.0000],
[-0.1655, 0.9897, 0.0635]]])
"""
__constants__ = ['num_embeddings', 'embedding_dim', 'padding_idx', 'max_norm',
'norm_type', 'scale_grad_by_freq', 'sparse']
num_embeddings: int
embedding_dim: int
padding_idx: int
max_norm: float
norm_type: float
scale_grad_by_freq: bool
weight: Tensor
sparse: bool
def __init__(self, num_embeddings: int, embedding_dim: int, padding_idx: Optional[int] = None,
max_norm: Optional[float] = None, norm_type: float = 2., scale_grad_by_freq: bool = False,
sparse: bool = False, _weight: Optional[Tensor] = None) -> None:
super(Embedding, self).__init__()
self.num_embeddings = num_embeddings
self.embedding_dim = embedding_dim
if padding_idx is not None:
if padding_idx > 0:
assert padding_idx < self.num_embeddings, 'Padding_idx must be within num_embeddings'
elif padding_idx < 0:
assert padding_idx >= -self.num_embeddings, 'Padding_idx must be within num_embeddings'
padding_idx = self.num_embeddings + padding_idx
self.padding_idx = padding_idx
self.max_norm = max_norm
self.norm_type = norm_type
self.scale_grad_by_freq = scale_grad_by_freq
if _weight is None:
self.weight = Parameter(torch.Tensor(num_embeddings, embedding_dim))
self.reset_parameters()
else:
assert list(_weight.shape) == [num_embeddings, embedding_dim],
'Shape of weight does not match num_embeddings and embedding_dim'
self.weight = Parameter(_weight)
self.sparse = sparse
def reset_parameters(self) -> None:
init.normal_(self.weight)
if self.padding_idx is not None:
with torch.no_grad():
self.weight[self.padding_idx].fill_(0)
def forward(self, input: Tensor) -> Tensor:
return F.embedding(
input, self.weight, self.padding_idx, self.max_norm,
self.norm_type, self.scale_grad_by_freq, self.sparse)
def extra_repr(self) -> str:
s = '{num_embeddings}, {embedding_dim}'
if self.padding_idx is not None:
s += ', padding_idx={padding_idx}'
if self.max_norm is not None:
s += ', max_norm={max_norm}'
if self.norm_type != 2:
s += ', norm_type={norm_type}'
if self.scale_grad_by_freq is not False:
s += ', scale_grad_by_freq={scale_grad_by_freq}'
if self.sparse is not False:
s += ', sparse=True'
return s.format(**self.__dict__)
@classmethod
def from_pretrained(cls, embeddings, freeze=True, padding_idx=None,
max_norm=None, norm_type=2., scale_grad_by_freq=False,
sparse=False):
r"""Creates Embedding instance from given 2-dimensional FloatTensor.
Args:
embeddings (Tensor): FloatTensor containing weights for the Embedding.
First dimension is being passed to Embedding as ``num_embeddings``, second as ``embedding_dim``.
freeze (boolean, optional): If ``True``, the tensor does not get updated in the learning process.
Equivalent to ``embedding.weight.requires_grad = False``. Default: ``True``
padding_idx (int, optional): See module initialization documentation.
max_norm (float, optional): See module initialization documentation.
norm_type (float, optional): See module initialization documentation. Default ``2``.
scale_grad_by_freq (boolean, optional): See module initialization documentation. Default ``False``.
sparse (bool, optional): See module initialization documentation.
Examples::
>>> # FloatTensor containing pretrained weights
>>> weight = torch.FloatTensor([[1, 2.3, 3], [4, 5.1, 6.3]])
>>> embedding = nn.Embedding.from_pretrained(weight)
>>> # Get embeddings for index 1
>>> input = torch.LongTensor([1])
>>> embedding(input)
tensor([[ 4.0000, 5.1000, 6.3000]])
"""
assert embeddings.dim() == 2,
'Embeddings parameter is expected to be 2-dimensional'
rows, cols = embeddings.shape
embedding = cls(
num_embeddings=rows,
embedding_dim=cols,
_weight=embeddings,
padding_idx=padding_idx,
max_norm=max_norm,
norm_type=norm_type,
scale_grad_by_freq=scale_grad_by_freq,
sparse=sparse)
embedding.weight.requires_grad = not freeze
return embedding
参考
Embedding in PyTorch
深度学习推荐系统 王喆编著
怎么形象理解embedding这个概念? - 刘斯坦的回答 - 知乎