zoukankan
html css js c++ java
Redis根据key查询时值中的中文乱码的问题
命令
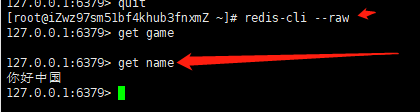
使用 ./redis-cli --raw 命令进入,即可查看正常中文
查看全文
相关阅读:
Ubuntu 出现 apt-get问题的解决方法
Conversion to Dalvik format failed: Unable to execute dex: null
java中判断是否为中文
解决:Unable to connect to repository https://dl-ssl.google.com/android/eclipse/site.xml
Android 获取本机WIFI及3G网络IP
xp重装系统后恢复Linux启动
Android中空格及换行
ubuntu12.10设置thunderbird开机自启动
web安全及防护
回归基础: JavaScript 变量提升
原文地址:https://www.cnblogs.com/nongzihong/p/15752933.html
最新文章
MySql数据库迁移图文展示
Udp广播的发送和接收(iOS + AsyncUdpSocket)下篇
Udp广播的发送与接收(C#+UdpClient) 上篇
关于SDWebImage加载高清图片导致app崩溃的问题
创建一个背景透明的UIViewController
PHP中文字符gbk编码与UTF-8编码的转换
javascript和php使用ajax通信传递JSON
分享关于js解析URL中的参数的方法
AptanaStudio3+PHP程序远程调试的方法和步骤
div布局小技巧
热门文章
[BZOJ2006][NOI2010]超级钢琴
[BZOJ2322][BeiJing2011]梦想封印
[BZOJ2638]黑白染色
[BZOJ3326][Scoi2013]数数
[BZOJ2178]圆的面积并
[BZOJ2655]calc
[BZOJ4920][Lydsy六月月赛]薄饼切割
[BZOJ1409]Password
Android开源框架ImageLoader的完美例子
tools/adb: No such file or directory
Copyright © 2011-2022 走看看