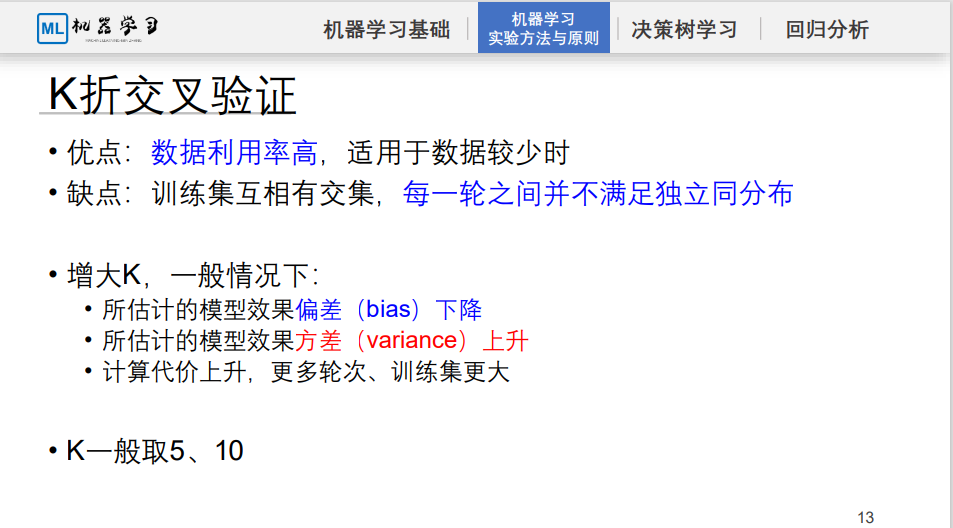
k折验证中k值对偏差和方差的影响?
总共n个数据,假设为2,每次训练集大小为n/2,每次训练的数据量会偏小,取平均值后,由于每次训练的数据量比较小,最终学习输出的模型会不能很好的代表样本的分布(欠拟合),换句话说就是偏差大。或者这么理解,由于k折交叉验证是使用k次训练的结果取平均值来进行预测的,如果只有两折交叉验证,每次对训练集的预测结果是使用一半的数据训练一半的数据预测,当数据集少时如果只针对本数据集预测,那么偏差会很小,但是该模型对两个不同的数据集进行了拟合,那么最后对同一个数据集的预测,一个会比较好,一个会比较差,平均以后的偏差就会比较大。相应的,由于拟合的不充分,方差就会比较小。
当k值很大时,假设为n折,那么每次训练集的大小为n-1,几乎等于原始数据集的大小了,可以更好地学习到样本的整体分布,这种情况下模型的偏差会偏小,但是方差偏大。可以这么理解,n折交叉验证那么训练数据就会有n份,每份之间的数据差异并不大,所以他们拟合出的平均值结果对训练数据集进行预测,偏差会比较小,但是由于对于给定的数据集充分地进行了学习,导致整体的方差会偏大。
对于同一模型同一置信度下的置信区间,一般测试集样本量越大,错误率的置信区间越小